本文主要是介绍【AI大模型】这可能是最简单的本地大模型工具,无须部署,一键使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
LM-Studio编辑
那么问题来了,为什么我要在本地部署大模型?
隐私性:
定制性:
成本和体验的优化:
工具功能特点和使用方式介绍:
首页提供搜索功能和一些模型的推荐
模型下载管理:
聊天界面:编辑
模型偏好设置
使用速度体验:
前言
不需要配置环境,不需要部署,不需要自己找模型。小白也可以打开即用的本地大模型使用工具来了,下面就谈一谈我的使用感受和心得:
LM-Studio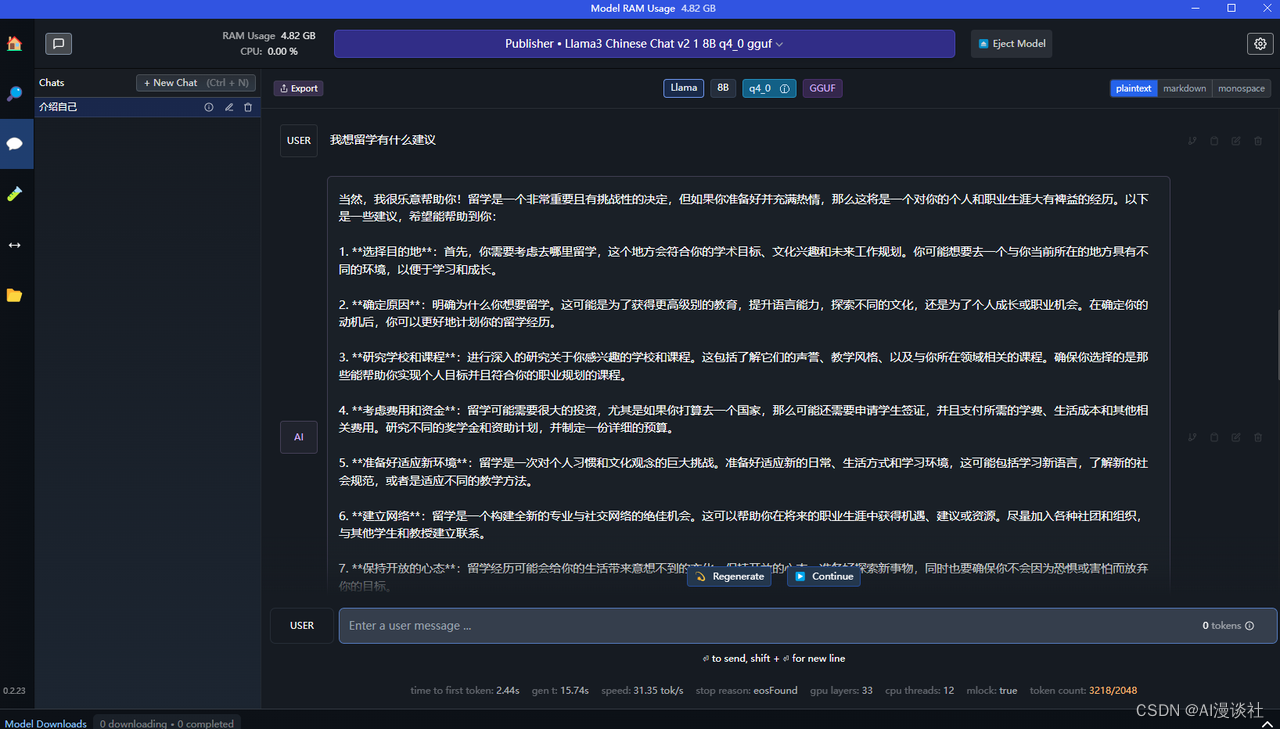
那么问题来了,为什么我要在本地部署大模型?
个人使用下来,最吸引我的有这三点:
-
隐私性:
网络大模型你的输入都是要上传的云端的,也就是你的隐私肯定会被大模型服务商所获得,这也是为什么那么多公司内部禁止使用网络大模型的原因。而且由于安全和审核机制,你所需要的或者发送的敏感的内容会被屏蔽。但是本地部署,数据完全由自己掌握。
-
定制性:
目前大部分免费使用的大模型都是通用模型,就那几种,虽然可以通过提示词约束,但是内容生成大部分时候只是差强人意。本地部署,你将拥有整个开源世界的微调模型,医疗,法律,学术,动漫,感情,你即使不去定制自己的模型,也将拥有专业的各领域专家来帮你解决你能想到的大部分问题。更不必说定制自己的专属模型的可能性。
-
成本和体验的优化:
首先承认大部分开源模型的上限是没有闭源模型高的,但是很多时候闭源模型的响应感受会受到网络,当前访问人数的限制。除非你愿意开会员,即使你愿意开会员,目前除了gpt-4o。大部门模型的响应是一个字一个字往外蹦的,尤其某些厂商做的恶心限制,离开网页就停止输出(某一言)如果你本地有一个还行的显卡,你会感受到原来大模型回答原来可以很迅速。
工具功能特点和使用方式介绍:
下载即exe,安装后即可使用,本体不到500m(提供mac和linux版本)


首页提供搜索功能和一些模型的推荐
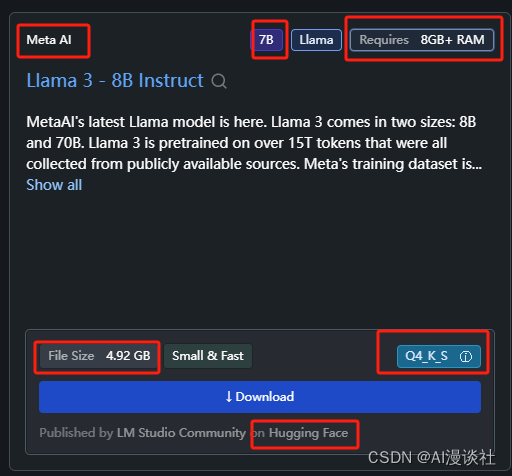
你可以直接搜索并下载开源世界的大模型(目前看基本上huggingface,需要梯子)并下载使用,推荐模型会给出介绍。如他的来源是什么,他是多少参数的大模型,什么功能,是否经过量化处理,本地运行至少需求多少内存,占用多少硬盘空间。
模型下载管理:
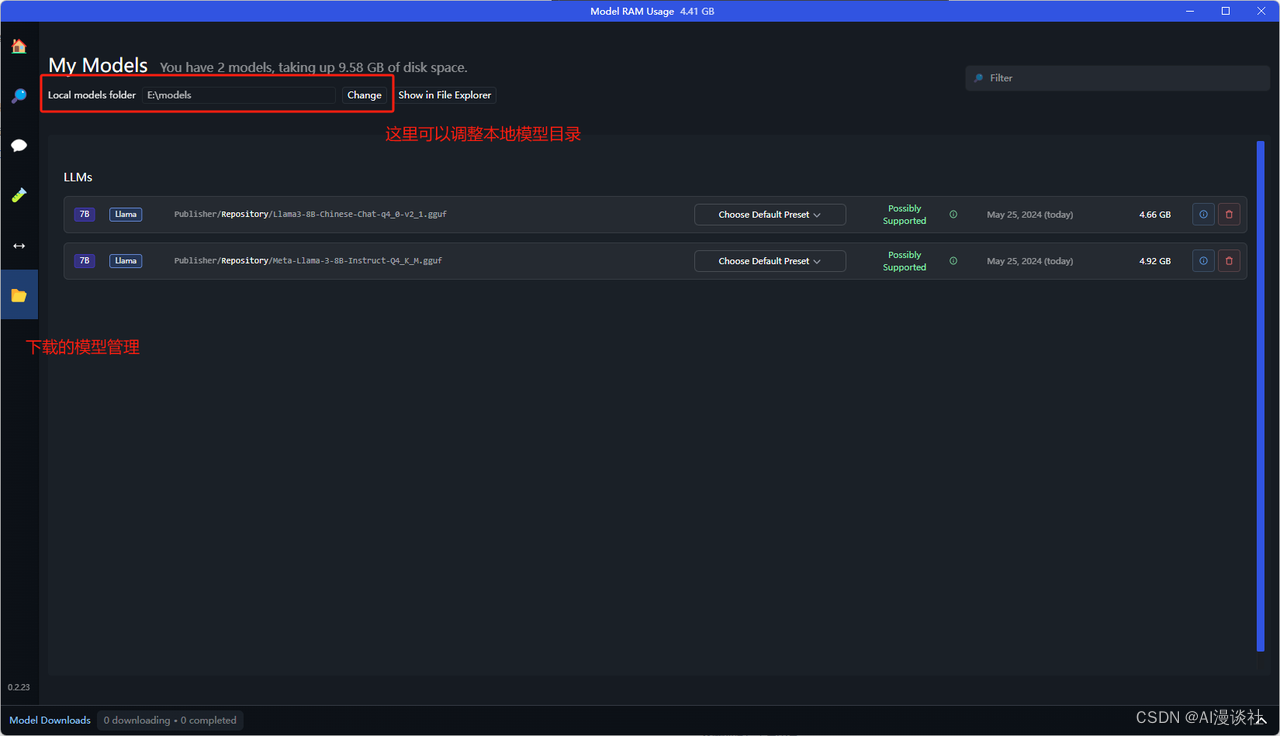
注意!无论设置什么目录,模型目录必须有如下层级结构,否则会找不到模型:

聊天界面: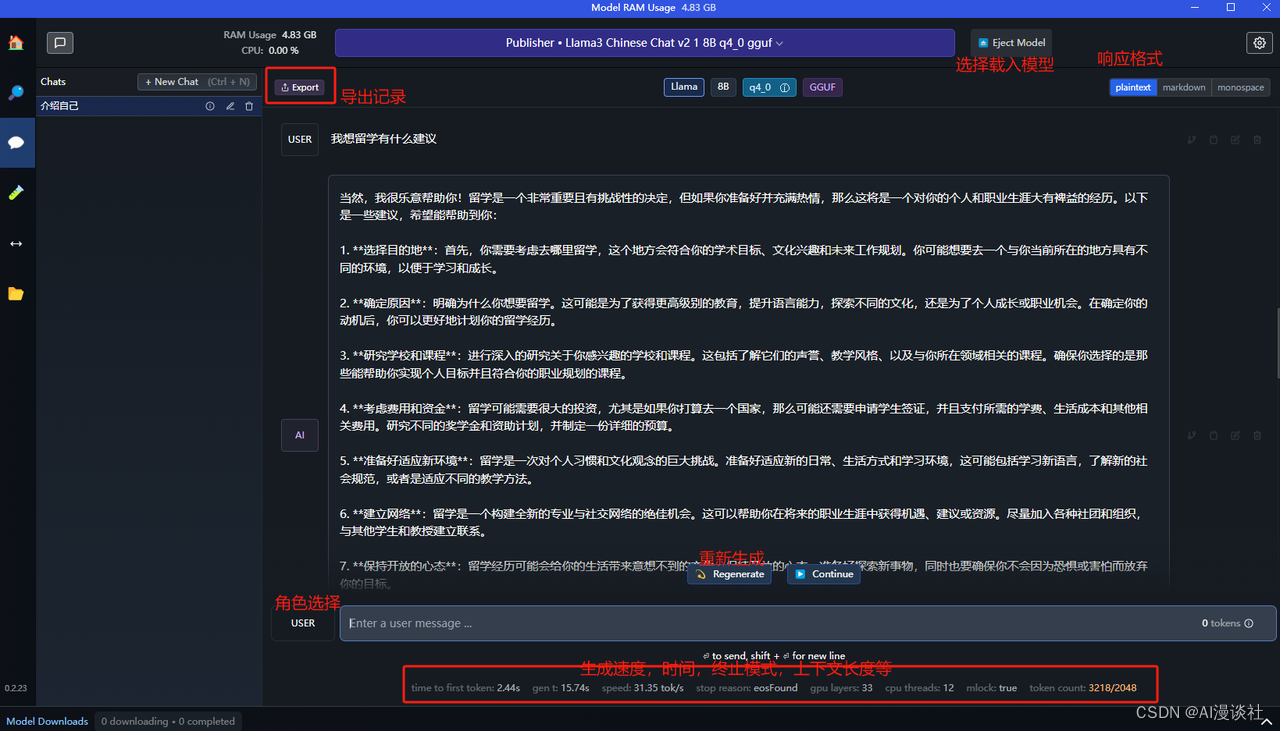
模型偏好设置
在聊天界面右上角有个设置功能,可以帮助我们更好的个性化使用,我会给出一些比较常用的参数设置解释
-
模型初始化角色配置
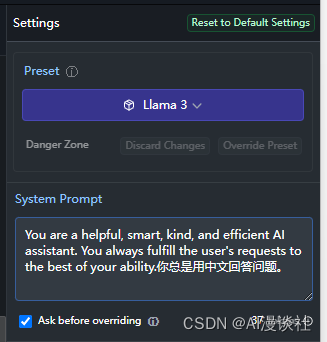
Preset 可以选择不同模型的初始化设置,你也可以设置自定义的模型使用配置,包括不限于,系统角色初始化提示词(system prompt),回答的随机程度,系统使用内存和显存的占比等。
-
模型回答内容控制:
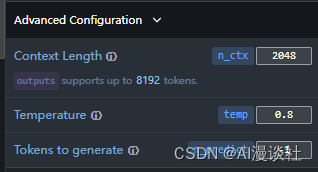
设置模型记忆上下文长度(content length),采样温度(temperature)介于 0 和 1 之间。较高的值(如 0.7)将使输出更加随机,而较低的值(如 0.2)将使其更加集中和确定性,最大生成内容长度(tokens to generate),默认-1由大模型决定生成长度。
-
模型内容质量控制

Top k : 模型回复时所考虑的回复质量占总体回复的质量比例,总体来说比例越高,回答的质量越高,效果也越单一。
Repeat penalty: 模型重复惩罚,越高模型回答的内容重复性越低
CPU threads: 占用线程。经过尝试,增加占用线程对模型响应速度有少量提升,效果不明显。
-
显存内存使用占比:
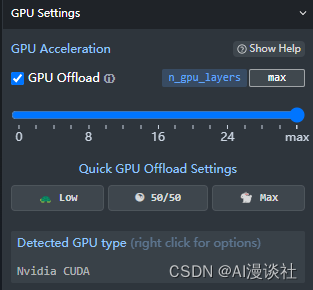
没什么可说的,显存能撑住的情况下,拉到最大,内存的速度比显存慢多了。
使用速度体验:
2060 8g 显卡,7B Q4量化模型(基于llama3 微调的中文模型)。生成token速度为31t/s左右(比大部分网络模型响应快一倍左右),感受还是很不错的,如果完全不使用显存只使用内存,速度约5t/s 只能说能用。
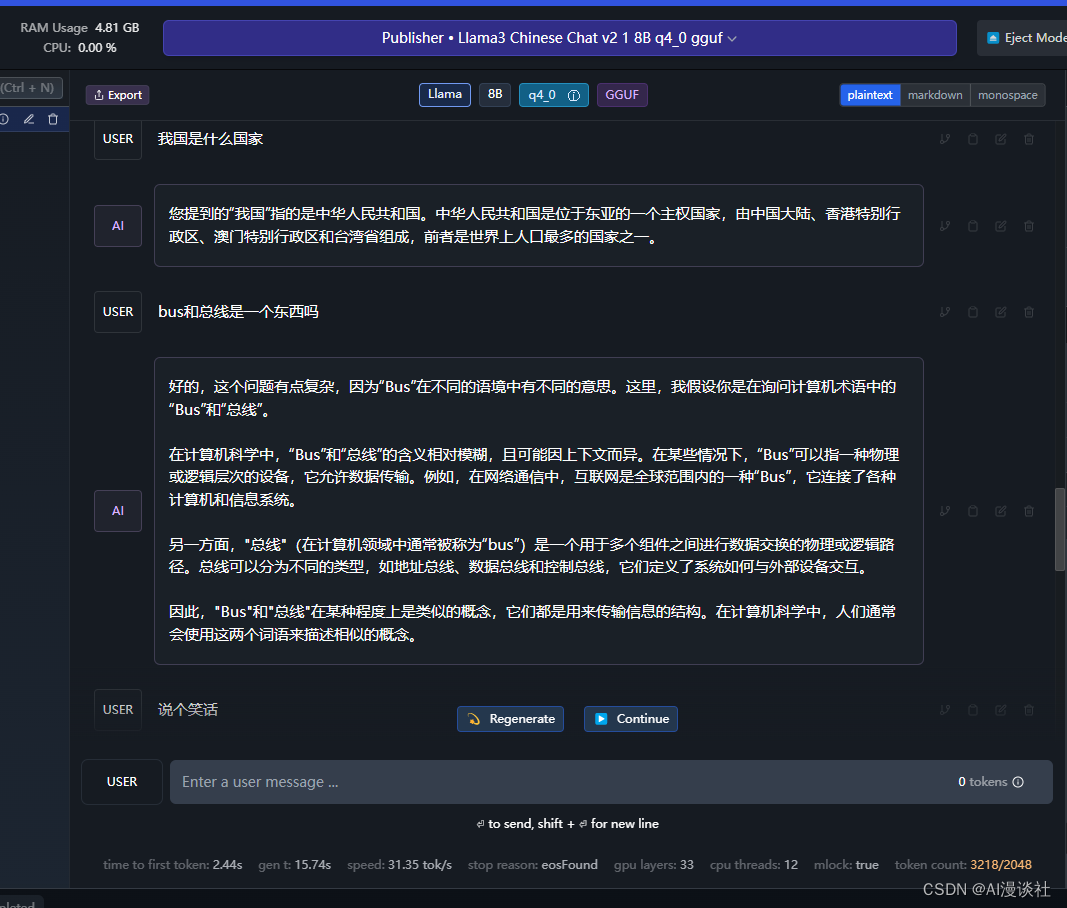
kimi效果:
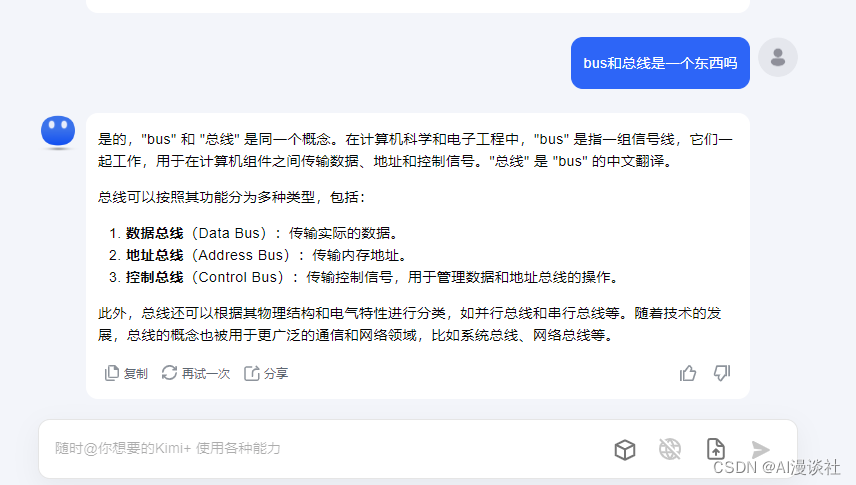
这个软件可以直接搜索官网mstudio.ai下载。
无法下载模型的小伙伴我也在我的公众号中打包了,我所使用的中文llama3模型(Llama3-8B-Chinese-Chat-q4_0-v2_1,和原始英文模型下载(Meta-Llama-3-8B-Instruct-Q4_K_M)已经软件的整合包下载。
后台回复 LmStudio 即可 !每天还有更多教程和AI资讯分享!
——因为热爱的AI漫谈社
这篇关于【AI大模型】这可能是最简单的本地大模型工具,无须部署,一键使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






