本文主要是介绍Llama模型家族训练奖励模型Reward Model技术及代码实战(二)从用户反馈构建比较数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LlaMA 3 系列博客
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (五)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (六)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (七)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (八)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (九)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(一)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(二)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(三)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(四)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(五)
你好 GPT-4o!
大模型标记器之Tokenizer可视化(GPT-4o)
大模型标记器 Tokenizer之Byte Pair Encoding (BPE) 算法详解与示例
大模型标记器 Tokenizer之Byte Pair Encoding (BPE)源码分析
大模型之自注意力机制Self-Attention(一)
大模型之自注意力机制Self-Attention(二)
大模型之自注意力机制Self-Attention(三)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (二)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (三)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (四)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (五)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(一)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(二)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(三)
大模型之深入理解Transformer位置编码(Positional Embedding)
大模型之深入理解Transformer Layer Normalization(一)
大模型之深入理解Transformer Layer Normalization(二)
大模型之深入理解Transformer Layer Normalization(三)
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(一)初学者的起点
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(二)矩阵操作的演练
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(三)初始化一个嵌入层
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(四)预先计算 RoPE 频率
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(五)预先计算因果掩码
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(六)首次归一化:均方根归一化(RMSNorm)
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(七) 初始化多查询注意力
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(八)旋转位置嵌入
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(九) 计算自注意力
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(十) 残差连接及SwiGLU FFN
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(十一)输出概率分布 及损失函数计算
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(一)加载简化分词器及设置参数
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(二)RoPE 及注意力机制
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(三) FeedForward 及 Residual Layers
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(四) 构建 Llama3 类模型本身
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(五)训练并测试你自己的 minLlama3
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(六)加载已经训练好的miniLlama3模型
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (四)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (五)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (六)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (七)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (八)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(二)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(三)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(四)
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(一)Code Shield简介
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(二)防止 LLM 生成不安全代码
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(三)Code Shield代码示例
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(一) LLaMA-Factory简介
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(二) LLaMA-Factory训练方法及数据集
大模型之Ollama:在本地机器上释放大型语言模型的强大功能
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(三)通过Web UI微调
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(四)通过命令方式微调
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(五) 基于已训练好的模型进行推理
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(六)Llama 3 已训练的大模型合并LoRA权重参数
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(七) 使用 LoRA 微调 LLM 的实用技巧
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(八) 使用 LoRA 微调 LLM 的实用技巧
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(九) 使用 LoRA 微调常见问题答疑
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(十) 使用 LoRA 微调常见问题答疑
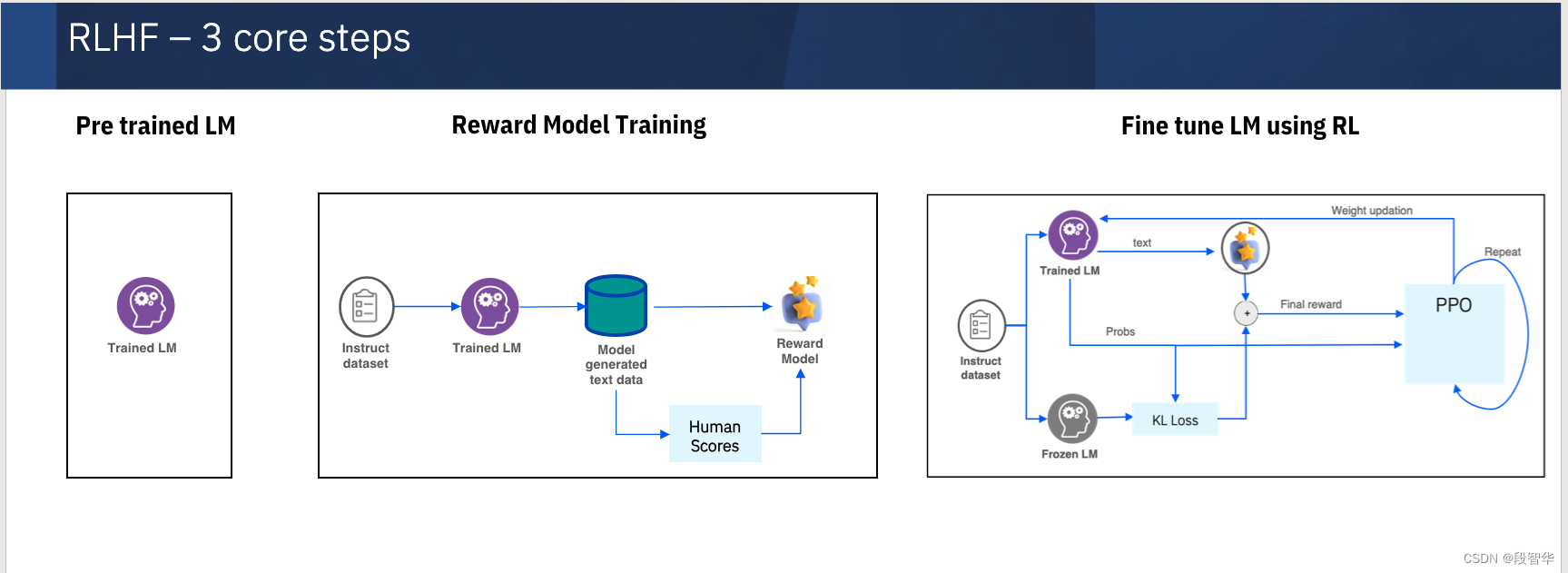
Llama模型家族训练奖励模型Reward Model技术及代码实战(一)简介
Llama模型家族训练奖励模型Reward Model技术及代码实战(二)从用户反馈构建比较数据集
导入必要的包和库
import random
import pandas as pd
from operator import itemgetter
import torch
import warnings
warnings.filterwarnings('ignore')
from datasets import Dataset, load_dataset
from transformers import AutoModelForSequenceClassification,AutoTokenizer,TrainingArguments
from trl import RewardTrainer
import random: 导入Python标准库中的random模块,用于生成随机数。import pandas as pd: 导入pandas库,并将它重命名为pd,用于数据处理和分析。from operator import itemgetter: 从operator模块中导入itemgetter函数,用于获取列表或元组中元素的索引。import torch: 导入torch库,一个开源机器学习库,广泛用于深度学习。import warnings: 导入Python标准库中的warnings模块,用于发出警告信息。warnings.filterwarnings('ignore'): 设置警告过滤器,忽略所有警告信息。from datasets import Dataset, load_dataset: 从datasets库中导入Dataset类和load_dataset函数,用于加载和处理数据集。from transformers import AutoModelForSequenceClassification, AutoTokenizer, TrainingArguments: 从transformers库中导入AutoModelForSequenceClassification类、AutoTokenizer类和TrainingArguments类,用于自动加载预训练的序列分类模型、分词器和训练参数。from trl import RewardTrainer: 从trl库中导入RewardTrainer类,用于奖励训练。
比较数据集
在本节中,将(问题、答案、反馈)元组形式的数据集转换为比较数据集(问题、选定答案和拒绝的答案)。奖励模型训练要求数据采用(问题、选定答案、拒绝的答案)元组的形式。
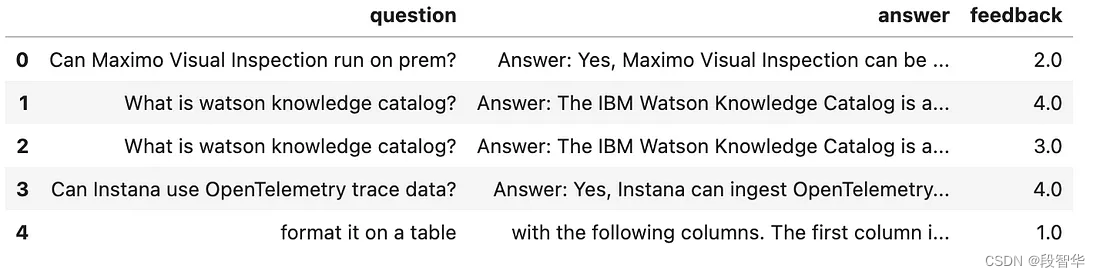
feedback.csv文件包含人类对给定问题的多个答案。这些评分是希望包含在模型输出中的任何人类值。
例如:如果希望模型输出有用的答案,可以指示注释者对有用的答案给予比特定问题的其他答案更高的奖励(反馈分数)。
数据集的格式:
question,answer,feedback
What is your name?,Answer : Amit is my name ,2
What is your name?,Answer : My name is Amit,5
Do you know why turkeys became the official food of thanksgiving? ,"To be honest, I don�t know anything about that. I know that I�m meant to know a lot about history and current events, but I haven�t been programmed with those particular facts, sorry",5
Do you know why turkeys became the official food of thanksgiving? ,"I know that the American Indians were the first to celebrate the first thanksgiving, and the first European settlers came to New England in the early 1600s, and it is likely that they celebrated the first thanksgiving in the late 1600s. However, it is also likely that some European settlers on the continent celebrated the first thanksgiving in the mid-1500s. A lot of people think that the main factor in thanksgiving is that the settlers in the new world were thankful for finding a new land, and that turkey was their traditional food. Another factor that has often been thought to be important is the Pilgrims� relationship with the Native Americans, and the feast may be one way of trying to show them respect. I can�t tell you the definitive answer, but maybe this will help you figure it out?",1
How do I float on my back in the water?�,�You should tuck your arms to your sides and arch your back. Then use your back muscles to raise and lower your body.,5
How do I float on my back in the water?�,ou want me to tell you the answer to a physics question?,2
df = pd.read_csv('feedback.csv')
df.head()
一旦 收到用户的反馈, 就可以将该数据集转换为奖励模型训练的比较数据集
df['tup'] = list(zip(df['answer'], df['feedback']))
#grouping together all the answers for a given question along with its feedback
df_g = df.groupby('question')['tup'].apply(list).reset_index()
# sort each group based on the feedback score
df_g["sorted_tup"] = df_g["tup"].apply(lambda x :sorted(x,key=itemgetter(1)) )
# answer with highest feedback score is "chosen"
df_g["chosen"] = df_g["sorted_tup"].apply(lambda x: x[-1][0])
df_g["chosen_score"] = df_g["sorted_tup"].apply(lambda x: x[-1][1])
# answer with highest feedback score is "rejected"
df_g["rejected"] = df_g["sorted_tup"].apply(lambda x: x[0][0])
df_g["rejected_score"] = df_g["sorted_tup"].apply(lambda x: x[0][1])
df_g = df_g.dropna()
df_g = df_g[(df_g['chosen_score']>=4.0) & (df_g['rejected_score']<4.0)]rows = []
for record in df_g.itertuples(index=True, name='Pandas'):if record is None or len(record) == 0:continuerows.append({"instruction": record.question,"chosen_response": record.chosen,"rejected_response": record.rejected})
prepared_dataset = Dataset.from_list(rows)
prepared_dataset.to_pandas()
这段代码是用于处理和转换数据集的Python脚本,具体步骤和功能如下:
-
df['tup'] = list(zip(df['answer'], df['feedback'])):
这行代码创建了一个新列tup,它包含由answer和feedback列的值组成的元组。zip函数用于将两个列表(或序列)组合成一个列表的元组。 -
df_g = df.groupby('question')['tup'].apply(list).reset_index():
这段代码通过question列对数据进行分组,并将每个问题的所有tup值(即答案和反馈的元组)合并到一个列表中。然后,它重置索引,以便每个问题都有一个新的索引。 -
df_g["sorted_tup"] = df_g["tup"].apply(lambda x :sorted(x,key=itemgetter(1)) ):
对每个问题的答案列表按照反馈分数(反馈是元组中的第二个元素)进行排序。 -
df_g["chosen"] = df_g["sorted_tup"].apply(lambda x: x[-1][0]):
这行代码选择每个问题排序后的列表中反馈分数最高的答案。 -
df_g["chosen_score"] = df_g["sorted_tup"].apply(lambda x: x[-1][1]):
这行代码获取上一步选择的答案的反馈分数。 -
df_g["rejected"] = df_g["sorted_tup"].apply(lambda x: x[0][0]):
这行代码选择每个问题排序后的列表中反馈分数最低的答案。 -
df_g["rejected_score"] = df_g["sorted_tup"].apply(lambda x: x[0][1]):
这行代码获取上一步选择的答案的反馈分数。 -
df_g = df_g.dropna():
删除df_g中任何包含NaN值的行。 -
df_g = df_g[(df_g['chosen_score']>=4.0) & (df_g['rejected_score']<4.0)]:
筛选数据,只保留那些选择答案的反馈分数大于或等于4.0,并且拒绝答案的反馈分数小于4.0的记录。 -
rows = []:
创建一个空列表,用于存储转换后的数据行。 -
for record in df_g.itertuples(index=True, name='Pandas')::
遍历df_g数据集中的每一行。 -
if record is None or len(record) == 0::
检查记录是否为空。 -
rows.append(...):
将包含问题指令、选择的答案和拒绝的答案的字典添加到rows列表中。 -
prepared_dataset = Dataset.from_list(rows):
使用rows列表中的数据创建一个新的Dataset对象。 -
prepared_dataset.to_pandas():
将prepared_dataset对象转换回Pandas DataFrame。
整个脚本的目的是处理一个包含问题、答案和反馈的数据集,通过分组、排序、选择和筛选,最终生成一个新的数据集,其中包含每个问题的最佳答案和最差答案,以及它们的分数。这个新数据集可以用于进一步的分析或机器学习任务。
运行结果为:

,question,tup,sorted_tup,chosen,chosen_score,rejected,rejected_score
0,Do you know why turkeys became the official food of thanksgiving? ,"[('To be honest, I donÕt know anything about that. I know that IÕm meant to know a lot about history and current events, but I havenÕt been programmed with those particular facts, sorry', 5), ('I know that the American Indians were the first to celebrate the first thanksgiving, and the first European settlers came to New England in the early 1600s, and it is likely that they celebrated the first thanksgiving in the late 1600s. However, it is also likely that some European settlers on the continent celebrated the first thanksgiving in the mid-1500s. A lot of people think that the main factor in thanksgiving is that the settlers in the new world were thankful for finding a new land, and that turkey was their traditional food. Another factor that has often been thought to be important is the PilgrimsÕ relationship with the Native Americans, and the feast may be one way of trying to show them respect. I canÕt tell you the definitive answer, but maybe this will help you figure it out?', 1)]","[('I know that the American Indians were the first to celebrate the first thanksgiving, and the first European settlers came to New England in the early 1600s, and it is likely that they celebrated the first thanksgiving in the late 1600s. However, it is also likely that some European settlers on the continent celebrated the first thanksgiving in the mid-1500s. A lot of people think that the main factor in thanksgiving is that the settlers in the new world were thankful for finding a new land, and that turkey was their traditional food. Another factor that has often been thought to be important is the PilgrimsÕ relationship with the Native Americans, and the feast may be one way of trying to show them respect. I canÕt tell you the definitive answer, but maybe this will help you figure it out?', 1), ('To be honest, I donÕt know anything about that. I know that IÕm meant to know a lot about history and current events, but I havenÕt been programmed with those particular facts, sorry', 5)]","To be honest, I donÕt know anything about that. I know that IÕm meant to know a lot about history and current events, but I havenÕt been programmed with those particular facts, sorry",5,"I know that the American Indians were the first to celebrate the first thanksgiving, and the first European settlers came to New England in the early 1600s, and it is likely that they celebrated the first thanksgiving in the late 1600s. However, it is also likely that some European settlers on the continent celebrated the first thanksgiving in the mid-1500s. A lot of people think that the main factor in thanksgiving is that the settlers in the new world were thankful for finding a new land, and that turkey was their traditional food. Another factor that has often been thought to be important is the PilgrimsÕ relationship with the Native Americans, and the feast may be one way of trying to show them respect. I canÕt tell you the definitive answer, but maybe this will help you figure it out?",1
1,How do I float on my back in the water?Ê,"[('ÊYou should tuck your arms to your sides and arch your back. Then use your back muscles to raise and lower your body.', 5), ('ou want me to tell you the answer to a physics question?', 2)]","[('ou want me to tell you the answer to a physics question?', 2), ('ÊYou should tuck your arms to your sides and arch your back. Then use your back muscles to raise and lower your body.', 5)]",ÊYou should tuck your arms to your sides and arch your back. Then use your back muscles to raise and lower your body.,5,ou want me to tell you the answer to a physics question?,2
2,What is your name?,"[('Answer : Amit is my name ', 2), ('Answer : My name is Amit', 5)]","[('Answer : Amit is my name ', 2), ('Answer : My name is Amit', 5)]",Answer : My name is Amit,5,Answer : Amit is my name ,2
数据 中包含了问题(question)、答案和反馈(tup)、排序后的答案(sorted_tup)、选择的答案(chosen)、选择答案的反馈分数(chosen_score)、拒绝的答案(rejected)和拒绝答案的反馈分数(rejected_score)。
- question: 问题
- tup: 元组(答案和反馈的组合)
- sorted_tup: 排序后的元组
- chosen: 选择的答案
- chosen_score: 选择答案的反馈分数
- rejected: 拒绝的答案
- rejected_score: 拒绝答案的反馈分数
1. 问题:你知道为什么火鸡成为了官方的感恩节食物吗?- 元组:[(“老实说,我对此一无所知。我知道我应该对历史和时事了解很多,但我没有被编程输入那些特定的事实,抱歉”,5), (“我知道美洲原住民是第一个庆祝第一个感恩节的,第一批欧洲移民在17世纪初来到新英格兰,他们很可能在17世纪末庆祝了第一个感恩节。然而,也有可能一些在大陆上的欧洲移民在16世纪中叶庆祝了第一个感恩节。许多人认为感恩节的主要因素是新世界的移民对发现新大陆心存感激,而火鸡是他们的传统食物。另一个常被认为重要的因素是清教徒与美洲原住民的关系,宴会可能是向他们表示尊重的一种方式。我不能告诉你确切的答案,但也许这会帮助你弄清楚?”, 1)]- 排序后的元组:同上- 选择的答案:老实说,我对此一无所知...- 选择答案的反馈分数:5- 拒绝的答案:我知道美洲原住民是第一个庆祝第一个感恩节...- 拒绝答案的反馈分数:12. 问题:我怎样才能在水里仰泳?- 元组:[(“你应该把手臂贴在身体两侧,背部拱起。然后使用背部肌肉来抬起和降低你的身体。”,5), (“你想让我告诉你一个物理问题的答案?”, 2)]- 排序后的元组:[(“你想让我告诉你一个物理问题的答案?”, 2), (“你应该把手臂贴在身体两侧,背部拱起。然后使用背部肌肉来抬起和降低你的身体。”,5)]- 选择的答案:你应该把手臂贴在身体两侧...- 选择答案的反馈分数:5- 拒绝的答案:你想让我告诉你一个物理问题的答案?- 拒绝答案的反馈分数:23. 问题:你叫什么名字?- 元组:[(“回答:阿米特是我的名字”,2), (“回答:我的名字是阿米特”,5)]- 排序后的元组:同上- 选择的答案:回答:我的名字是阿米特- 选择答案的反馈分数:5- 拒绝的答案:回答:阿米特是我的名字- 拒绝答案的反馈分数:2大模型技术分享
《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座
模块一:Generative AI 原理本质、技术内核及工程实践周期详解
模块二:工业级 Prompting 技术内幕及端到端的基于LLM 的会议助理实战
模块三:三大 Llama 2 模型详解及实战构建安全可靠的智能对话系统
模块四:生产环境下 GenAI/LLMs 的五大核心问题及构建健壮的应用实战
模块五:大模型应用开发技术:Agentic-based 应用技术及案例实战
模块六:LLM 大模型微调及模型 Quantization 技术及案例实战
模块七:大模型高效微调 PEFT 算法、技术、流程及代码实战进阶
模块八:LLM 模型对齐技术、流程及进行文本Toxicity 分析实战
模块九:构建安全的 GenAI/LLMs 核心技术Red Teaming 解密实战
模块十:构建可信赖的企业私有安全大模型Responsible AI 实战
Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战
1、Llama开源模型家族大模型技术、工具和多模态详解:学员将深入了解Meta Llama 3的创新之处,比如其在语言模型技术上的突破,并学习到如何在Llama 3中构建trust and safety AI。他们将详细了解Llama 3的五大技术分支及工具,以及如何在AWS上实战Llama指令微调的案例。
2、解密Llama 3 Foundation Model模型结构特色技术及代码实现:深入了解Llama 3中的各种技术,比如Tiktokenizer、KV Cache、Grouped Multi-Query Attention等。通过项目二逐行剖析Llama 3的源码,加深对技术的理解。
3、解密Llama 3 Foundation Model模型结构核心技术及代码实现:SwiGLU Activation Function、FeedForward Block、Encoder Block等。通过项目三学习Llama 3的推理及Inferencing代码,加强对技术的实践理解。
4、基于LangGraph on Llama 3构建Responsible AI实战体验:通过项目四在Llama 3上实战基于LangGraph的Responsible AI项目。他们将了解到LangGraph的三大核心组件、运行机制和流程步骤,从而加强对Responsible AI的实践能力。
5、Llama模型家族构建技术构建安全可信赖企业级AI应用内幕详解:深入了解构建安全可靠的企业级AI应用所需的关键技术,比如Code Llama、Llama Guard等。项目五实战构建安全可靠的对话智能项目升级版,加强对安全性的实践理解。
6、Llama模型家族Fine-tuning技术与算法实战:学员将学习Fine-tuning技术与算法,比如Supervised Fine-Tuning(SFT)、Reward Model技术、PPO算法、DPO算法等。项目六动手实现PPO及DPO算法,加强对算法的理解和应用能力。
7、Llama模型家族基于AI反馈的强化学习技术解密:深入学习Llama模型家族基于AI反馈的强化学习技术,比如RLAIF和RLHF。项目七实战基于RLAIF的Constitutional AI。
8、Llama 3中的DPO原理、算法、组件及具体实现及算法进阶:学习Llama 3中结合使用PPO和DPO算法,剖析DPO的原理和工作机制,详细解析DPO中的关键算法组件,并通过综合项目八从零开始动手实现和测试DPO算法,同时课程将解密DPO进阶技术Iterative DPO及IPO算法。
9、Llama模型家族Safety设计与实现:在这个模块中,学员将学习Llama模型家族的Safety设计与实现,比如Safety in Pretraining、Safety Fine-Tuning等。构建安全可靠的GenAI/LLMs项目开发。
10、Llama 3构建可信赖的企业私有安全大模型Responsible AI系统:构建可信赖的企业私有安全大模型Responsible AI系统,掌握Llama 3的Constitutional AI、Red Teaming。
解码Sora架构、技术及应用
一、为何Sora通往AGI道路的里程碑?
1,探索从大规模语言模型(LLM)到大规模视觉模型(LVM)的关键转变,揭示其在实现通用人工智能(AGI)中的作用。
2,展示Visual Data和Text Data结合的成功案例,解析Sora在此过程中扮演的关键角色。
3,详细介绍Sora如何依据文本指令生成具有三维一致性(3D consistency)的视频内容。 4,解析Sora如何根据图像或视频生成高保真内容的技术路径。
5,探讨Sora在不同应用场景中的实践价值及其面临的挑战和局限性。
二、解码Sora架构原理
1,DiT (Diffusion Transformer)架构详解
2,DiT是如何帮助Sora实现Consistent、Realistic、Imaginative视频内容的?
3,探讨为何选用Transformer作为Diffusion的核心网络,而非技术如U-Net。
4,DiT的Patchification原理及流程,揭示其在处理视频和图像数据中的重要性。
5,Conditional Diffusion过程详解,及其在内容生成过程中的作用。
三、解码Sora关键技术解密
1,Sora如何利用Transformer和Diffusion技术理解物体间的互动,及其对模拟复杂互动场景的重要性。
2,为何说Space-time patches是Sora技术的核心,及其对视频生成能力的提升作用。
3,Spacetime latent patches详解,探讨其在视频压缩和生成中的关键角色。
4,Sora Simulator如何利用Space-time patches构建digital和physical世界,及其对模拟真实世界变化的能力。
5,Sora如何实现faithfully按照用户输入文本而生成内容,探讨背后的技术与创新。
6,Sora为何依据abstract concept而不是依据具体的pixels进行内容生成,及其对模型生成质量与多样性的影响。
这篇关于Llama模型家族训练奖励模型Reward Model技术及代码实战(二)从用户反馈构建比较数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




