本文主要是介绍Elasticsearch解决字段膨胀问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 背景
- Flattened类型的产生
- Flattened类型的定义
- 基于Flattened类型插入数据
- 更新Flattened字段并添加数据
- Flattened类型检索
- Flattened类型的不足
背景
Elasticsearch映射如果不进行特殊设置,则默认为dynamic:true。dynamic:true实际上支持不加约束地动态添加字段。这样对某些日志场景,可能会产生大量的未知字段。字段如果持续激增,就会达到Elasticsearch映射层面的默认上限,对应设置和默认大小为index. mapping.total_fields.limit:1000。我们把这种非预期字段激增的现象称为字段膨胀。
Flattened类型的产生
如前分析,将dynamic设置为false或者strict不是普适的解决方案。例如,在日志场景中,虽然期望动态添加字段,但strict过于严格会导致新字段数据拒绝写入,而dynamic:true过于松散会导致字段膨胀。这就导致同时满足上述两个方面的Flattened字段的诞生。
Flattened类型最早发布于Elasticsearch 7.3这一版本。
一句话来说,Flattened字段就是用来解决字段膨胀问题的。
Flattened类型的定义
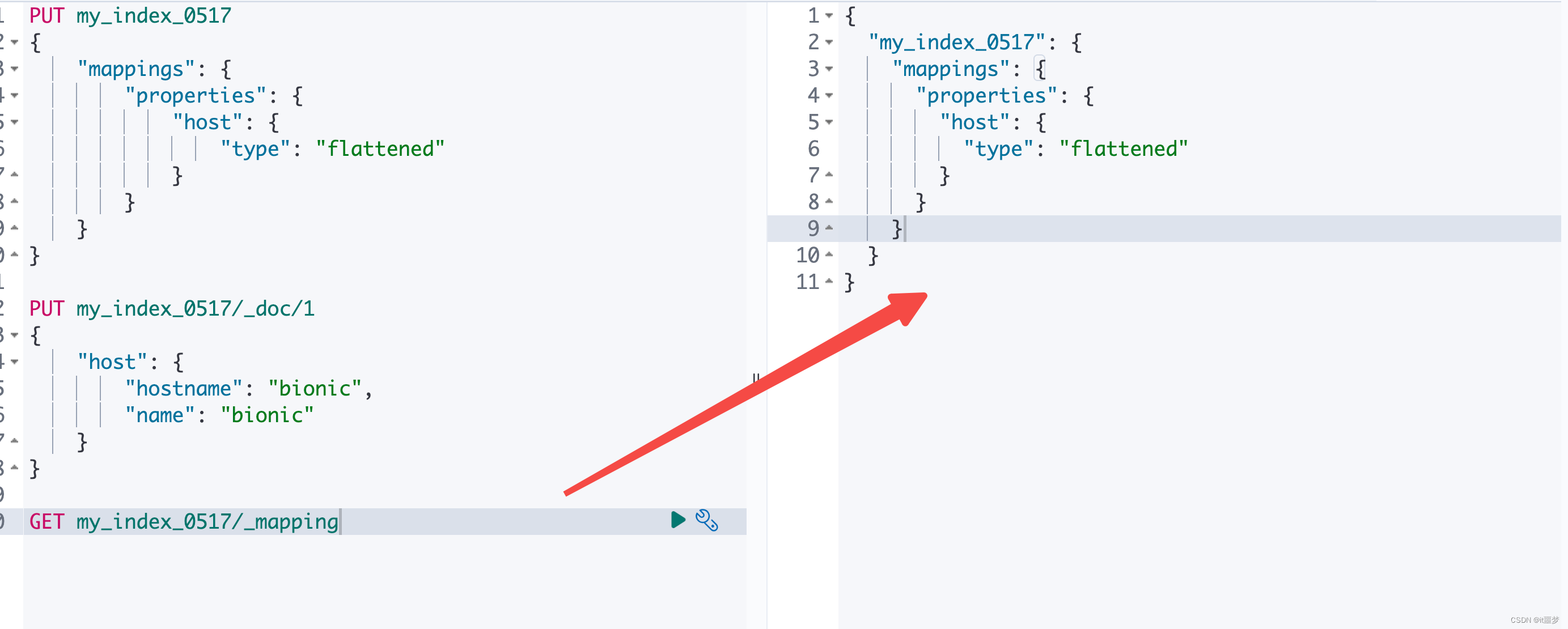
PUT my_index_0517
{"mappings": {"properties": {"host": {"type": "flattened"}}}
}Flattened的本质是将原来一个复杂的Object或者Nested嵌套多字段类型统一映射为扁平的单字段类型。这里要强调的是:不管原来内嵌多少个字段、内嵌多少层,利用Flattened类型都能一下“拉平”
基于Flattened类型插入数据
基于上面所说的映射,写入一条数据如下。
PUT my_index_0517/_doc/1
{"host": {"hostname": "bionic","name": "bionic"}
}
由于将host字段设置为Flattened,hostname、name字段都不再映射为特定嵌套子字段。
更新Flattened字段并添加数据
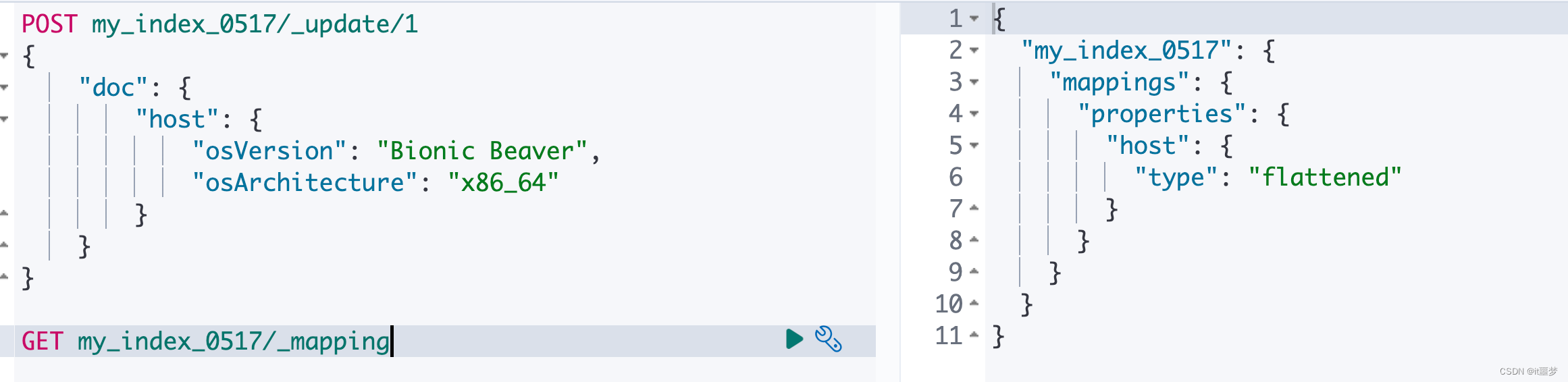
POST my_index_0517/_update/1
{"doc": {"host": {"osVersion": "Bionic Beaver","osArchitecture": "x86_64"}}
}再次查看映射结构,它依然“岿然不动”。继续使用Flattened,既没有字段扩增,也不会有mapping爆炸出现。
Flattened类型检索
以下两种检索方式都会召回数据。
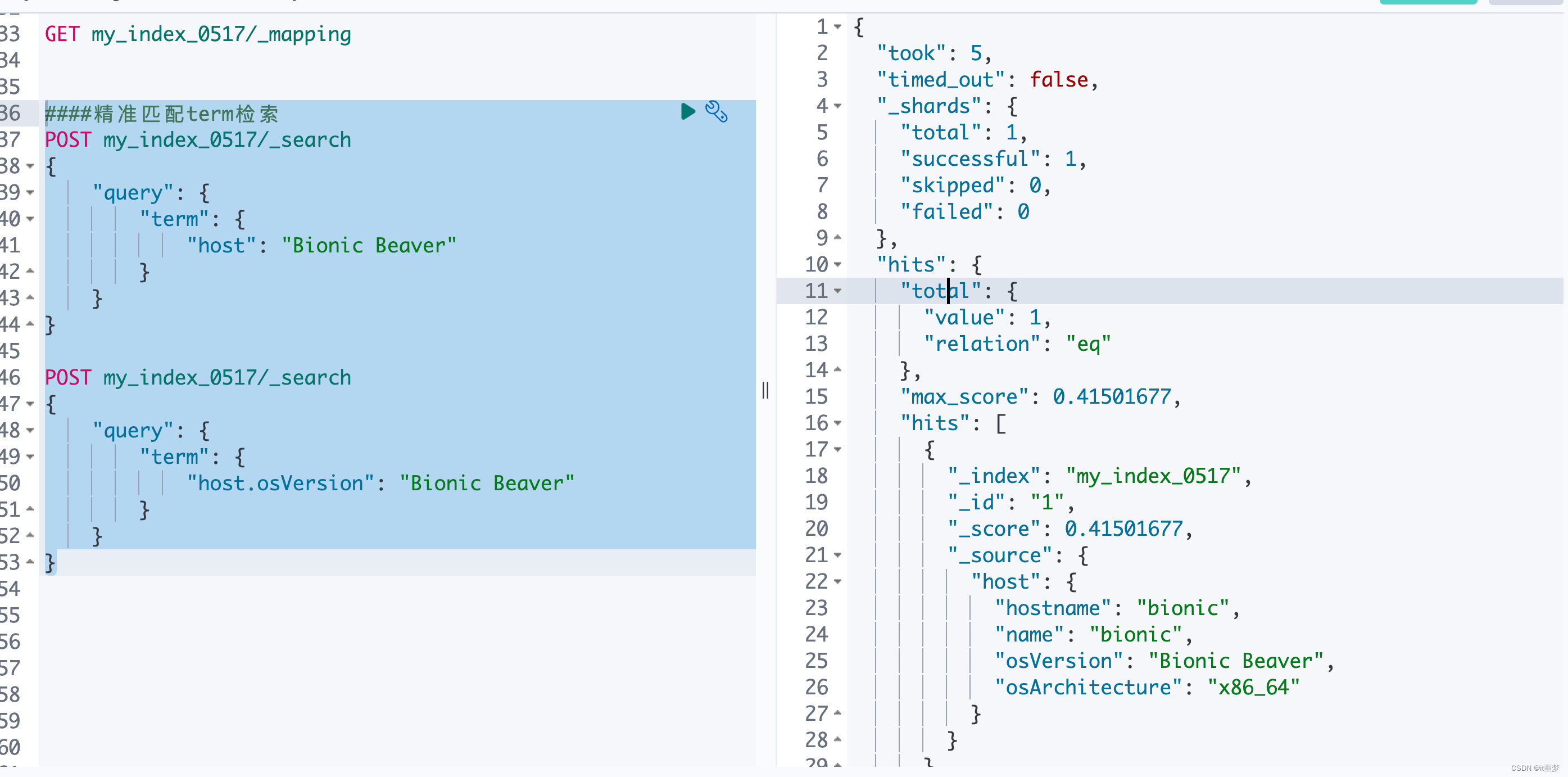
####精准匹配term检索
POST my_index_0517/_search
{"query": {"term": {"host": "Bionic Beaver"}}
}POST my_index_0517/_search
{"query": {"term": {"host.osVersion": "Bionic Beaver"}}
}
而如下检索的返回结果为空。
POST my_index_0517/_search
{"query": {"term": {"host.osVersion": "bionic Beaver"}}
}POST my_index_0517/_search
{"query": {"term": {"host.osVersion": "Bionic"}}
}这是为什么呢?由于使用Flattened类型,Elasticsearch未对该字段进行分词等处理,因此它只会返回匹配字母大小写且完全一致的结果。所以,如上检索结果和keyword类型检索结果一致。这也初步暴露出Flattened类型的部分缺陷。
Flattened类型的不足
面对Flattened对象,在进行Elasticsearch扁平化数据类型的选型时,我们需要考虑以下几个关键限制。
1)Flattened类型支持的查询类型目前仅限于以下几种:term、terms、terms_set、prefix、range、match、multi_match、query_string、simple_query_string、exists。
2)Flattened不支持的查询类型如下。
❑无法执行涉及数字计算的查询,例如range检索。
❑无法支持高亮查询。
❑尽管支持诸如term聚合之类的聚合,但不支持处理诸如histograms或date_histograms之类的数值数据的聚合。
这篇关于Elasticsearch解决字段膨胀问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







