本文主要是介绍spark教程-Pyspark On Yarn 的模块依赖问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原理简述
Yarn 模式是把资源统一交给 Yarn 集群来管理,其优点在于实现了 application 的多样性,如 MapReduce 程序、HBase 集群、Storm 集群、spark 集群等;
Yarn 模式有两种运行模式:client 和 cluster,区别在于
client 模式的 Driver 运行在 client 端,而 client 端可能是 spark 集群内节点,也可以不是,一般来说不是集群内节点,这就需要在客户端节点上安装程序运行所需环境,以支持 spark 的正常执行;
cluster 模式的 Driver 运行在 spark 集群中的某个 NodeManager 上,而且不确定到底是哪个 NodeManager 上,这由 spark 的调度策略决定,
如果知道了在哪个节点,在该节点上安装程序运行所需环境即可,
但是事实是哪个节点都有可能,这意味着需要在所有节点上安装程序运行所需环境,显然这不是个好办法;
随着 application 的增加,需要不断安装新的包,而且不同 application 可能存在版本问题,这对于 client 模式来说或许还可以接受,但 cluster 模式肯定不行的,如果集群很大,装环境就会死人的
一句通俗的话描述 Pyspark On Yarn:Driver 从本地电脑获取环境后分发给 Container 来执行
问题复现
下面用一个小例子测试下 Yarn 的 模块依赖问题
主函数
from pyspark import SparkContext
from dependency.mydata import data # 自己写的模块sc = SparkContext(master='yarn', appName='yilai')
out = sc.parallelize(data)
out.saveAsTextFile('/spark/out')
自己写的模块 dependency/mydata.py,这个模块被主函数依赖
data = range(100)
运行结果
spark-submit --master yarn --deploy-mode client --py-files dep.zip mySparkCode.py # 可以执行 spark-submit --master yarn --deploy-mode cluster --py-files dep.zip mySparkCode.py # 可以执行,而且 关掉 client 可执行spark-submit --master yarn --deploy-mode client mySparkCode.py # 可以执行 spark-submit --master yarn --deploy-mode cluster mySparkCode.py # 不可以执行
--py-files 什么意思,我后面解释,它的作用就是把自写模块打包给 Driver;
在有 --py-files 的情况下,client 和 cluster 模式都可以执行,毕竟都打包上传了,可以理解;
在没有 --py-files 的情况下,client 模式可以运行,而且只要 dependency 放在 PYTHONPATH 的环境变量里,都可以运行,而 cluster 模式下不可执行;
原因解析
1. 被提交的任务放在 clien 端,被依赖的模块也在 client 端
2. client 模式下,Driver 运行在 client 上,Driver 可以找到被依赖的包,并发送给 Container
3. cluster 模式下,Driver 运行在 NodeManager 上,Driver 找不到被依赖的包,报错,Container exited with a non-zero exit code 13
而且经过我测试,自写模块存在链式依赖也可以执行,但是调用第三方模块如 numpy 就不行了 【site-packages 下的模块】
异常信息为
ImportError: No module named xxx
解决方案
模块依赖也可以分为多种情景:
有简单依赖,如单文件依赖,也有复杂依赖,如依赖多个文件,甚至 链式依赖,如代码依赖 padans,而 pandas 依赖 numpy
普通依赖
普通依赖有两种解决方法,当然这两种方法也可以解决部分 复杂依赖 问题,是通用的方法
--py-files
它是 spark-submit 的参数,官方解释如下
Comma-separated list of .zip, .egg, or .py files to place on the PYTHONPATH for Python apps. Comma,逗号;separated 分隔;
用逗号分隔的 zip、egg、py 文件列表来代替 PYTHONPATH 环境变量
如果依赖单个文件,直接写文件名即可,
spark-submit --master yarn --deploy-mode cluster --py-files xxx.py mySparkCode.py
如果是多个文件,用逗号隔开,
如果是一个包,需要进行压缩打包 【自己写的包】
[root@hadoop10 ~]# cd /usr/lib/python27/ [root@hadoop10 python27]# ls bin dependency include lib share [root@hadoop10 python27]# zip -r dep.zip dependency/adding: dependency/ (stored 0%)adding: dependency/__init__.py (stored 0%)adding: dependency/mydata.py (stored 0%)
效果如图
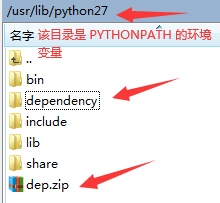
然后执行命令
spark-submit --master yarn --deploy-mode cluster --py-files /usr/lib/python27/dep.zip mySparkCode.py
注意,压缩文件必须是全路径,即使它在 PYTHONPATH 环境变量内,不写全路径也会报错 file do not exist
addPyFile
在代码内部解决问题,很简单,只需要一句
sc.addPyFile(file_path)
第三方依赖
以 numpy、pandas 为代表的第三方依赖比较麻烦,解决方案如下
1)创建 python 虚拟环境,并在虚拟环境中安装各种需要的包
参考我的博客 python 虚拟环境
值得注意的是,可能要使用 pip install --ignore-installed 来强行安装
2)压缩整个虚拟环境
注意是压缩整个环境,而不是被安装的包
[root@hadoop10 lib]# zip -r py.zip pyspark-ml-env/
pyspark-ml-env 是虚拟环境的目录
3)将虚拟环境压缩包上传 hdfs
[root@hadoop10 spark]# hadoop fs -put /usr/lib/py.zip /spark/env
4)以 numpy 为例,编写测试代码
import numpy as np
from pyspark import SparkContextsc = SparkContext(master='yarn', appName='test_use_numpy')
rdd = sc.parallelize(np.arange(100))
rdd.saveAsTextFile('/spark/numpy_test')
5)执行如下命令运行代码
注意是 cluster 模式,client 模式不用这么麻烦
spark-submit --master yarn --deploy-mode cluster --conf spark.yarn.dist.archives=hdfs:///spark/env/py.zip#pyenv --conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=pyenv/pyspark-ml-env/bin/python regression_metrics.py
spark.yarn.dist.archives:hdfs:///spark/env/py.zip 指定压缩文件地址,压缩文件被分发到 executor 上,并且解压,#pyenv 代表解压到的目录
spark.yarn.appMasterEnv.PYSPARK_PYTHON:指定使用的 python 环境;pyenv 即上面的解压目录,pyspark-ml-env 即创建的虚拟环境的目录
6)查看结果

运行正常
总结
下面我把 模块依赖 的使用问题进行一下总结
1. Driver 负责把本地的资源分发给 Container
2. 在 client 模式下,Driver 就找在 Client 端,可以把 client 端的资源分发,而 cluster 模式下,Driver 可在集群任一节点,该节点是没有资源的
3. 如果是 普通依赖:
在 client 模式下,Driver 可能自动收集资源,分发,无需上传依赖;
在 cluster 模式下,Driver 无法收集资源,必须上传依赖;
4. 如果是 复杂依赖:
在 client 模式 和 cluster 模式下,都需要通过 虚拟环境 上传依赖
5. 在工业环境中,使用的多是 cluster 模式,cluster 模式必须上传依赖
6. 在调试环节,多使用 client 模式,client 只需上传复杂依赖即可
参考资料:
https://blog.csdn.net/github_38358734/article/details/78292696 讲了点原理,作用不大
https://www.cnblogs.com/nucdy/p/8569606.html 和上个链接大同小异
https://blog.csdn.net/wangxiao7474/article/details/81391300 常规方法总结
https://zhuanlan.zhihu.com/p/43434216 知乎,说得挺详细,此篇是我唯一实验 numpy 等复杂依赖 成功的教程
https://www.cnblogs.com/piperck/p/10121097.html 这篇和上面 知乎 那篇雷同
https://www.jianshu.com/p/df0a189ff28b numpy 等复杂模块的解决方案
https://www.jianshu.com/p/0787b4641b23
下面的教程没啥用
https://www.jianshu.com/p/d77e16008957
https://stackoverflow.com/questions/45202045/running-python-in-yarn-spark-cluster-mode-using-virtualenv
这篇关于spark教程-Pyspark On Yarn 的模块依赖问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









