本文主要是介绍Hive、MySQL、Sqoop求TOP N,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一 数据说明
- 二 分析
- 三 Sqoop
- 3.1 什么是Sqoop
- 3.2 Sqoop部署
- 3.3 Sqoop简单应用
- 3.4 Sqoop import HDFS
- 3.5 Sqoop import Hive
- 四 Hive中查询top3
- 五 数据导出MySQL
一 数据说明
目前我们有三张表
1.位于MySQL的city_info表, product_info表
2.位于Hive的user_click表
城市信息表city_info ,字段说明如下:
city_id:城市id
city_name:城市名称
area:区域的缩写,例如华北,华东
mysql> select * from city_info;
+---------+-----------+------+
| city_id | city_name | area |
+---------+-----------+------+
| 1 | BEIJING | NC |
| 2 | SHANGHAI | EC |
| 3 | NANJING | EC |
| 4 | GUANGZHOU | SC |
| 5 | SANYA | SC |
| 6 | WUHAN | CC |
| 7 | CHANGSHA | CC |
| 8 | XIAN | NW |
| 9 | CHENGDU | SW |
| 10 | HAERBIN | NE |
+---------+-----------+------+
产品信息表,字段描述如下:
product_id: 产品id
product_name: 产品名称
extend_info: 产品的扩展信息
mysql> select * from product_info limit 10;
+------------+--------------+----------------------+
| product_id | product_name | extend_info |
+------------+--------------+----------------------+
| 1 | product1 | {"product_status":1} |
| 2 | product2 | {"product_status":1} |
| 3 | product3 | {"product_status":1} |
| 4 | product4 | {"product_status":1} |
| 5 | product5 | {"product_status":1} |
| 6 | product6 | {"product_status":1} |
| 7 | product7 | {"product_status":1} |
| 8 | product8 | {"product_status":1} |
| 9 | product9 | {"product_status":0} |
| 10 | product10 | {"product_status":1} |
+------------+--------------+----------------------+
10 rows in set (0.00 sec)
用户行为表user_click,字段描述如下:
user_id: 用户id
session_id: 会话id
action_time: 操作时间
city_id: 城市id
product_id: 产品id
date:为分区字段
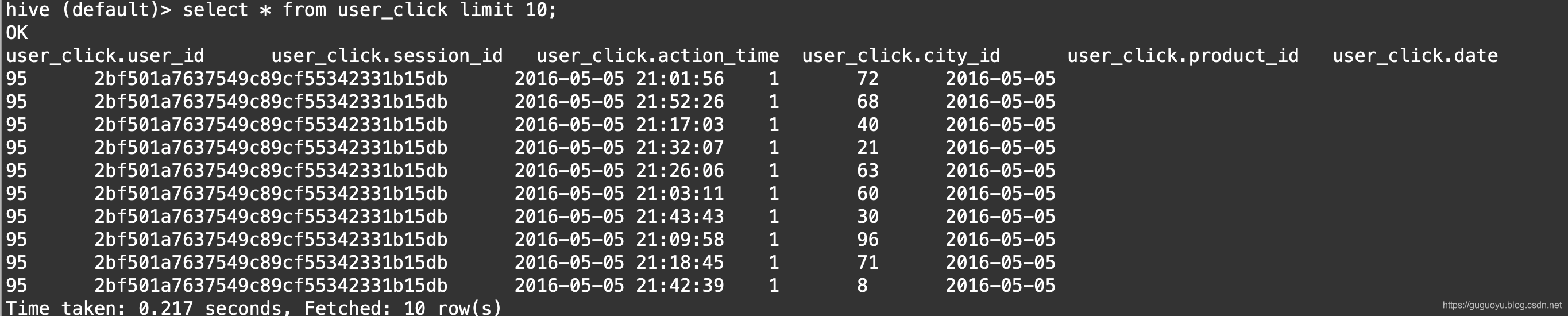
需求:求各个区域下最受欢迎的产品的TOP N
二 分析
1.Hive里表没有区域字段,没有产品名称
2.MySQL里有区域和产品的信息
那么大概思路可以这样执行:
1.把city_info和product_info表信息放入Hive
2.然后user_click和Hive里的city_info以及product_info进行关联
3.再使用窗口函数进行分组内求TOP N
第一步我们可以通过Sqoop把MySQl数据导入Hive
三 Sqoop
3.1 什么是Sqoop
Apache Sqoop™ is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
上面这一段是官网的第一句话:Sqoop是一个工具,为了高效传输大数据而设计的,在Hadoop和结构化数据存储系统之间,例如关系型数据库
3.2 Sqoop部署
1.解压sqoop
tar -zxvf sqoop-1.4.6-cdh5.7.0.tar.gz

2.设置软连接
ln -s /home/hadoopadmin/software/sqoop-1.4.6-cdh5.7.0 sqoop

3.配置文件
拷贝一份sqoop-env
cp sqoop-env-template.sh sqoop-env.sh
编辑sqoop-env
vi sqoop-env.sh
修改如下配置信息
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/home/hadoopadmin/app/hadoop#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/home/hadoopadmin/app/hadoop#Set the path to where bin/hive is available
export HIVE_HOME=/home/hadoopadmin/app/hive
4.修改环境变量
vi ~/.bash_profile
添加如下环境变量
export SQOOP_HOME=/home/hadoopadmin/app/sqoop
export PATH=${SQOOP_HOME}/bin:$PATH
生效环境变量
source ~/.bash_profile
5.添加mysql驱动
cp ~/software/mysql-connector-java-5.1.47.jar ~/app/sqoop/lib/
3.3 Sqoop简单应用
直接命令行敲一个sqoop,看会发生什么
提示:让我们试试 sqoop help命令
sqoop help
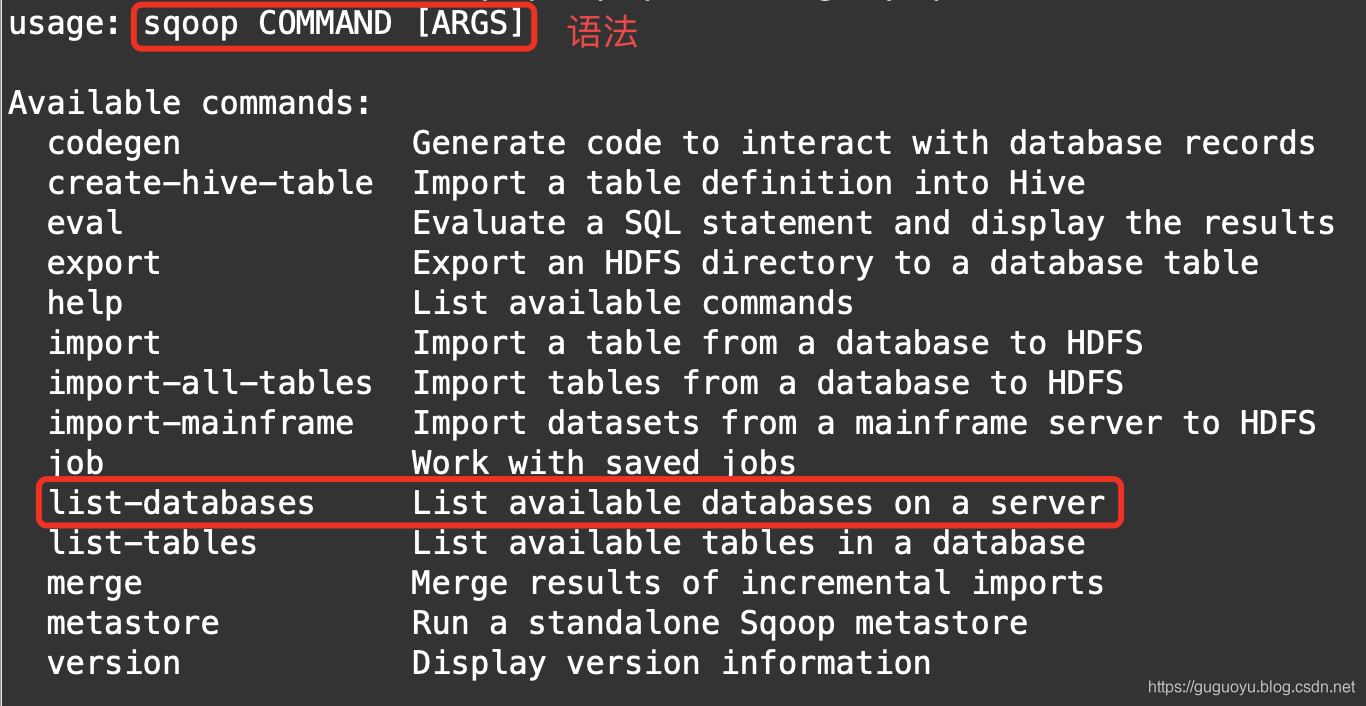
我们用list-databases看看mysql有什么数据库,但是需要哪些参数我们也不知道,我们继续通过帮助文档查看
sqoop list-databases --help;
下面为显示的帮助文档
#使用语法
usage: sqoop list-databases [GENERIC-ARGS] [TOOL-ARGS]Common arguments:#jdcb连接url--connect <jdbc-uri> Specify JDBC connectstring--connection-manager <class-name> Specify connection managerclass name--connection-param-file <properties-file> Specify connectionparameters file--driver <class-name> Manually specify JDBCdriver class to use--hadoop-home <hdir> Override$HADOOP_MAPRED_HOME_ARG--hadoop-mapred-home <dir> Override$HADOOP_MAPRED_HOME_ARG--help Print usage instructions
-P Read password from console#连接的密码--password <password> Set authenticationpassword--password-alias <password-alias> Credential providerpassword alias--password-file <password-file> Set authenticationpassword file path--relaxed-isolation Use read-uncommittedisolation for imports--skip-dist-cache Skip copying jars todistributed cache#连接的用户名--username <username> Set authenticationusername--verbose Print more informationwhile working
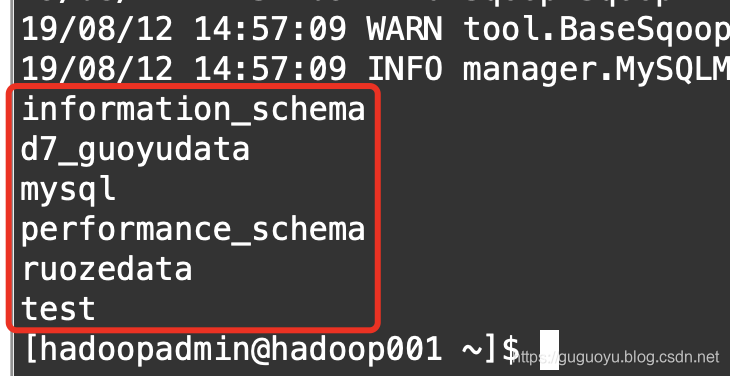
我们使用list-databases查看数据库信息
sqoop list-databases \
--connect jdbc:mysql://localhost:3306 \
--password 123456 \
--username root
查看ruozedata数据库里有哪些表
sqoop list-tables \
--connect jdbc:mysql://localhost:3306/ruozedata \
--password 123456 \
--username root

3.4 Sqoop import HDFS
我们导入一张表到HDFS
 可以通过sqoop import把MySQL数据导入HDFS
可以通过sqoop import把MySQL数据导入HDFS
可以通过sqoop import --help查询一些参数
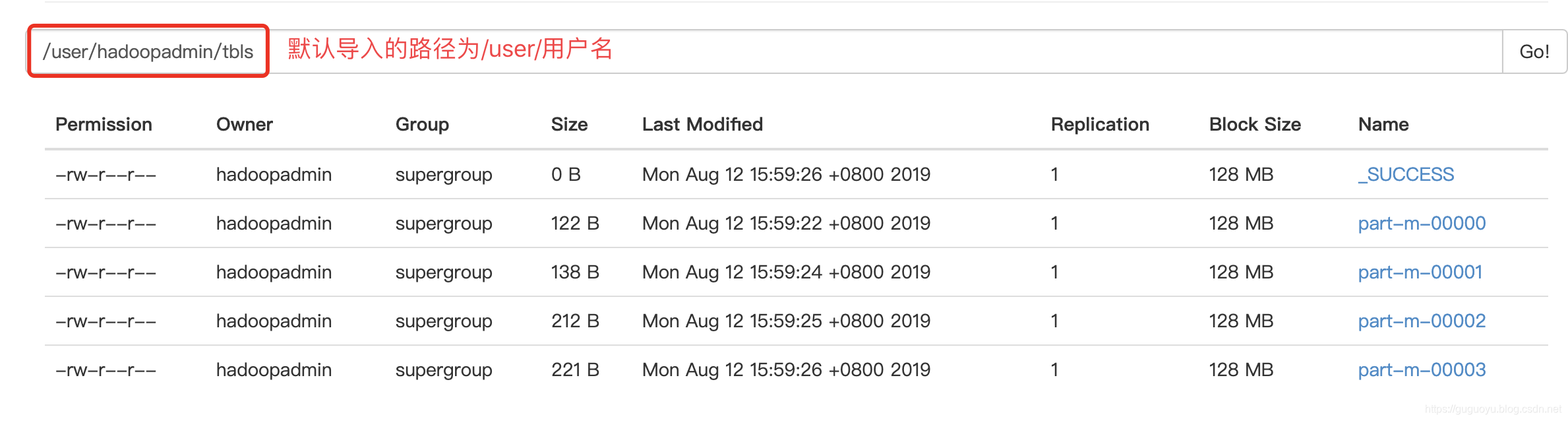
下面我们指定一个表导入hdfs,数据库为:d7_guoyudata 表为:tbls
我们也不知道导入哪里,先执行看看
sqoop import \
--connect jdbc:mysql://localhost:3306/d7_guoyudata \
--password 123456 \
--username root \
--table tbls;
出现下面这个错误:
Caused by: java.lang.ClassNotFoundException: org.json.JSONObjectat java.net.URLClassLoader.findClass(URLClassLoader.java:381)at java.lang.ClassLoader.loadClass(ClassLoader.java:424)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)at java.lang.ClassLoader.loadClass(ClassLoader.java:357)... 15 more
原因是$SQOOP_HOME/lib下缺少 java-json.jar
下载地址:
链接:https://pan.baidu.com/s/1DSSvsKGNXqEGlFQ0m-Oz9Q 密码:57xc
把下载后的jar包放入sqoop的lib目录下
然后再重新运行下面这个代码:
sqoop import \
--connect jdbc:mysql://localhost:3306/d7_guoyudata \
--password 123456 \
--username root \
--table tbls;
3.5 Sqoop import Hive
sqoop import 常用的一些命令说明
--connect <jdbc-uri> #jdbc连接的uri地址
--username <username> #数据库的用户名
--password <password> #数据库密码
--table <table-name> #数据库的表名
--columns <col1,col2,col3...> #数据库的字段名,例如:mysql的字段名
--delete-target-dir #添加此参数就是,每次先删除目标的目录
--target-dir <dir> #目标目录
--null-string <null-str> # 例如:mysql字段值是Null,那么用什么字符串替代,可以用''或者""
--null-non-string <null-non-str> #例如:mysql字段值为Null,那么用什么数值去替代,可以用0,-99
--fields-terminated-by <char> #字段分割符
--where <where clause> #可以加个 'id>20',那么就只会导入id>20的数据
--query <statement> #查询语句,以查询结果导入,注意:query不能和table同时使用
--num-mappers <n> #指定mapper的数量
--split-by <column-name> #如果表中有主键就不用此参数,如果没参数要指定字段,
#因为底层默认:根据主键查询如果有100条记录,如果有2个map,那么一分为二--hive-import #确认导入hive
--hive-database <database-name> #hive的数据库名
--hive-table <table-name> #hive的表名
--hive-overwrite #覆盖数据
下面从mysql的city_info表导入hive,先在hive中创建city_info表
create table city_info(
city_id int,
city_name string,
area string
)row format delimited fields terminated by '\t';
然后通过sqoop把mysql的city_info数据导入hive
sqoop import \
--connect jdbc:mysql://localhost:3306/ruozedata \
--username root \
--password 123456 \
--table city_info \
--split-by city_id \
--fields-terminated-by '\t' \
--delete-target-dir \
--hive-import \
--hive-database default \
--hive-table city_info \
--hive-overwrite
运行过程中可能会出现下面的错误:
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
如果出现这样的错误,执行下面的命令
cp ~/app/hive/lib/hive-common-1.1.0-cdh5.7.0.jar ~/app/sqoop/lib/
cp ~/app/hive/lib/hive-shims-*.jar ~/app/sqoop/lib/
其实就是把hive/lib目录下的5个jar包拷贝到sqoop/lib目录下,然后再运行导入命令就ok了

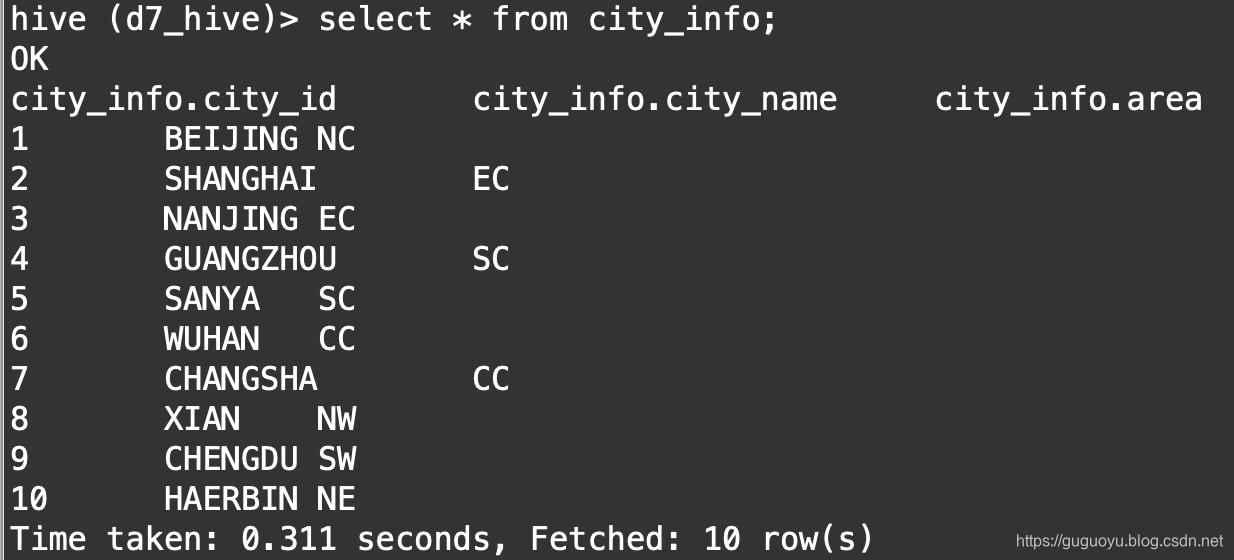
我们查看下导入后的数据:
下面再把product_info也导入hive中,先在hive中创建表
create table product_info(
product_id int,
product_name string,
extend_info string
)row format delimited fields terminated by '\t';
然后通过sqoop import开始导数据到hive中
sqoop import \
--connect jdbc:mysql://localhost:3306/ruozedata \
--username root \
--password 123456 \
--table product_info \
--split-by product_id \
--fields-terminated-by '\t' \
--delete-target-dir \
--hive-import \
--hive-database default \
--hive-table product_info \
--hive-overwrite
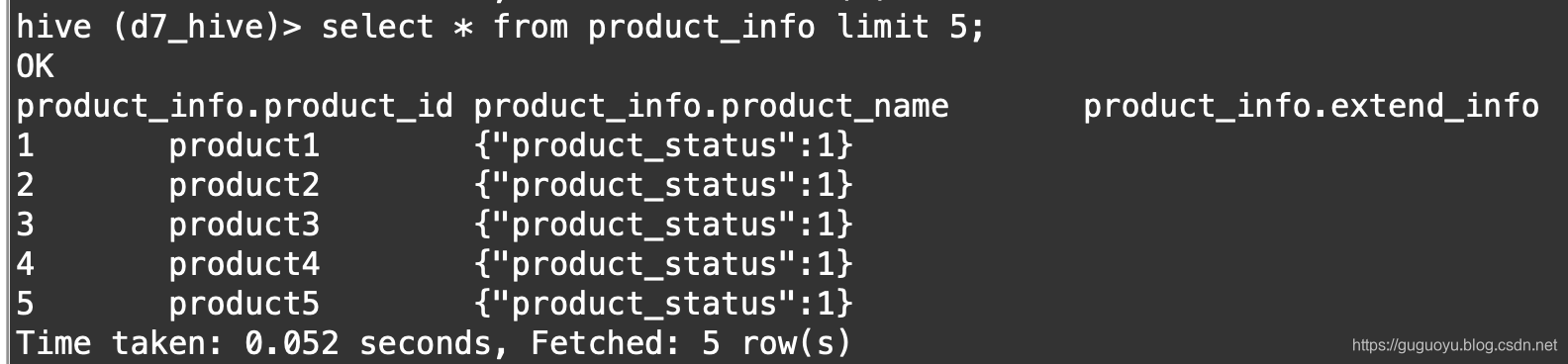
如下图,数据导入成功
四 Hive中查询top3
到目前位置,数据表都已经存在与hive中,我们是要求各个区域下最受欢迎的产品的top3
1.先将user_click和city_info进行关联查询,并创建一个基础临时表
create table tmp_product_click_basic_info
as
select u.product_id,u.city_id,c.area,c.city_name
from
(select user_id,city_id,product_id from user_click where date = '2016-05-05') u
join
(select city_id,city_name,area from city_info) c
on u.city_id = c.city_id;
2.查询每个区域下每个产品的点击次数,并创建一个临时表
create table tmp_area_product_click_count
as
select area,product_id,count(1) as click_count
from tmp_product_click_basic_info
group by area,product_id;
3.但是光是产品id给别人看肯定不行,肯定要给别人看产品名称,那么我们需要将tmp_area_product_click_count和product_info进行关联查询,并创建一个完整表
create table tmp_area_product_click_count_full
as
select t.product_id,t.area,p.product_name,t.click_count
from tmp_area_product_click_count as t join product_info as p
on t.product_id = p.product_id;
4.针对这个完整表,我们再通过窗口函数进行分区排序,并且添加上日期,这样我们就得到某一天,每个区域,排名前3的产品了
create table area_product_click_count_top3
row format delimited fields terminated by '\t'
as
select '2016-05-05' as day,product_id,area,product_name,click_count from
(select product_id,area,product_name,click_count,
ROW_NUMBER() over(partition by area order by click_count desc) as r
from tmp_area_product_click_count_full) t
where t.r<=3;
我们看下结果
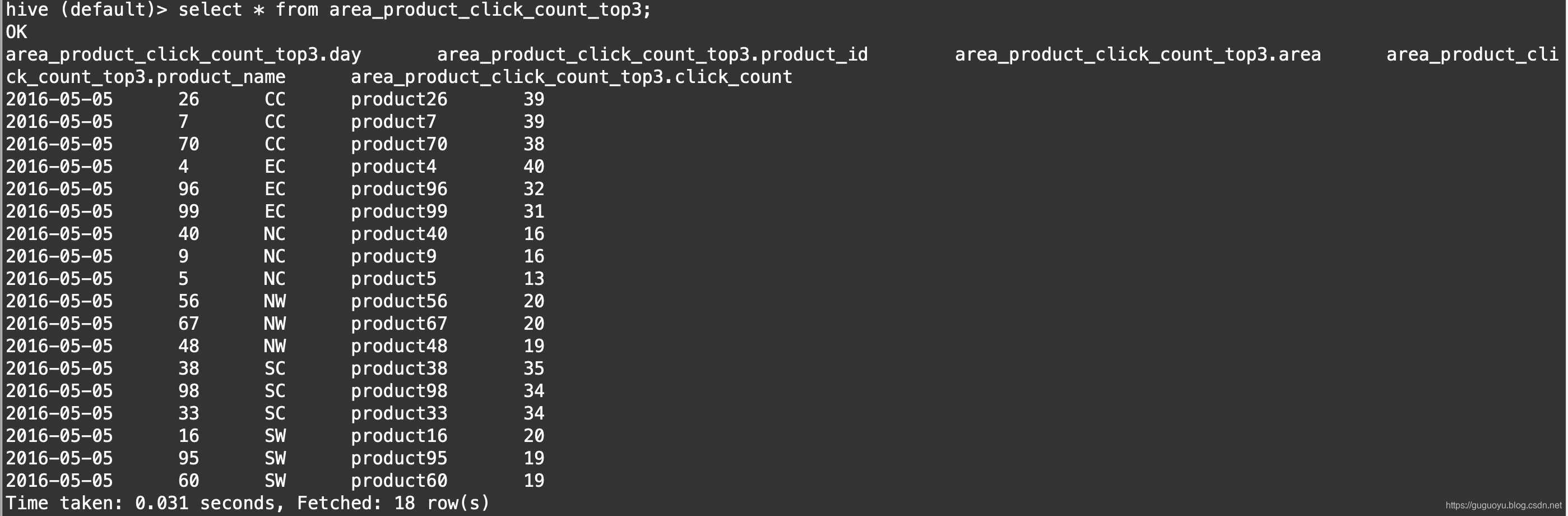
五 数据导出MySQL
数据目前是在hive中,如果需要给别人用,肯定要导入到MySQL里
1.首先在MySQL里创建一张表
create table area_product_click_count_top3(
day varchar(15),
product_id int(11),
area varchar(5),
product_name varchar(50),
click_count int(11)
);
2.把Hive表导入MySQL
sqoop export \
--connect jdbc:mysql://localhost:3306/ruozedata \
--username root \
--password 123456 \
--table area_product_click_count_top3 \
--export-dir /user/hive/warehouse/area_product_click_count_top3 \
--columns day,product_id,area,product_name,click_count \
--fields-terminated-by '\t' \
--num-mappers 2
如下图,数据导入成功
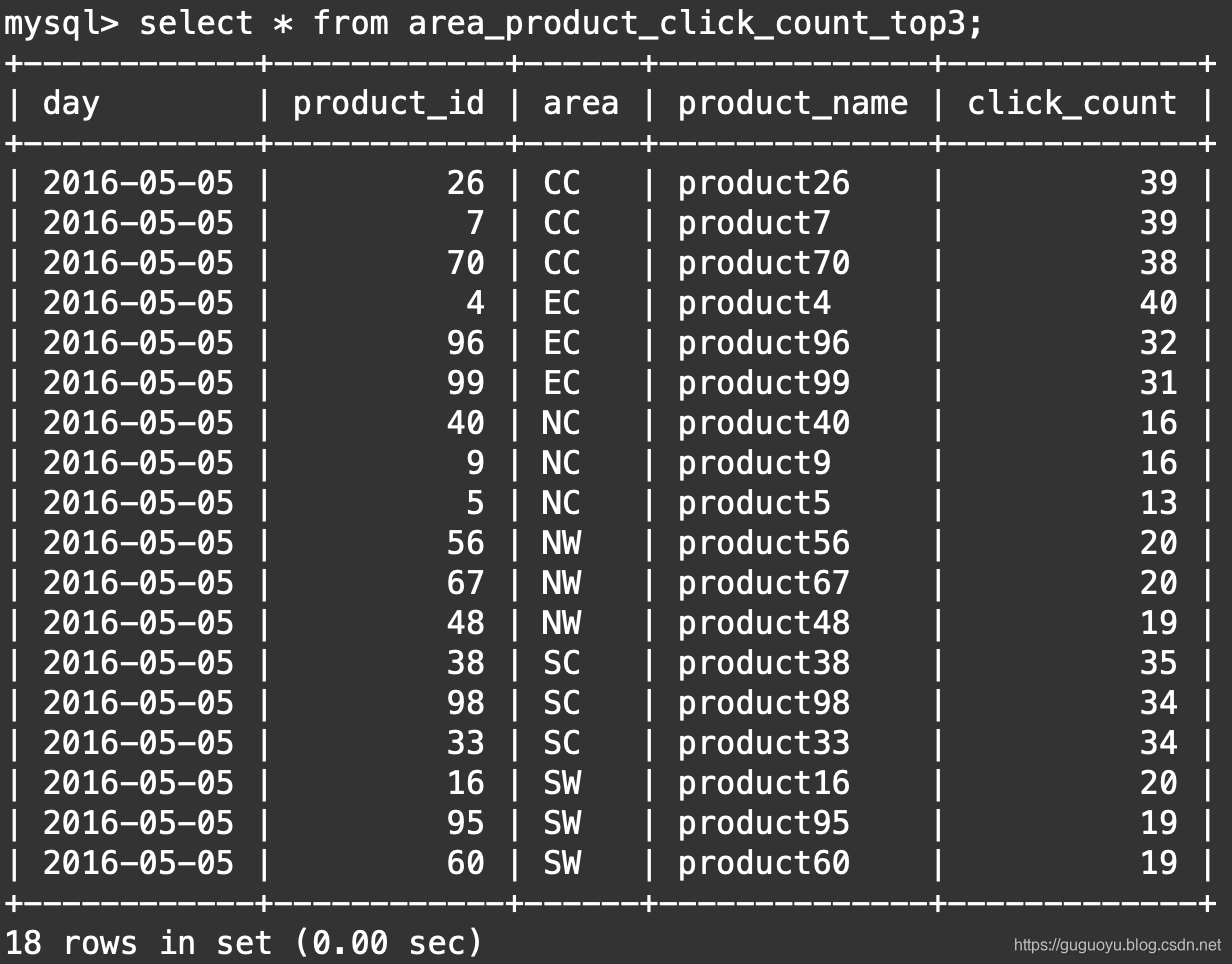
这篇关于Hive、MySQL、Sqoop求TOP N的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









