本文主要是介绍基于序列深度学习模型的向量海岸线形状分类方法 2024.05,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文中提出了一个数据驱动的方法来分类的形状矢量海岸线,该方法利用基于序列的深度学习算法对海岸线矢量分段进行建模和分类。具体而言,首先将复杂的海岸线划分为一系列弯曲,并进一步提出了一组不同的特征来描述每个弯曲的形态特征。然后,将每个弯道的形态特征及其序列整合到一个LSTM中,最终进行海岸线分类。
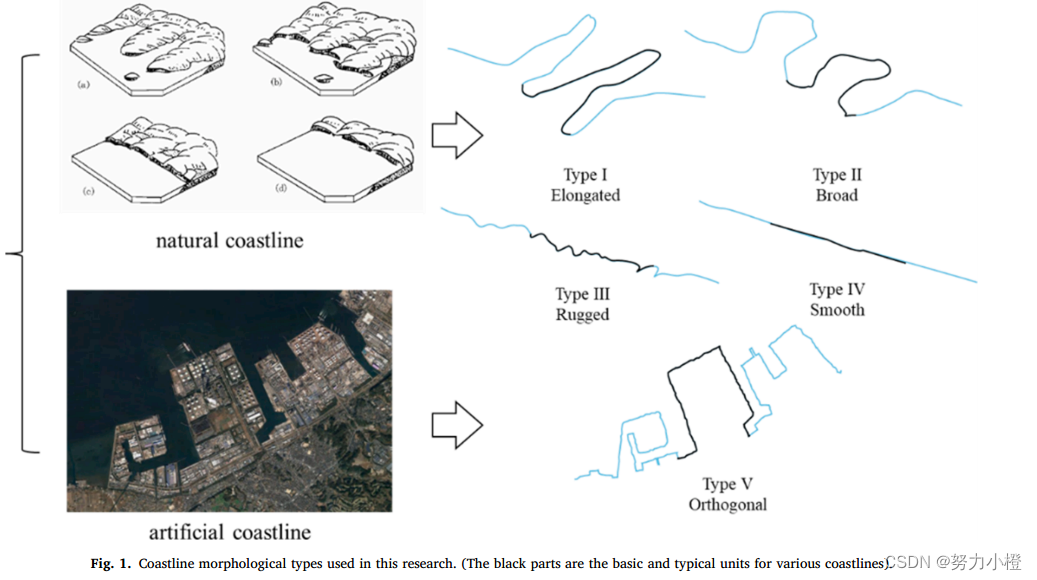 (五种海岸线)
(五种海岸线)
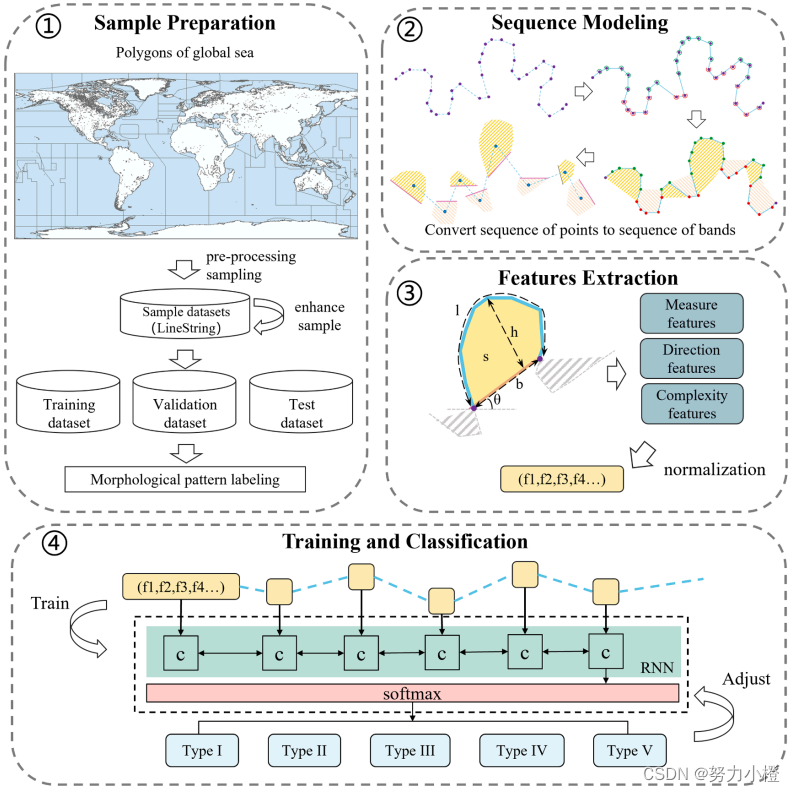
海岸线分段分类方法由以下几个部分组成:1)准备数据2)序列建模3)特征提取4)分类模型
序列建模:每个单独的海岸线段被划分为一个弯曲序列

海岸线的形状建模:全局方法(左)和本文提出的序列方法(右)。全局方法将海岸线视为一个整体,提取海岸线的总长度、平均全局曲率、全局包络面积、最小边界矩形等信息。相比之下,本工作中也采用了序列建模方法,首先将海岸线划分为几个子部分(即本工作中的弯曲)。然后对每个子部分进行单独分析,研究其形态特征。通过这样做,序列建模方法可以提供海岸线的详细分析,因此能够更准确地描述海岸线的形态特征。
海岸线建模两种方法:全局建模和局部/序列建模。
全球模拟方法通过全局特征提取。但在海岸线研究中并不常用,原因:1)由于海岸线通常是一条非常复杂的曲线,全局方程或数值模拟方法的计算成本高,结果分析复杂。2)由于全局特征是海岸线细节特征的集合,因此从全局特征中提取的形态信息太少,而集合会去除许多重要的细节。
本文建议将海岸线划分为一系列弯曲,然后分别分析其形态特征(图3)。
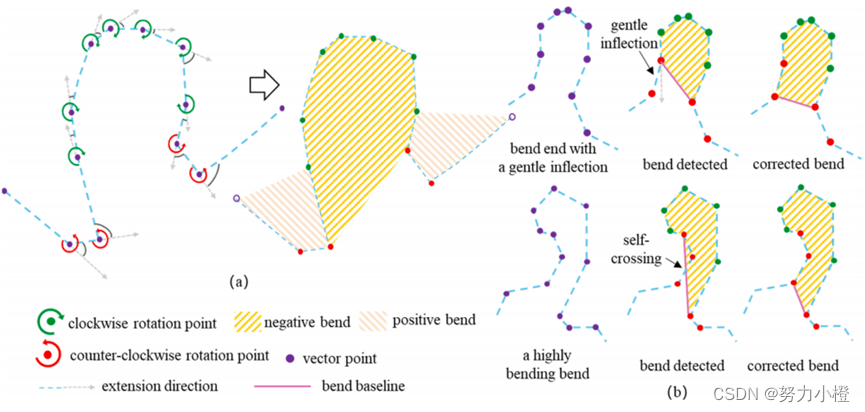
通过拐点分割算法可以将一条直线分割成一系列的弯曲,具体分割步骤如下:
(1)预处理:首先,对海岸线应用小阈值σ的Douglas-Peucker (DP)算法来简化其几何形状。这样做是为了去除重复的点和非常接近的点,允许所有的矢量海岸线在相同的比例上。在应用DP算法时,我们调整算法的容差参数σ,并监测样本端点所包围的面积。为了保证在DP处理过程中形状标签的稳定性,我们保证了应用DP算法前后的IoU保持在95%以上。
(2)点分类和弯曲检测:然后根据每个点是左转(逆时针)还是右转(顺时针)来确定除起点和终点外的每个点的方向。逆时针旋转的点标记为正角(图4a中标记为红色),顺时针旋转的点标记为负角(图4a中标记为绿色)。所有角度符号相同的连续点都被认为是一个弯道。
(3)弯道校正:如图4b所示,最初检测到的弯道需要进行一定的调整。一个高度弯曲的弯道,即一个弯道内所有顶点的弯曲总和太大,可能会使相邻的弯道与它们自己相交。移动端点以减小所有顶点的累计角度,直到两个相邻弯道的交点消失。对于一个平缓弯曲的弯,这意味着标志着弯道终点的弯曲很小,人们不会认为这是弯道的终点。只有当拐点角度较小,且新基线比旧基线短时,才应将端点向外移动。
使用上述方法,海岸线可以分割成一系列的弯曲。同时,这些弯道具有以下明显的特点:1)正弯道和负弯道总是相邻的。2)每个弯道与另一个相邻,覆盖了整个海岸线上的每个顶点。
特征
提出的每个弯曲的形态特征可以分为三组:大小相关,方向相关和复杂性相关的特征。很多关于曲线的特征,略

矢量海岸线形态分类模型
构建了一个矢量海岸线形态分类模型BendSeqLSTM。由于海岸线形状的顺序对称性,采用双向LSTM模型。首先,将海岸线分割为一系列弯曲X = (X1,X2,⋯X n),并将每个弯曲的所有形态特征描述为Xt,其中t是海岸线中弯曲的序数。然后将弯曲序列X输入到双向LSTM层,将其序列结构信息聚合到第一层的隐变量H[1]中。LSTM单元的数量等于海岸线上弯曲的数量。然后将H[1]输入到两个全连通层中,在全连通层中对LSTM提取的序列结构信息进行富集,得到H[L]。最后,集成一个SoftMax层来输出隐藏变量H[L]作为五种海岸线形态类(在第3.1节中提出)的概率Y。

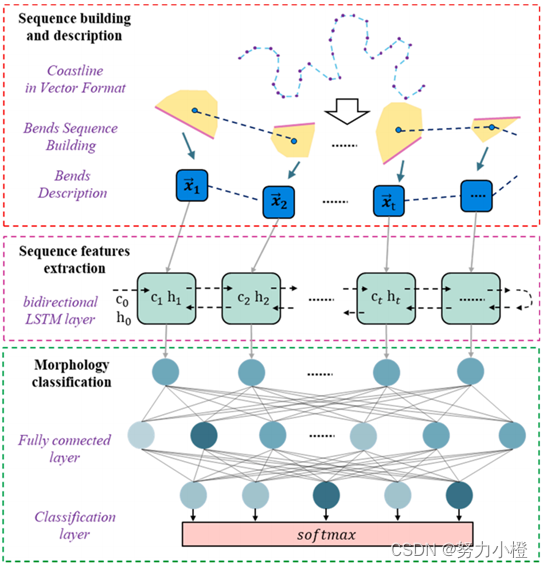
LSTM 层的长度设置为样本中的最大序列长度。短于此长度的样本将填充预定义的掩码值。在将数据馈送到 LSTM 层之前,应用掩码层进行预处理。每个 LSTM 单元都配置有 4 个内核。全连接层由 128 个单元组成。
结果
双向序列网络始终优于单向网络。因为海岸线的形态显然与输入的方向无关。利用双向序列网络消除了在计算模型中描绘海岸线形态时描述顺序的影响。此外,双向序列网络还有助于捕获更多的海岸线形态特征。
与基于弯曲构造的特征(如本研究)相比,基于点X和Y坐标的方法表现出较差的性能。我们将其归因于两个主要原因:首先,与弯曲序列相比,点序列的长度较长增加了梯度消失的问题。此外,与手工特征相比,仅从X和Y坐标自动提取高级特征的效率太低,表现为模型收敛困难。因此基于X点和Y点坐标的端到端方法在训练过程和分类精度方面存在明显的缺点。具有手工制作特征的基于向量的方法,如本文提出的方法,在数据灵活性、易于应用、模型可解释性、模型训练和迁移的成本效率以及整体性能方面具有更大的优势。
这篇关于基于序列深度学习模型的向量海岸线形状分类方法 2024.05的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




