本文主要是介绍助力数字农林业发展服务香榧智慧种植,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建香榧种植场景下香榧果实检测识别系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作为一个生在北方但在南方居住多年的人,居然头一次听过香榧(fei)这种作物,而且这个字还不会念,查了以后才知道读音(fei),三声,这着实引起了我的好奇心,我相信不认识这种作物的肯定不是只有我一个人吧。趁着假期的出去游玩的时间间隙专门去拍摄采集了相应的图片,想要结合自己做的事情来搞点有意思的事情,也是希望在不久的未来,AI真正落地数字农业赛道,为农业的发展带来新的活力,下面是我查的香榧的介绍:
香榧(学名:Torreya grandis 'Merrillii')是一种红豆杉科榧属多年生常绿乔木,也是中国特有树种和世界上稀有的经济树种。以下是对香榧的详细介绍:
形态特征:
香榧树的高度可达20至25米,直径约为1米。
树皮淡黄灰色或深灰色,有不规则的裂纹。
一年生枝条为绿色,二至三年生小枝为黄绿、淡褐黄或暗绿黄色。
树叶线形,上面光绿色,下面淡绿色。
种子为椭圆形、卵圆形、倒卵形或长椭圆形,成熟时假种皮淡紫褐色,有白粉,顶端有小凸尖头。
生长环境:
香榧主要生长在中国南方较为湿润的地区,如浙江、江苏南部、福建、江西、安徽、湖南、贵州等地,海拔1400米以下。
喜温暖湿润的气候和深厚肥沃的酸性土壤,不耐积水、干旱积薄,较耐寒。
最适宜的年平均温度为14-18℃,历年≥10℃平均活动积温7000℃以上,年极端最低温度在≥-15℃,最高气温≤43.0℃,无霜期日数≥210天,年均降水量≥1200毫米。
繁殖方式:
香榧的繁殖一般采用本地的粗榧为砧木,用优良的品种进行嫁接,4到6年开花结果。
也可以用嫁接苗造林的方式进行繁殖。
经济价值:
香榧种子含精油,有20多种芳香成分,是高级芳香油和浸膏的天然优质原料。
香榧果营养丰富,风味香醇,具有保健作用,是上等干果,具有很高的经济价值。
精油可用于日用化工工业如牙膏、香皂。
药用种仁、枝叶也可驱虫、消积、润燥等。
香榧树木质轻柔、致密,纹理直,是建筑、造船和工艺雕刻的良材。
口感和食用价值:
香榧的果实壳薄仁满,金黄黄的,入口香脆,比普通的坚果好吃,满足挑剔的味蕾。
香榧中含有较为丰富的维生素E,因此具有润泽肌肤、延缓衰老的功效。
香榧含有一种脂肪油,能够让脂溶性维生素更好地吸收,从而增加食欲。
香榧有润肠通便的作用,能促进胃肠道蠕动,缓解便秘等症状。
总的来说,香榧是一种珍贵的树种,不仅具有观赏价值,还有很高的经济价值和食用价值。同时,它也是一种具有保健作用的食品,深受人们喜爱。
农林业不是我的专长,这里本文的主要目的是想要基于目标检测模型来开发构建一套香榧果实的自动检测识别系统,在前文中我们已经基于YOLOv3做了相关的开发实践了,感兴趣的话可以自行移步阅读即可:
《助力数字农林业发展服务香榧智慧种植,基于YOLOv3全系列【yolov3tiny/yolov3/yolov3spp】参数模型开发构建香榧种植场景下香榧果实检测识别系统》
本文主要是想要基于最为经典的YOLOv5模型来开发构建对应的检测系统,首先看下实例效果:
接下来看下实例数据集:


本文是选择的是YOLOv5算法模型来完成本文项目的开发构建。相较于前两代的算法模型,YOLOv5可谓是集大成者,达到了SOTA的水平,下面简单对v3-v5系列模型的演变进行简单介绍总结方便对比分析学习:
【YOLOv3】
YOLOv3(You Only Look Once version 3)是一种基于深度学习的快速目标检测算法,由Joseph Redmon等人于2018年提出。它的核心技术原理和亮点如下:
技术原理:
YOLOv3采用单个神经网络模型来完成目标检测任务。与传统的目标检测方法不同,YOLOv3将目标检测问题转化为一个回归问题,通过卷积神经网络输出图像中存在的目标的边界框坐标和类别概率。
YOLOv3使用Darknet-53作为骨干网络,用来提取图像特征。检测头(detection head)负责将提取的特征映射到目标边界框和类别预测。
亮点:
YOLOv3在保持较高的检测精度的同时,能够实现非常快的检测速度。相较于一些基于候选区域的目标检测算法(如Faster R-CNN、SSD等),YOLOv3具有更高的实时性能。
YOLOv3对小目标和密集目标的检测效果较好,同时在大目标的检测精度上也有不错的表现。
YOLOv3具有较好的通用性和适应性,适用于各种目标检测任务,包括车辆检测、行人检测等。
【YOLOv4】
YOLOv4是一种实时目标检测模型,它在速度和准确度上都有显著的提高。相比于其前一代模型YOLOv3,YOLOv4在保持较高的检测精度的同时,还提高了检测速度。这主要得益于其采用的CSPDarknet53网络结构,主要有三个方面的优点:增强CNN的学习能力,使得在轻量化的同时保持准确性;降低计算瓶颈;降低内存成本。YOLOv4的目标检测策略采用的是“分而治之”的策略,将一张图片平均分成7×7个网格,每个网格分别负责预测中心点落在该网格内的目标。这种方法不需要额外再设计一个区域提议网络(RPN),从而减少了训练的负担。然而,尽管YOLOv4在许多方面都表现出色,但它仍然存在一些不足。例如,小目标检测效果较差。此外,当需要在资源受限的设备上部署像YOLOv4这样的大模型时,模型压缩是研究人员重新调整较大模型所需资源消耗的有用工具。
优点:
速度:YOLOv4 保持了 YOLO 算法一贯的实时性,能够在检测速度和精度之间实现良好的平衡。
精度:YOLOv4 采用了 CSPDarknet 和 PANet 两种先进的技术,提高了检测精度,特别是在检测小型物体方面有显著提升。
通用性:YOLOv4 适用于多种任务,如行人检测、车辆检测、人脸检测等,具有较高的通用性。
模块化设计:YOLOv4 中的组件可以方便地更换和扩展,便于进一步优化和适应不同场景。
缺点:
内存占用:YOLOv4 模型参数较多,因此需要较大的内存来存储和运行模型,这对于部分硬件设备来说可能是一个限制因素。
训练成本:YOLOv4 模型需要大量的训练数据和计算资源才能达到理想的性能,这可能导致训练成本较高。
精确度与速度的权衡:虽然 YOLOv4 在速度和精度之间取得了较好的平衡,但在极端情况下,例如检测高速移动的物体或复杂背景下的物体时,性能可能会受到影响。
误检和漏检:由于 YOLOv4 采用单一网络对整个图像进行预测,可能会导致一些误检和漏检现象。
【YOLOv5】
YOLOv5是一种快速、准确的目标检测模型,由Glen Darby于2020年提出。相较于前两代模型,YOLOv5集成了众多的tricks达到了性能的SOTA:
技术原理:
YOLOv5同样采用单个神经网络模型来完成目标检测任务,但采用了新的神经网络架构,融合了领先的轻量级模型设计理念。YOLOv5使用较小的骨干网络和新的检测头设计,以实现更快的推断速度,并在不降低精度的前提下提高目标检测的准确性。
亮点:
YOLOv5在模型结构上进行了改进,引入了更先进的轻量级网络架构,因此在速度和精度上都有所提升。
YOLOv5支持更灵活的模型大小和预训练选项,可以根据任务需求选择不同大小的模型,同时提供丰富的数据增强扩展、模型集成等方法来提高检测精度。YOLOv5通过使用更简洁的代码实现,提高了模型的易用性和可扩展性。
训练数据配置文件如下:
# Dataset
path: ./dataset
train:- images/train
val:- images/test
test:- images/test# Classes
names:0: torreya实验截止目前,本文将YOLOv5系列五款不同参数量级的模型均进行了开发评测,在实验训练开发阶段,所有的模型均保持完全相同的参数设置,等待训练完成后,来整体进行评测对比分析。
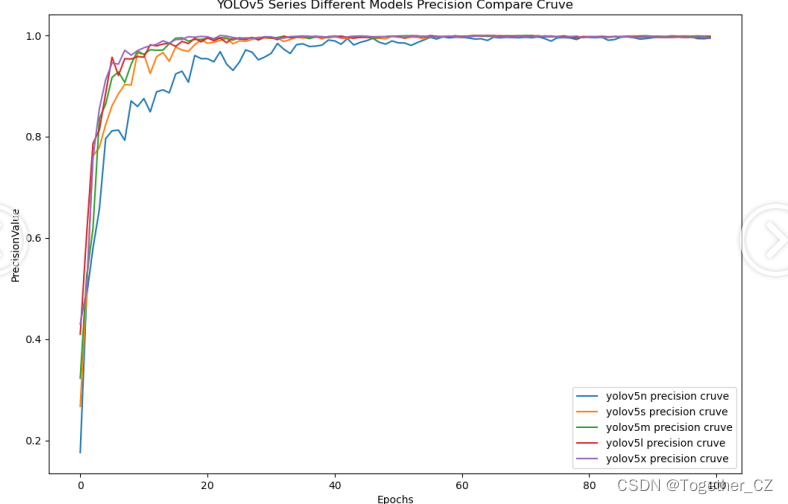
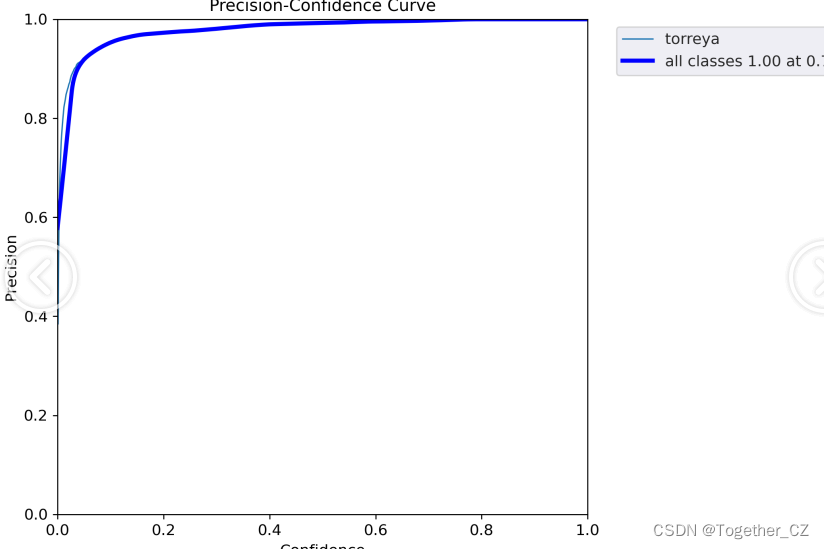
【Precision曲线】
精确率曲线(Precision Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率曲线。
根据精确率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察精确率曲线,我们可以根据需求确定最佳的阈值,以平衡精确率和召回率。较高的精确率意味着较少的误报,而较高的召回率则表示较少的漏报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
精确率曲线通常与召回率曲线(Recall Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
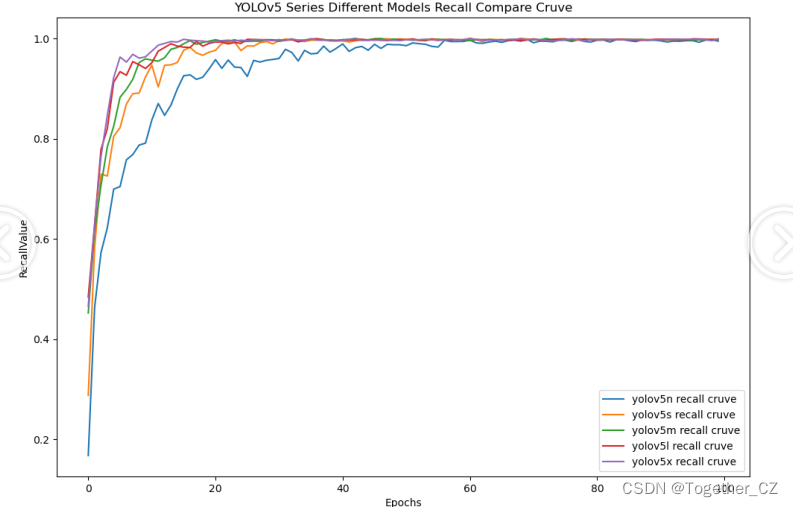
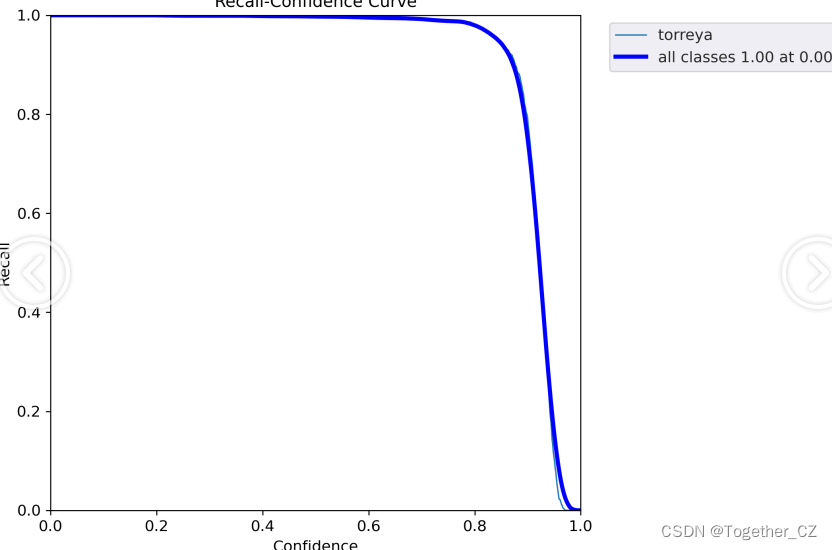
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。
召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
绘制召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的召回率和对应的精确率。
将每个阈值下的召回率和精确率绘制在同一个图表上,形成召回率曲线。
根据召回率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察召回率曲线,我们可以根据需求确定最佳的阈值,以平衡召回率和精确率。较高的召回率表示较少的漏报,而较高的精确率意味着较少的误报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
召回率曲线通常与精确率曲线(Precision Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
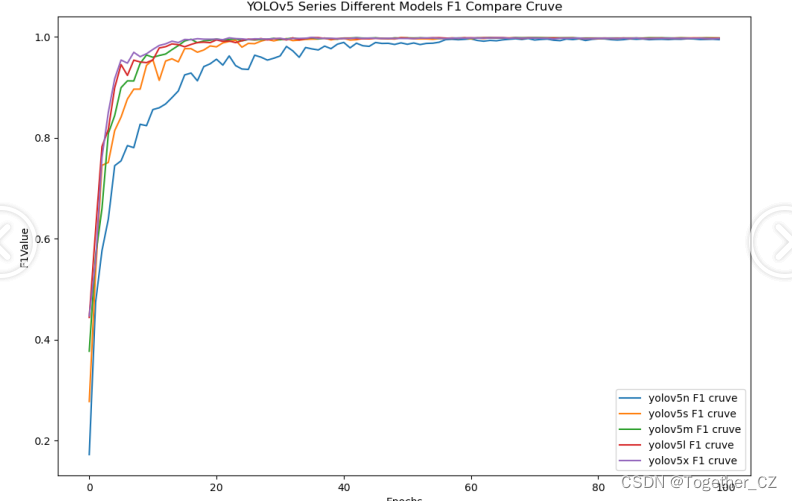
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
绘制F1值曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率、召回率和F1分数。
将每个阈值下的精确率、召回率和F1分数绘制在同一个图表上,形成F1值曲线。
根据F1值曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
F1值曲线通常与接收者操作特征曲线(ROC曲线)一起使用,以帮助评估和比较不同模型的性能。它们提供了更全面的分类器性能分析,可以根据具体应用场景来选择合适的模型和阈值设置。
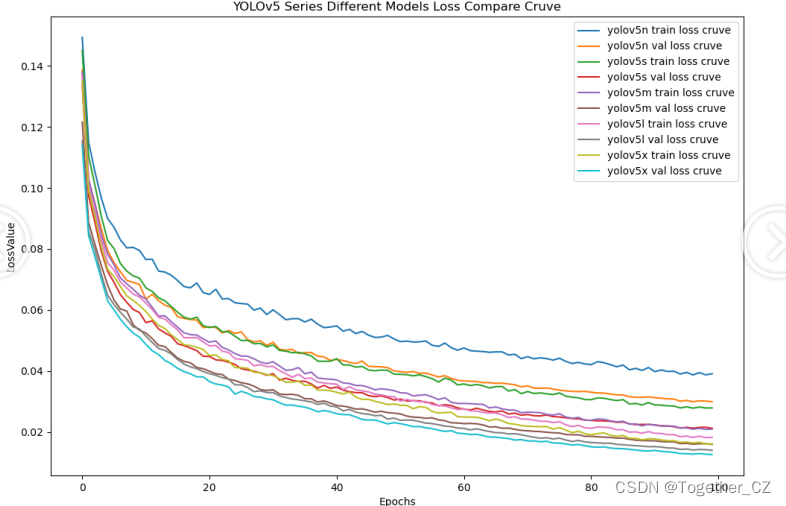
【loss对比曲线】
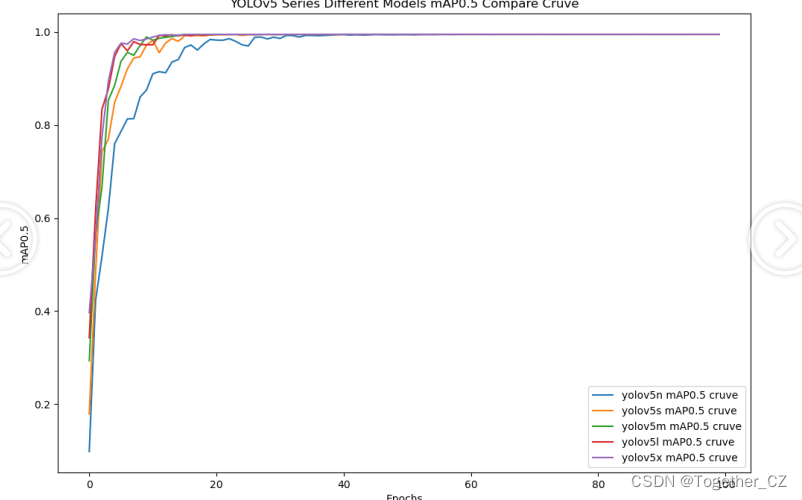
【mAP0.5】
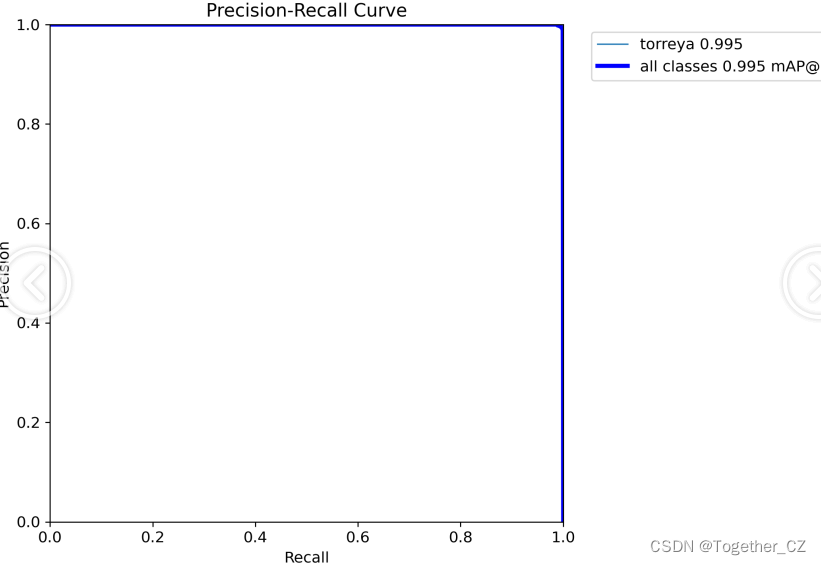
mAP0.5,也被称为mAP@0.5或AP50,指的是当Intersection over Union(IoU)阈值为0.5时的平均精度(mean Average Precision)。IoU是一个用于衡量预测边界框与真实边界框之间重叠程度的指标,其值范围在0到1之间。当IoU值为0.5时,意味着预测框与真实框至少有50%的重叠部分。
在计算mAP0.5时,首先会为每个类别计算所有图片的AP(Average Precision),然后将所有类别的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲线下面的面积,这个面积越大,说明AP的值越大,类别的检测精度就越高。
mAP0.5主要关注模型在IoU阈值为0.5时的性能,当mAP0.5的值很高时,说明算法能够准确检测到物体的位置,并且将其与真实标注框的IoU值超过了阈值0.5。
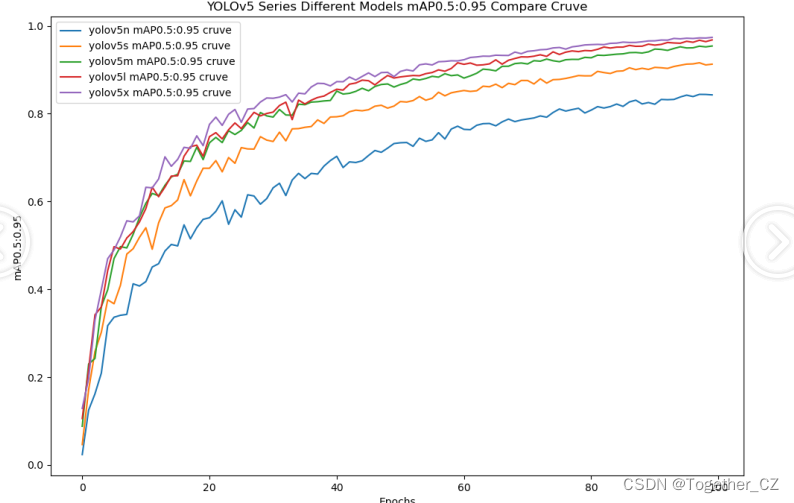
【mAP0.5:0.95】
mAP0.5:0.95,也被称为mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU阈值从0.5到0.95变化时,取各个阈值对应的mAP的平均值。具体来说,它会在IoU阈值从0.5开始,以0.05为步长,逐步增加到0.95,并在每个阈值下计算mAP,然后将这些mAP值求平均。
这个指标考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。当mAP0.5:0.95的值很高时,说明算法在不同阈值下的检测结果均非常准确,覆盖面广,可以适应不同的场景和应用需求。
对于一些需求比较高的场合,比如安全监控等领域,需要保证高的准确率和召回率,这时mAP0.5:0.95可能更适合作为模型的评价标准。
综上所述,mAP0.5和mAP0.5:0.95都是用于评估目标检测模型性能的重要指标,但它们的关注点有所不同。mAP0.5主要关注模型在IoU阈值为0.5时的性能,而mAP0.5:0.95则考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。
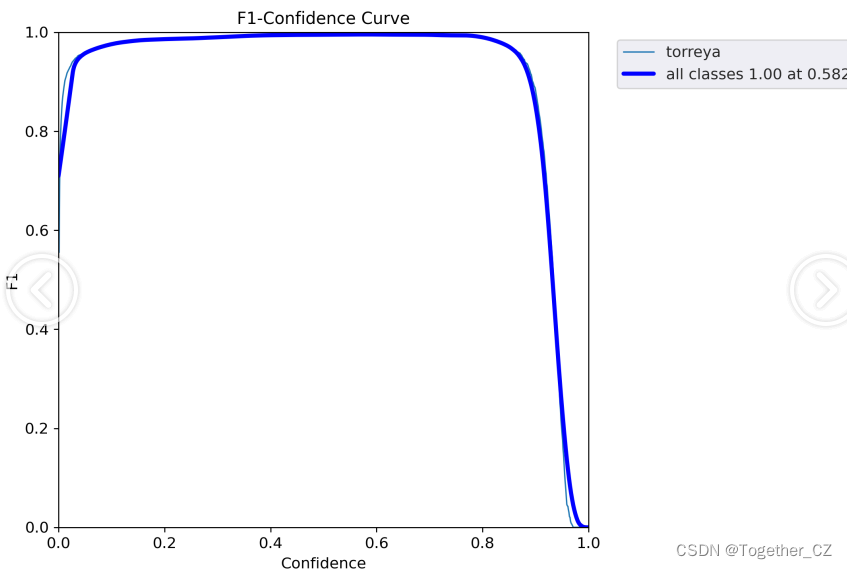
综合实验结果对比来看:五款不同参数量级的模型效果十分相近,综合考虑这里最终选择使用n系列的模型作为线上的推理模型。
接下来详细看下n系列模型的结果详情。
【离线推理实例】

【Batch实例】


【混淆矩阵】

【F1值曲线】
【Precision曲线】
【PR曲线】
【Recall曲线】
【训练可视化】

感兴趣的话也可以试试!AI助力数字化农林业发展会是未来的大趋势,也希望未来会有更多真正落地应用的科技赋能农林业发展!
这篇关于助力数字农林业发展服务香榧智慧种植,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建香榧种植场景下香榧果实检测识别系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





