本文主要是介绍YOLOv3实践darknet跑voc数据集的问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在用YOLOv3的darknet训练VOC数据集,初学小白的我对参数,源码还在了解层面,但是结果已经训练开始之后发现IoU出现了nan值循环。所以就开始网上寻找。总结在下:
参考:https://blog.csdn.net/lilai619/article/details/79695109#commentsedit
如何训练自己的数据
说明:
(1)平台 linux + 作者官方代码 【训练指令请参考官网教程:https://pjreddie.com/darknet/yolo】
迭代:900 次
速度:稍微慢于v2
测试:记得更改cfg文件
训练自己的数据主要分以下几步:
(0)数据集制作:
A.制作VOC格式的xml文件
工具:LabelImg
B.将VOC格式的xml文件转换成YOLO格式的txt文件
脚本:voc_label.py,根据自己的数据集修改就行了。
(1)文件修改:
(A)关于 .data .names 两个文件修改非常简单,参考官网YOLOv3.txt连接中的文件。
(B)关于cfg修改,voc数据集是20类,coco是80类。#表示注释,根据训练和测试,自行修改。
[net]
#Testing
#batch=1
#subdivisions=1
#Training
batch=60###64 这里是我自己修改的,最好还是2的幂次方!
subdivisions=20###8
…
[convolutional]
size=1
stride=1
pad=1
filters=33###75
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=6###20
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0###1
…
[convolutional]
size=1
stride=1
pad=1
filters=33###75
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=6###20
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0###1
…
[convolutional]
size=1
stride=1
pad=1
filters=33###75
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=6###20
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0###1
-
A.filters数目是怎么计算的:3x(classes数目+5),和聚类数目分布有关,论文中有说明;
-
B.如果想修改默认anchors数值,使用k-means即可;
-
C.如果显存很小,将random设置为0,即关闭多尺度训练;
Region xx: cfg文件中yolo-layer的索引;
Avg IOU: 当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
Class: 标注物体的分类准确率,越大越好,期望数值为1;
obj: 越大越好,期望数值为1;
No obj: 越小越好;
.5R: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
0.75R: 以IOU=0.75为阈值时候的recall;
count: 正样本数目。
训练问题详解

Tips0: 数据集问题
如果是学习如何训练,建议不要用VOC或者COCO,这两个数据集复杂,类别较多,复现作者的效果需要一定的功力,迭代差不多5w次,就可以看到初步的效果。所以,不如挑个简单数据集的或者手动标注个几百张就可以进行训练学习。(我也是醉了,早知道就不用1070来练5w多次了。。。)
Tips1: CUDA: out of memory 以及 resizing 问题
显存不够,调小batch,关闭多尺度训练:random = 0。
Tips2: 在迭代前期,loss很大,正常吗?
经过几个数据集的测试,前期loss偏大是正常的,后面就很快收敛了。
Tips3: YOLOV3中的mask作用?
参考#558 #567
Every layer has to know about all of the anchor boxes but is only predicting some subset of them. This could probably be named something better but the mask tells the layer which of the bounding boxes it is responsible for predicting. The first yolo layer predicts 6,7,8 because those are the largest boxes and it’s at the coarsest scale. The 2nd yolo layer predicts some smallers ones, etc.
The layer assumes if it isn’t passed a mask that it is responsible for all the bounding boxes, hence the ifstatement thing.
Tips4: YOLOV3中的num作用?
#参考567
num is 9 but each yolo layer is only actually looking at 3 (that’s what the mask thing does). so it’s (20+1+4)*3 = 75. If you use a different number of anchors you have to figure out which layer you want to predict which anchors and the number of filters will depend on that distribution.
according to paper, each yolo (detection) layer get 3 anchors with associated with its size, mask is selected anchor indices.
Tips5: YOLOV3训练出现nan的问题?
参考#566
You must be training on a lot of small objects! nan’s appear when there are no objects in a batch of images since i definitely divide by zero. For example, Avg IOU is the sum of IOUs for all objects at that level / # of objects, if that is zero you get nan. I could probably change this so it just does a check for zero 1st, just wasn’t a priority.
所以在显存允许的情况下,可适当增加batch大小,可以一定程度上减少NAN的出现。
Tips6: YOLOv3打印的参数都是什么含义?
详见yolo_layer.c文件的forward_yolo_layer函数。
printf(“Region %d Avg IOU: %f, Class: %f, Obj: %f, No Obj: %f, .5R:
%f, .75R: %f, count: %d\n”, net.index, avg_iou/count,
avg_cat/class_count, avg_obj/count, avg_anyobj/(l.wl.hl.n*l.batch),
recall/count, recall75/count, count);
刚开始迭代,由于没有预测出相应的目标,所以查全率较低【.5R 0.75R】,会出现大面积为0的情况,这个是正常的。
测试问题
(1) Error in `./darknet’: free(): invalid next size (fast): 0x000055d39b90cbb0 *已放弃 (核心已转储)
请使用以下测试指令!
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
训练与测试指令,请参考官网连接:https://pjreddie.com/darknet/yolo/
(2)如何进行模型的评估(valid)?
评估指令,请参考官网连接:https://pjreddie.com/darknet/yolo/
(3)bounding box正确,标签错乱,这里提供两种方案供选择。
A.不改源码,不用重新编译
修改coco.names中内容,为自己的检测目标类别
B.改源码,需要重新编译[ 先 make clean ,然后再 make]
原因是作者在代码中设置了默认,所以修改 examples/darknet.c文件,将箭头指示的文件替换成自己的。然后重新编译即可。

我发现自己的data文件还是coco的,但我训练的是voc的数据,所以这里忘记改了。。。估计这个也是导致错误的一个问题
(4)模型保存问题
A:保存模型出错?
一般是 .data 文件中指定的文件夹无法创建,导致模型保存时出错。自己手动创建即可。

B:模型什么时候保存?如何更改
迭代次数小于1000时,每100次保存一次,大于1000时,没10000次保存一次。
自己可以根据需求进行更改,然后重新编译即可[ 先 make clean ,然后再 make]。
代码位置: examples/detector.c line 138
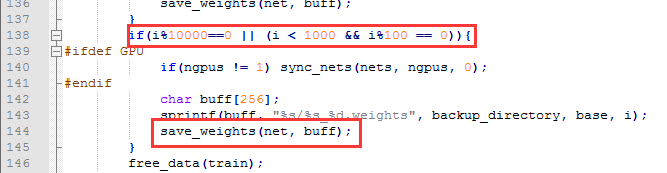
C:使用预训练模型直接保存问题
darknet53.conv.74作为预训练权重文件,因为只包含卷积层,所以可以从头开始训练。
xxx.weights作为预权重文件训练,因为包含所有层,相当于恢复快照训练,会从已经保存的迭代次数往下训练。如果cfg中迭代次数没改,所以不会继续训练,直接保存结束。
(5)中文标签问题
这个解决方案较多,我就简单的说一下大佬的方案
A:首先生成对应的中文标签,
修改代码中的字体,将其替换成指中文字体,如果提示提示缺少**模块,安装就行了。(如果只有一种类别的话,那是不是取消掉标签也可以)

B:添加自己的读取标签和画框函数
(6)图片上添加置信值
代码比较熟悉的童鞋,使用opencv在画框的函数里面添加一下就行了。(太低就不加了。。)
(7)图片保存名称
测试的时候,保存的默认名称是predictions.自己改成对应的图片名称即可。

(8)Floating, point, exception (core, dumped)
https://github.com/pjreddie/darknet/issues/140#issuecomment-375791093
v2: anchors[k-means]+多尺度+跨尺度特征融合
v3: anchors[k-means]+多尺度+跨尺度特征融合
v2,v3两者都是有上面的共同特点,简单的多尺度不是提升小目标的检测的关键。
v2: 32x的下采样,然后使用anchor进行回归预测box
问题:较大的下采样因子,通常可以带来较大的感受野,这对于分类任务是有利,但会损害目标检测和定位【小目标在下采样过程中消失,大目标边界定位不准】
v3: 针对这个问题,进行了调整。就是在网络的3个不同的尺度进行了box的预测。【说白了就是FPN的思想】在下采样的前期就进行目标的预测,这样就可以改善小目标检测和定位问题。
不理解的话,稍微看一下FPN,就明白了。这个才是v3提升小目标的关键所在。
之后会总结yolov2,v3的论文理解!先实践!
这篇关于YOLOv3实践darknet跑voc数据集的问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






