本文主要是介绍AI 情感聊天机器人工作之旅 —— 与复读机问题的相遇与别离,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:先前在杭州的一家大模型公司从事海外闲聊机器人产品,目前已经离职,文章主要讨论在闲聊场景下遇到的“复读机”问题以及一些我个人的思考和解决方案。文章内部已经对相关公司和人员信息做了去敏,如仍涉及到机密等情况,可删除。
meta 开源 Llama2 后,我们立马将基座模型从 Llama1 更换为了 Llama2。很重要的一个原因在于 Llama2 的 context length 是 4k,是 Llama1 的 2 倍,对于日益增长的角色人设 prompt 来说,2k 已经不满足线上产品使用。
在将 base 模型从 Llama1 “升级”到 Llama2 后出现了单句重复问题,该问题也被业界定义为“复读机问题”——模型会在一轮回复中不断重复某一相同或语义相似的子句,直到 max_new_tokens(最大输出长度)。
PS:Llama1 有没有这个问题已经无法追溯,其一,当时还没有在 sentry 查看日志链路的习惯;其二,产品和社区没有反馈该类问题,产品妹子们更多地是反馈多轮重复问题——模型在多轮对话中重复相同的内容。
由于当时尚处于 8 月份,vLLM 框架的集成以及后续将部署服务代码改造成 continuous batching 都仍处于“未来时”,模型直接使用 HuggingFace Transformers 库加载并流式输出。?B 大小的模型,其推理速度在 max_new_tokens = 500 场景下很容易超时(20 秒),即使不超时,也会占用消费者 worker 大量时间,出现消息队列拥堵,因此 sentry 报警的信息非常多,让我们注意到了这个问题。此外,社区与产品也反馈了该问题。
从 9 月 8 日开始,我参与到 BUG 的修复工作中。面对该问题,第一反应是训练数据中是否存在大量的重复,导致模型在训练过程中学到了这种重复的模式?检查了相关的训练数据集,的确发现存在大量重复的语句,用户在不断地说着同样或类似的话,而角色回复的内容也有大量的短语级的重复,再加上我们训练时,只训练角色回复且多 epoch,会强化这一倾向。论文《Understanding In-Context Learning from Repetitions》对表面特征在文本生成中的作用进行了定量研究,并根据经验确定 token 共现强化的存在,任何两个 token 构成一个 token 强化循环,在该循环中,任何两个 token 都可以通过多次重复出现而形成紧密联系。这是一种基于上下文共现强化两个 token 之间关系的原理。
但我们对训练数据集做了去重操作,但上线后仍然存在该问题。也就是说,复读机问题并不是在 SFT 阶段引入,base 模型本身就已经存在该问题,即使我们将 SFT 训练数据集的重复以及相近的数据都过滤,仍然有一定概率会触发。
陆陆续续地尝试了一些方法:
-
2023 年 9 月 08 日:对比解码的方式不能解决单句生成重复的问题,反而会因为避免生成重复 token 而选择一些“奇怪”的 token,从而生成更加离谱的回复
-
2023 年 9 月 11 日:另一种方法是在 SFT 阶段用高质量数据继续训练,用更多的“高质量”数据集训练更长时间后,在 42 个单句短语重复的 bad case 上测了下,可以解掉 22 个。
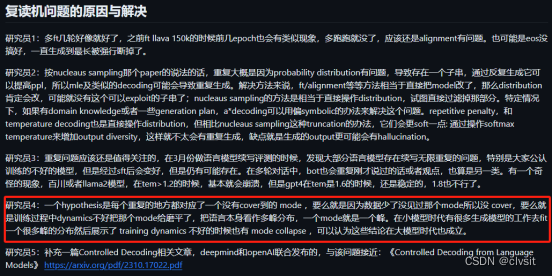
9 月 11 日得出的结论和研究员 4 的结论相同,通过更多的训练数据来让模型 cover 更多 context 下的输出,避免预训练阶段存在的问题(特定 context 下输出分布有问题,导致存在一个子串,反复生成该子串可以提高 PPL,例如成语接龙中“为所欲为”可以不停地循环)。 -
具体时间已经忘记,当时想到可以调整 prompt 格式。
- 依据:当前轮的输出会受到历史对话(尤其是最近几轮)的影响,结合大模型的 ICL 能力(多轮对话的格式和 ICL 非常相像,instruction + 多轮用户-角色对,类似 few-shot),推测是 prompt 的影响。
- 做法:以格式化的方式组织历史对话内容,但该方法与 SFT 阶段的 template 不一致,自研模型在输出时会出现意想不到的现象。后续尝试对历史对话进行总结,然后将总结拼接到 instruction,该方案可以有效地缓解单句重复问题,但成本较高(需要有额外的总结模型)。
- 本质:仍然是训练数据的问题,使得模型在特定 context 下加剧“复读机”问题。调整 prompt 格式,只是改变了这个 context,使模型有可能跳出这个重复的循环,可以作为一种后处理的方式。例如,当模型的生成出现“复读机”问题时,走 prompt 总结 + 重新生成。
后续,随着预训练组推出更多的 continued pretraining 模型,问题已经得到缓解,更多的持续预训练填补了 Llama2 本身预训练不充分的问题(Llama2 距离 Llama1 发布的时间太短,reddit 上也有不少反映 Llama2 复读机问题的帖子。
这篇关于AI 情感聊天机器人工作之旅 —— 与复读机问题的相遇与别离的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







