本文主要是介绍YOLOv9训练自己的数据集:最新最详细教程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、代码及论文链接:
代码链接:https://github.com/WongKinYiu/yolov9/tree/main
论文链接:https://arxiv.org/abs/2402.13616
二、使用步骤
1.1 虚拟环境配置
创建一个虚拟环境用于单独对yolov9的环境进行配置:
conda create -n yolov9 python=3.8
配置虚拟环境的工程依赖
# 激活你的虚拟环境
activate yolov9
# cd到你的yolov9-main
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# 这里我提前注释掉了torch的安装部分,需要自行安装gpu版的torch、torchvision此时我们安装的只是基础的CPU状态,如果需要使用GPU训练,需要在pytorch中找到适合自己的cuda版本的torch口令然后下载。(我用的原博主的,因为我自己选的有问题hhh)
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
找到适合自己的cuda版本方法:①打开NVIDIA控制面板:
一般按照上面操作,环境就配好了。可以在train.py里面调试一下使用torch.cuda.is_available()来判断是否GPU成功可用。
1.2 数据集准备
数据集:东北大学缺陷检测数据集(6类别缺陷)
数据集百度网盘链接:链接:https://pan.baidu.com/s/1QktBnMcDdsQaT6JQXBjNPA
提取码:cslw 数据集有效期:一年
新建datasets文件,包含images和labels。
新建my_data.yaml,内容如下:path改为自己的datasets位置
path: D:\documents\yolov9-main\datasets # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/val # val images (relative to 'path') 128 images
test: images/test # test images (optional)nc: 6# Classes
names: 0: xxx1: xxx 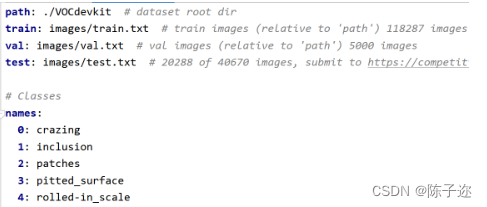
下载预训练文件
https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c-converted.pt
2.1 填写训练脚本
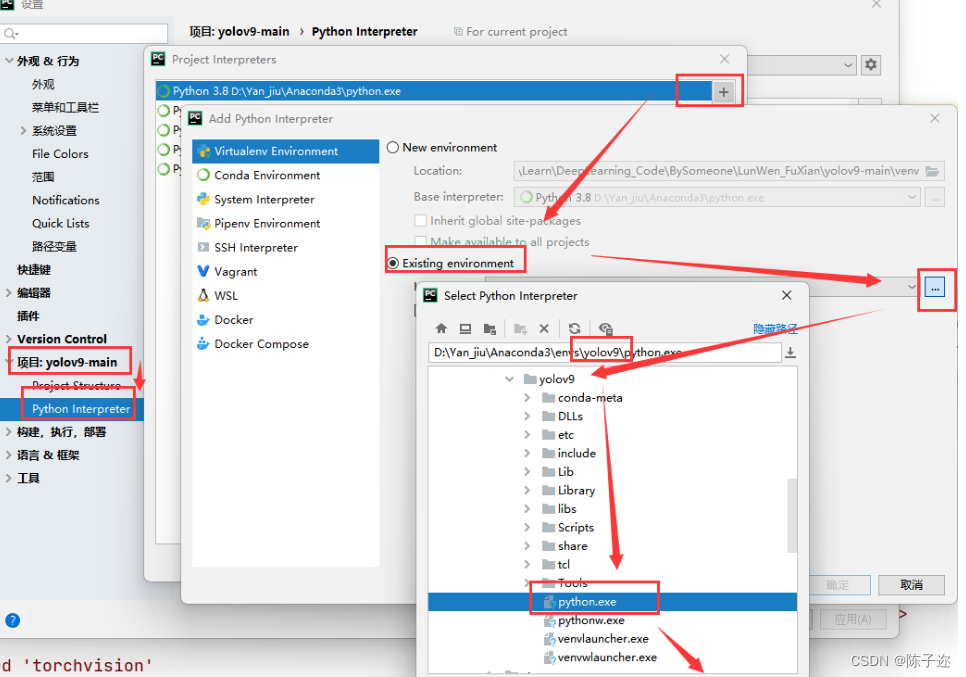
左上角点击文件,点击设置,设置环境为新建的环境yolov9
打开YOLOv9工程下的train_dual.py脚本文件,并按图中依次填入以下路径:
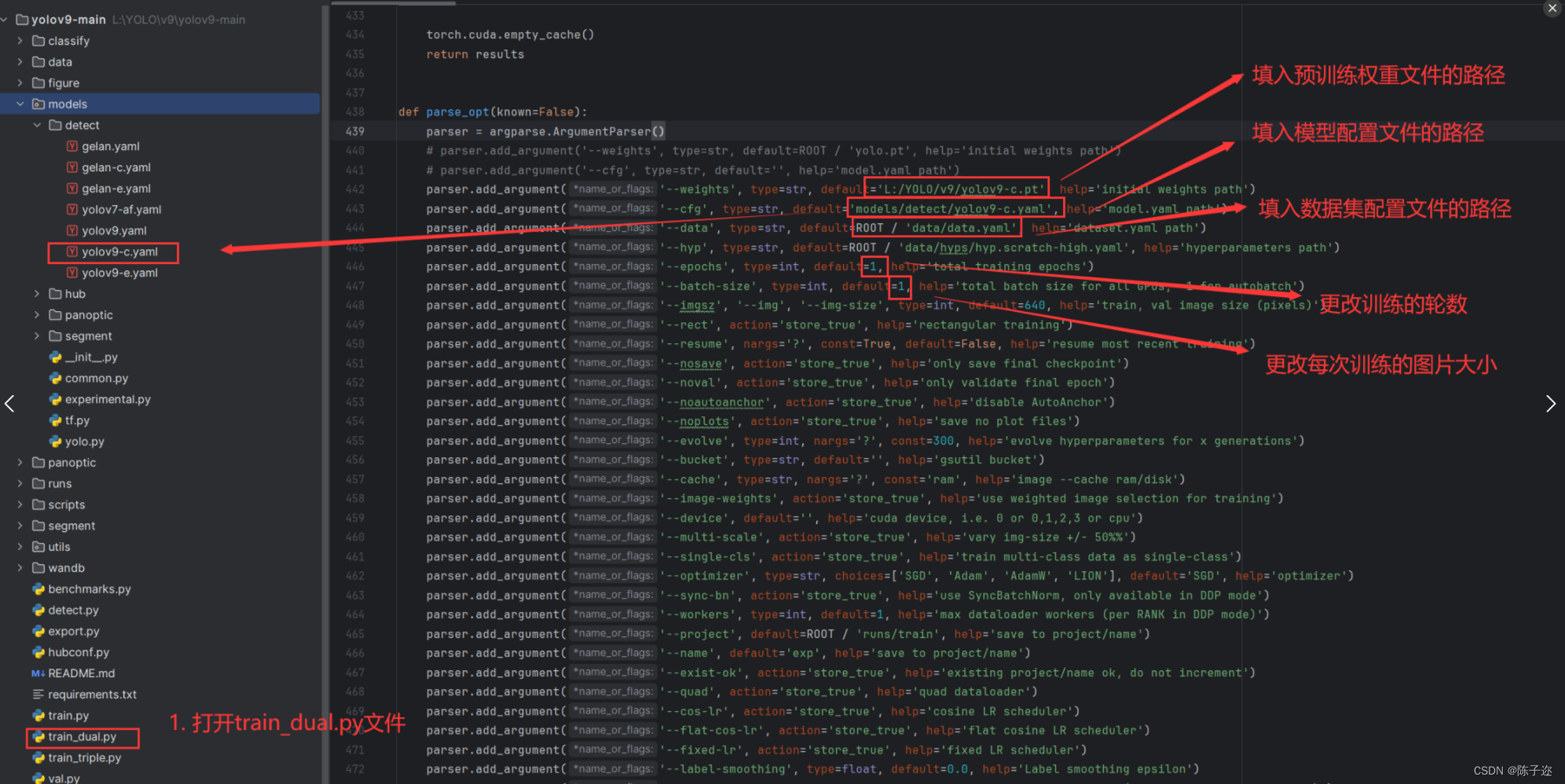 2.2运行即可。
2.2运行即可。
3.训练
我这里租用的是云服务器,因此要配置一些环境(如果是拿自己电脑训练的话,就可以跳过环境配置)。
其实也很简单:pip install -r requirements.txt apt-get update apt-get install libglib2.0-dev
之后开始训练: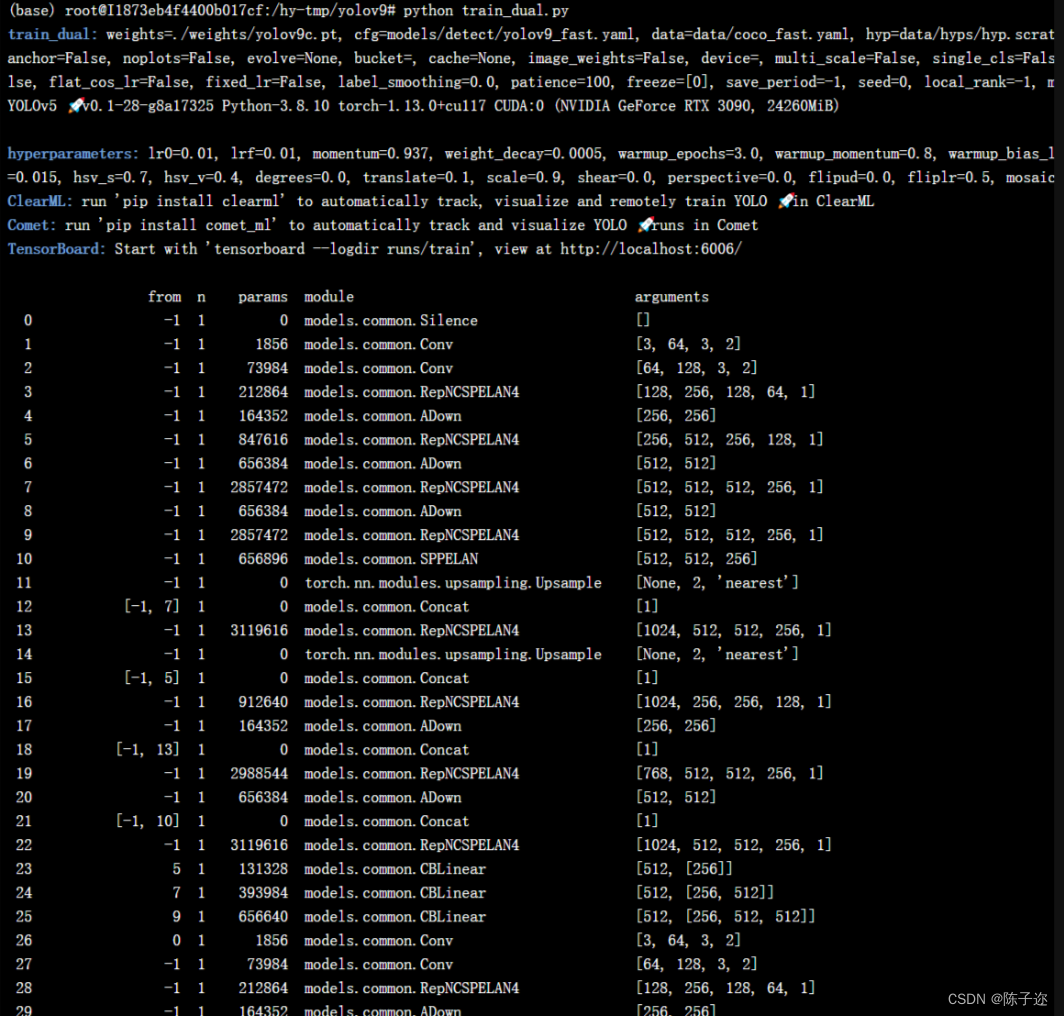
给大家看看前十次的训练结果
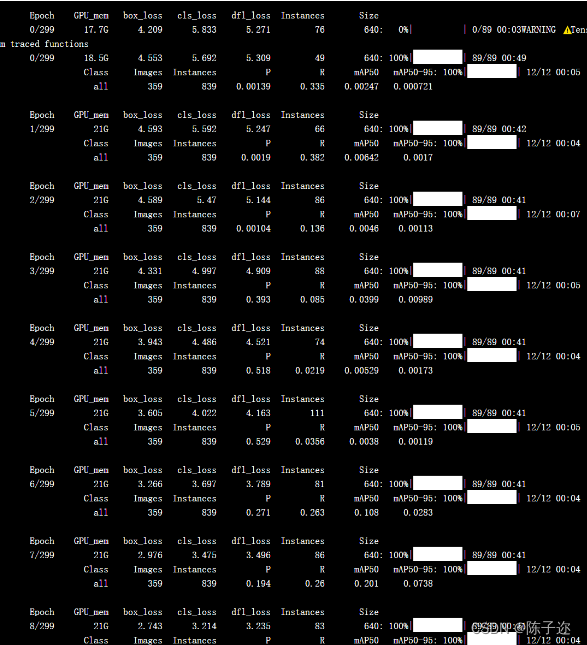
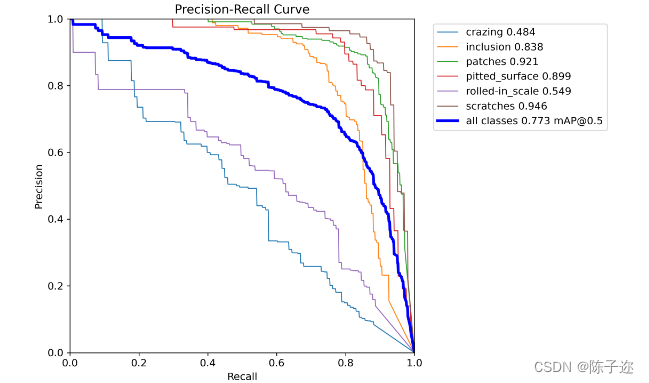
咋们看看结果
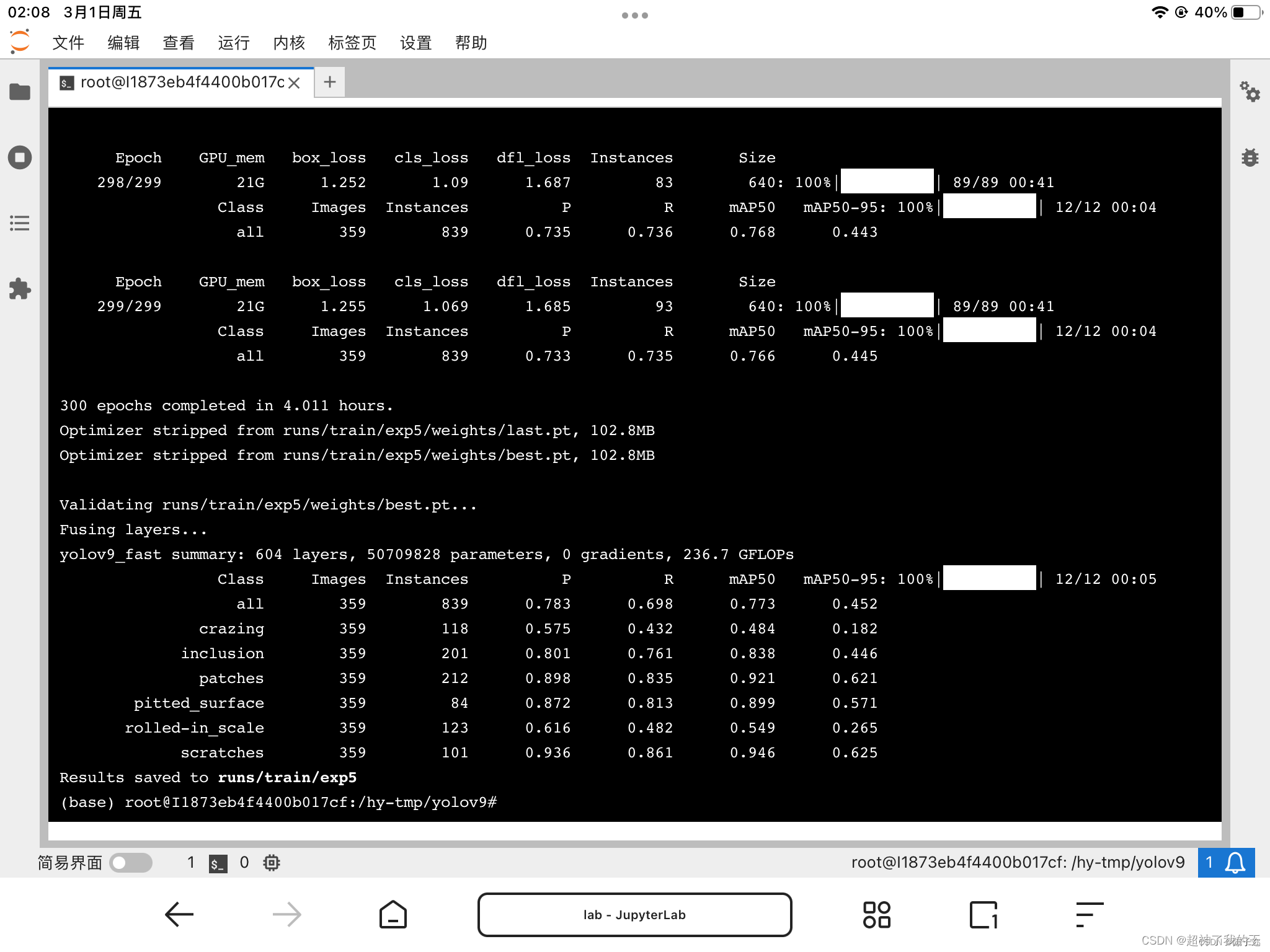
PR曲线,可以看出基本是吊打了之前的yolo
4.检测一下试试效果
先修改一下detect.py中的参数

1)这里需要将runs/train/exp5/weights中的best.pt复制到与detect.py同级目录下
2)在detect.py同级目录新建testfile文件夹,里面放你要检测的图像
3)修改coco128为my_data.yaml
好运行一下:python detect.py

这篇关于YOLOv9训练自己的数据集:最新最详细教程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






