本文主要是介绍【爬虫之scrapy框架——尚硅谷(学习笔记one)--基本步骤和原理+爬取当当网(基本步骤)】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬虫之scrapy框架——基本原理和步骤+爬取当当网(基本步骤)
- 下载scrapy框架
- 创建项目(项目文件夹不能使用数字开头,不能包含汉字)
- 创建爬虫文件
- (1)第一步:先进入到spiders文件中(进入相应的位置)
- (2)第二步:创建爬虫文件
- (3)第三步:查看创建的项目文件——检查路径是否正确
- 运行爬虫代码
- 查看robots协议——是否有反爬取机制——君子协议(修改君子协议)
- (1)查看某网站的君子协议
- (2)修改settings文件中君子协议
- scrapy项目的结构
- response的常用属性和方法
- scrapy框架原理解析
- scrapy sell 工具调试——具体下载不说明
- 当当网爬取案例
- 1. 创建当当网爬虫项目
- 2. 检查网址
- 3. 在函数中打印一条数据,看是否网站有反爬机制
- 4. 定义数据结构——选择要爬取哪些属性
- 5. 去网址分析数据——拿到xpath表达式
- (1)拿到图片
- (2)拿到名字
- (3)拿到价格
- 6. 编写函数
- 7.运行后拿到数据
- 8.保存数据
- (1)封装数据——yield提交给管道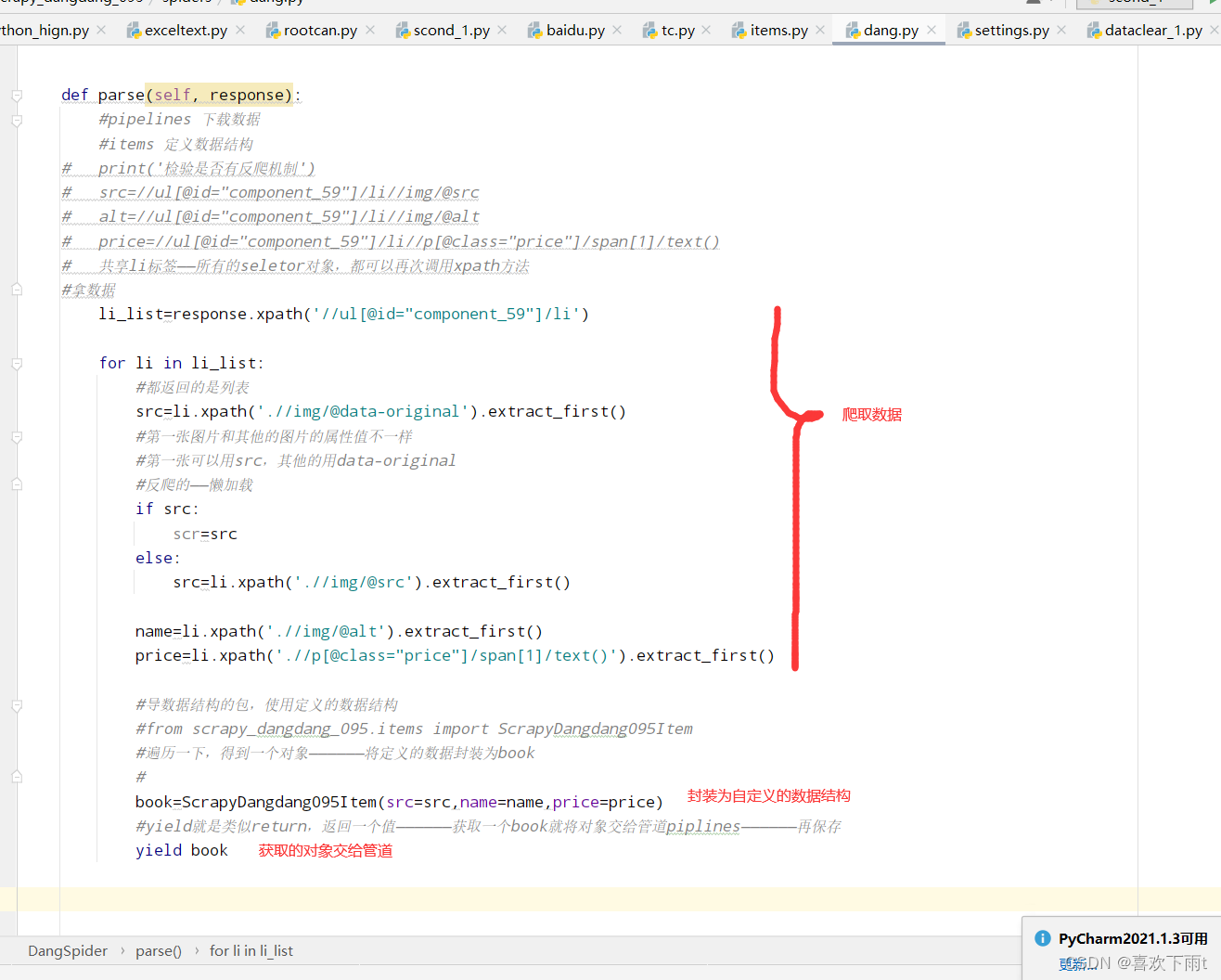
- (2)开启管道——保存内容
- 9.多条管道下载
- (1)定义管道类
- (2)在settings中开启管道
- 10.多页数据的下载
- (1)定义一个基本网址和page
- (2)重新调用def parse(self, response):函数——编写多页请求
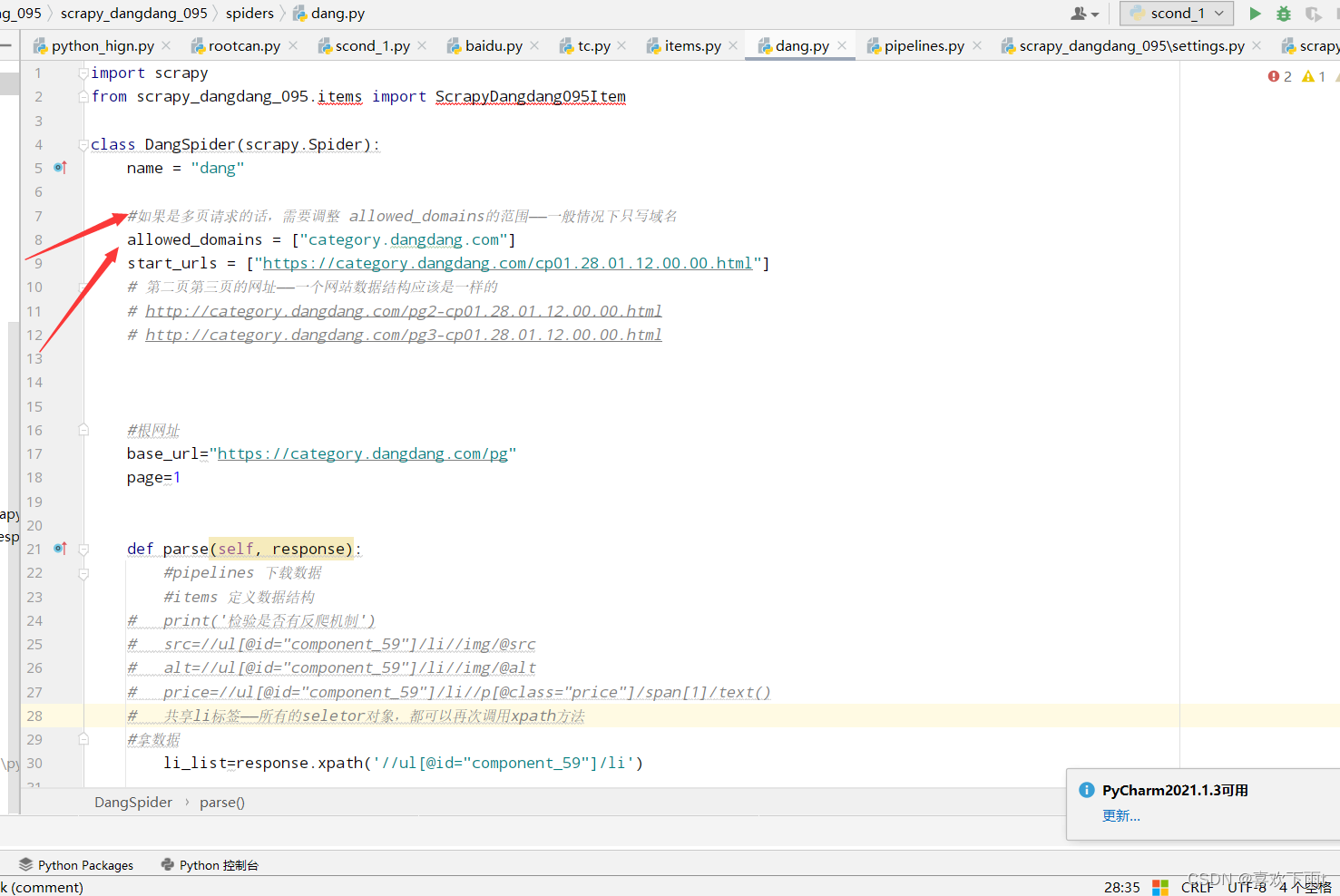
- (3)修改allowed_domains的范围——一半多页请求范围编写域名即可
- 11.爬取核心代码
下载scrapy框架
scrapy安装视频链接
创建项目(项目文件夹不能使用数字开头,不能包含汉字)
cmd:
scrapy startproject 项目名称
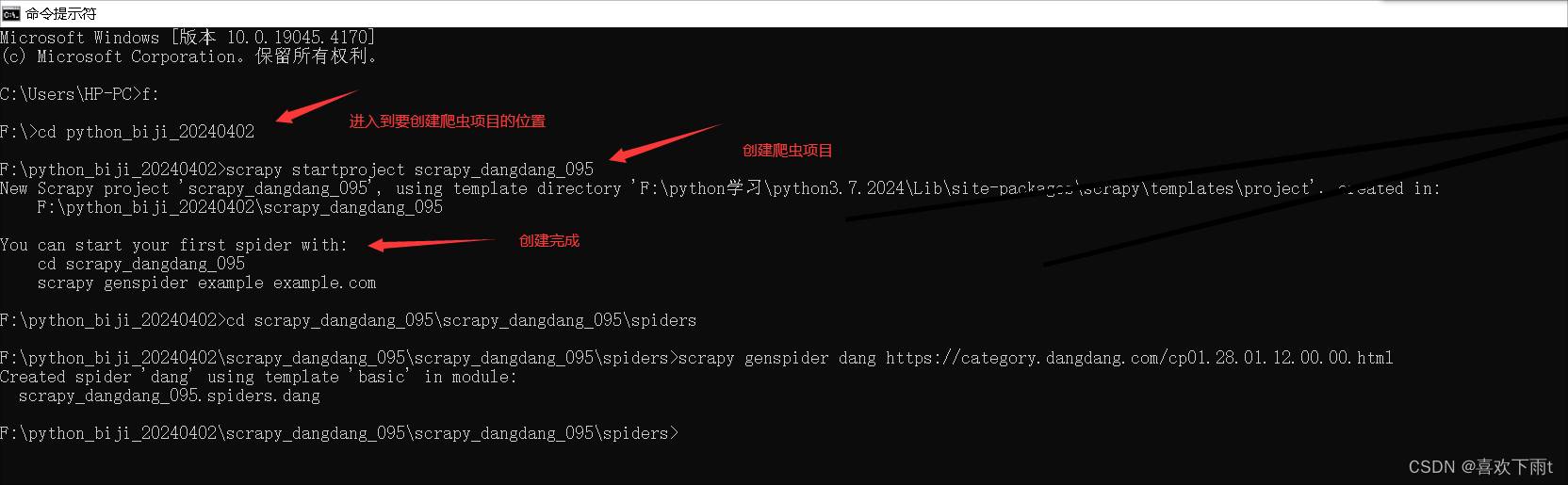
创建爬虫文件
(1)第一步:先进入到spiders文件中(进入相应的位置)
cd 项目的名字\项目的名字\spiders
(2)第二步:创建爬虫文件
scrapy genspider 爬虫文件的名字 要爬取的网页网址
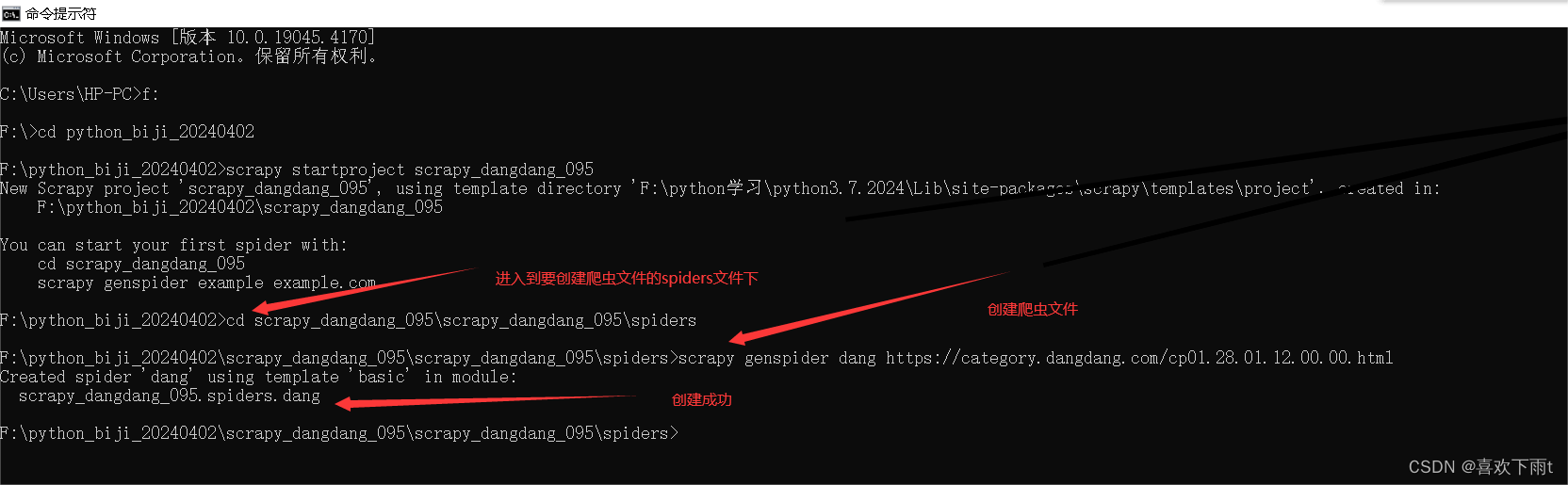
(3)第三步:查看创建的项目文件——检查路径是否正确
注意:不满足时需要手动修改(版本不同,造成的结果不一)
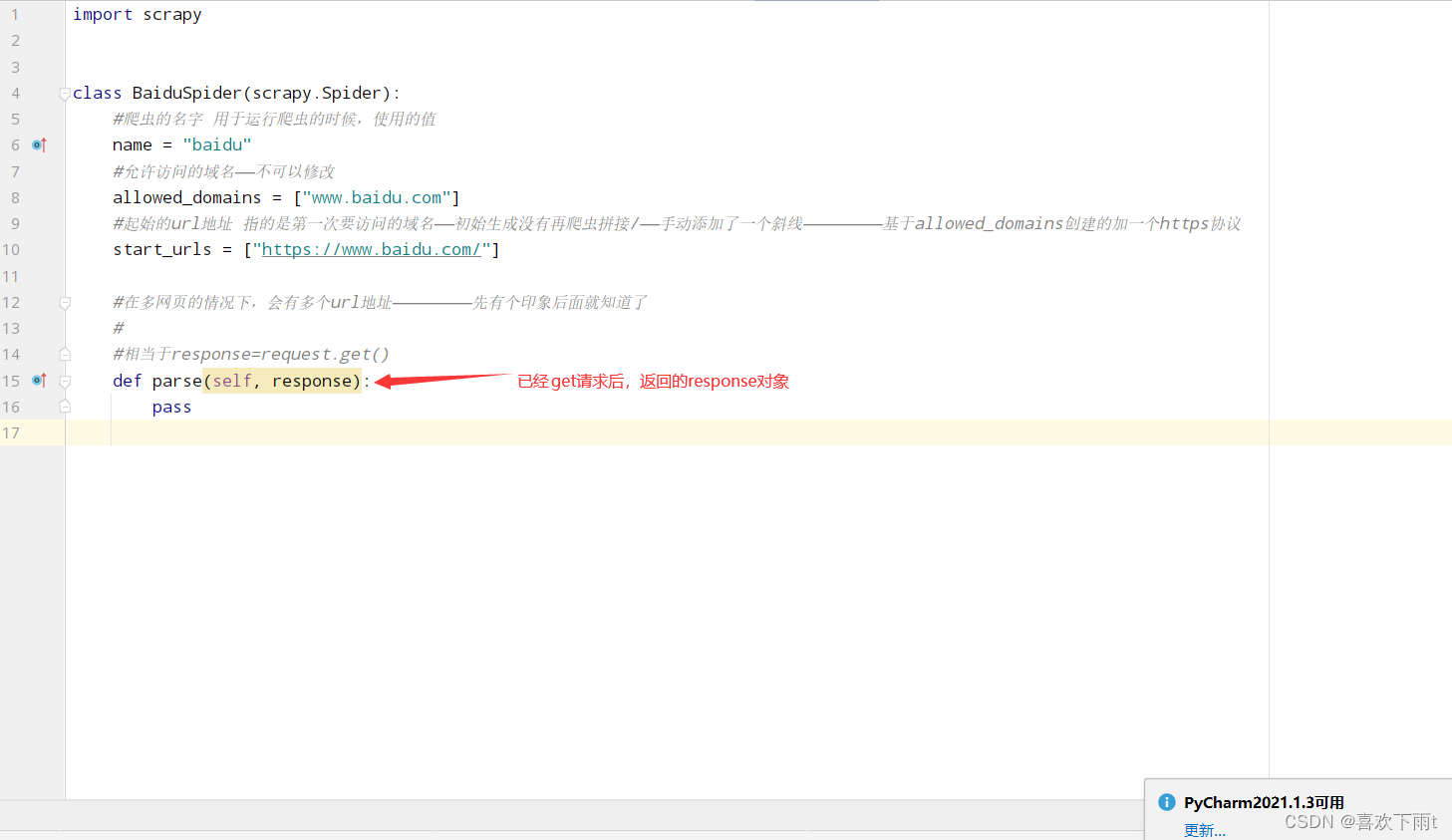
运行爬虫代码
scrapy crawl 爬虫的名字
查看robots协议——是否有反爬取机制——君子协议(修改君子协议)
(1)查看某网站的君子协议
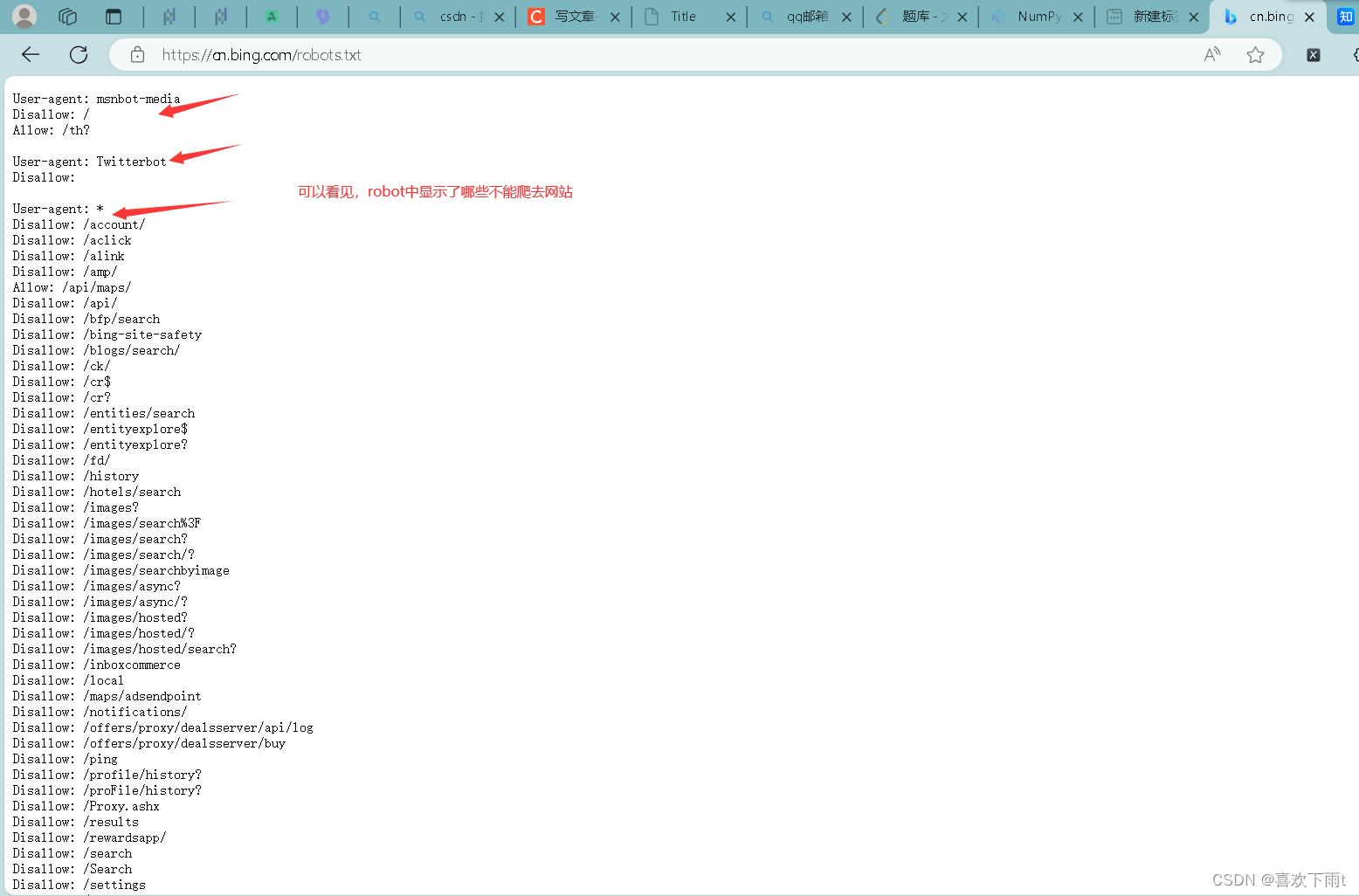
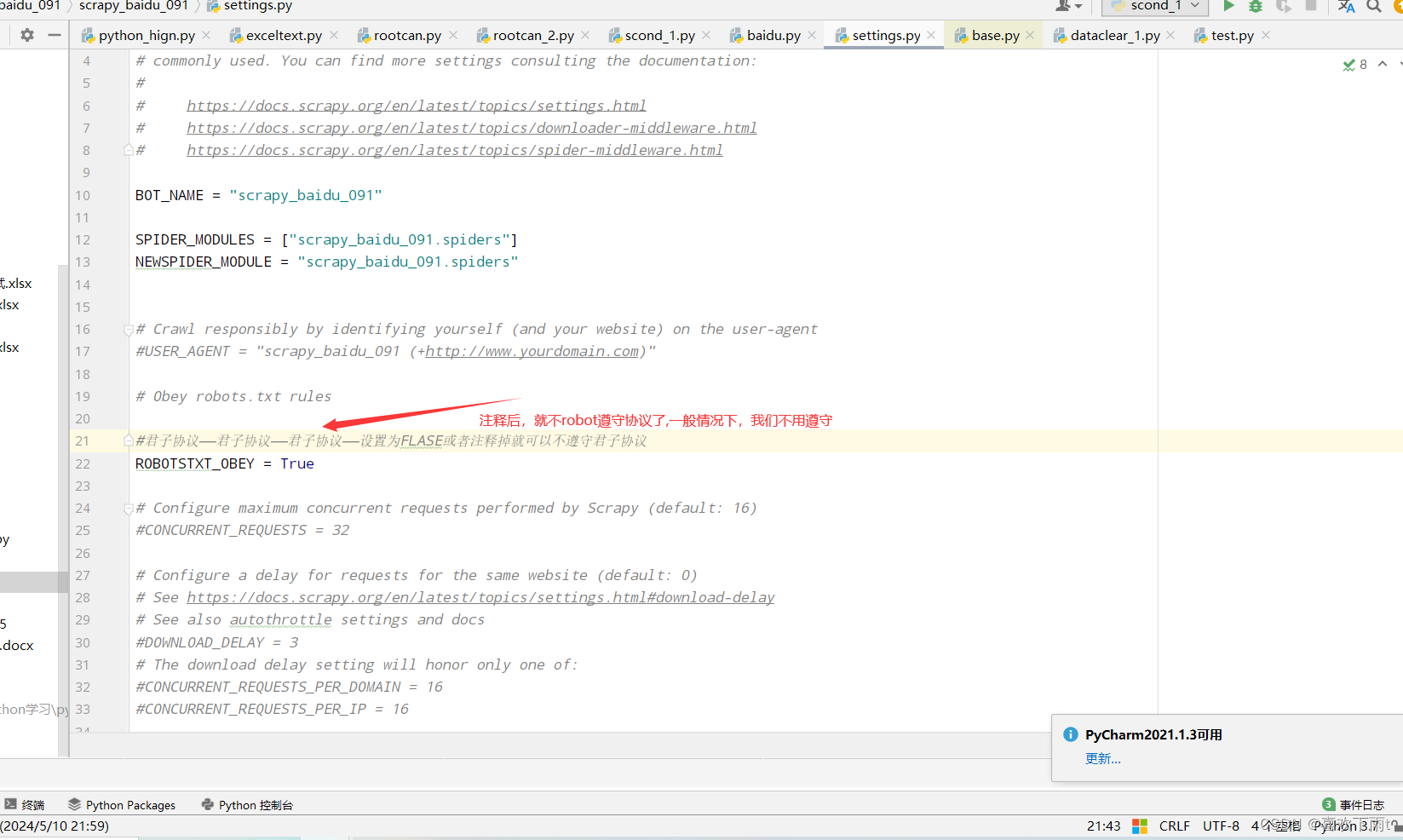
(2)修改settings文件中君子协议
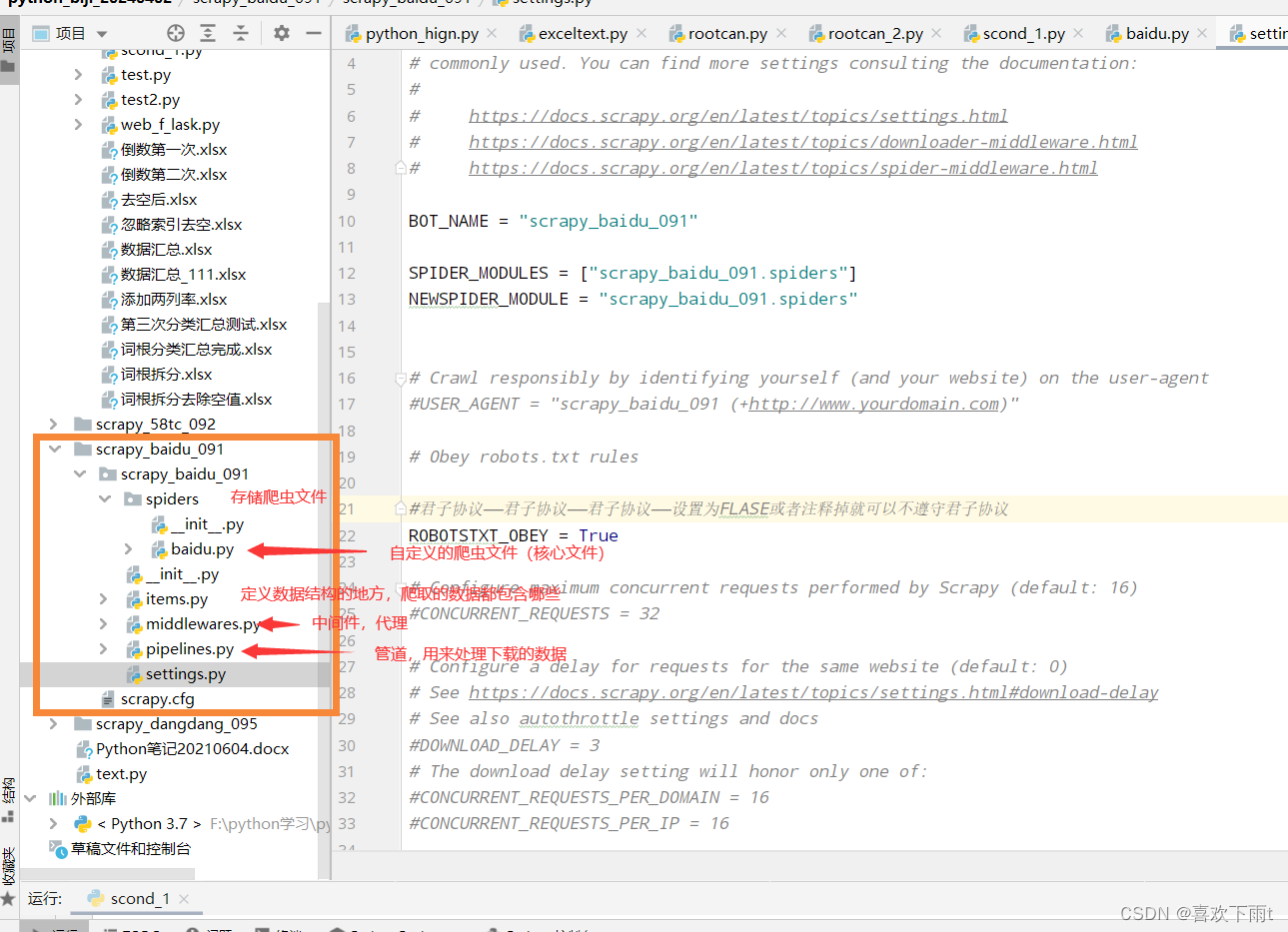
scrapy项目的结构
response的常用属性和方法
(1)爬去网站的源码数据
content_1=response.txt
(2)爬去网站的二进制源码数据
response.body
(3)xpath方法可以用来解析response中的内容
response.xpath('')
(4)extract方法用来提取seletor对象的data属性值
response.extract()
(5)extract_first方法用来提取seletor列表的第一个数据
response.extract()
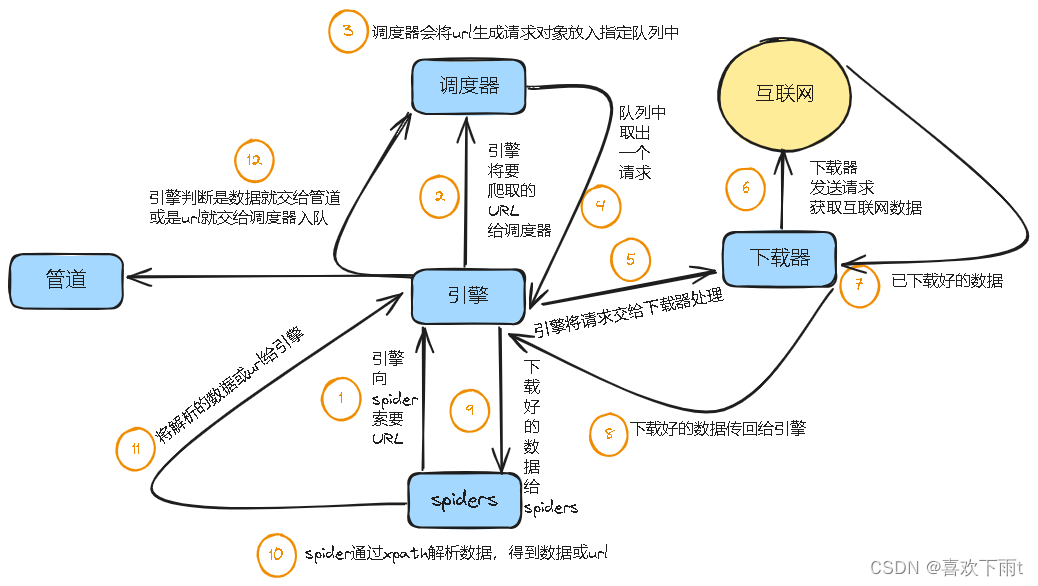
scrapy框架原理解析
scrapy sell 工具调试——具体下载不说明
(1)进入scrapy shell工具
scrapy shell 网址
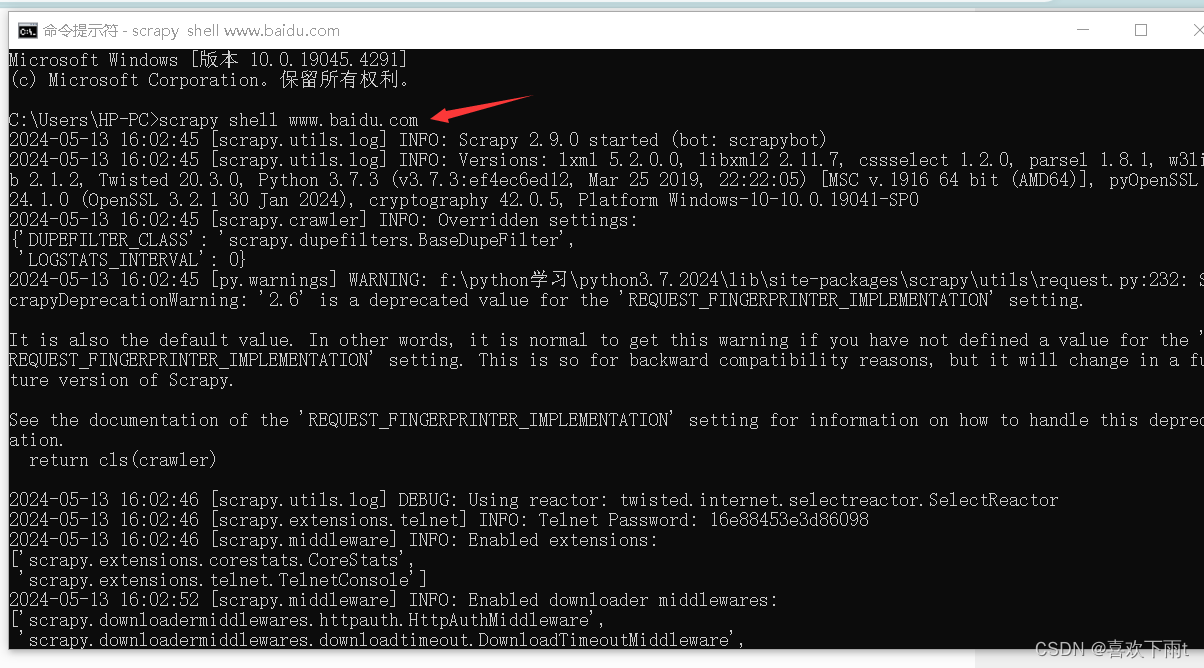
(2)可以看见有一个response对象
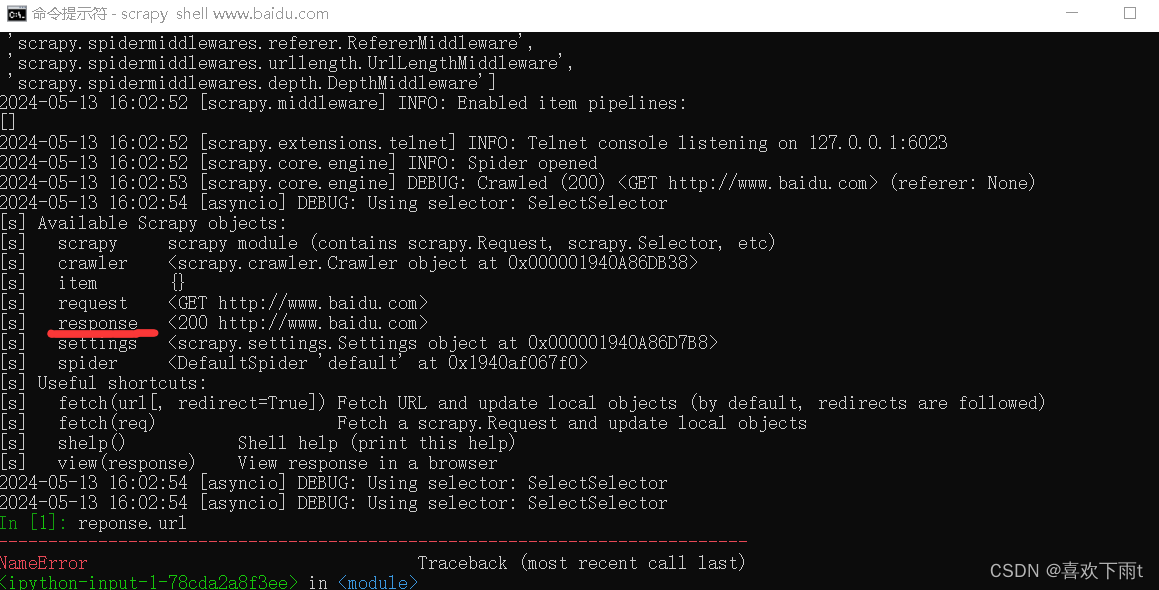
(3)可以对response对象进行操作调试(不用像项目一样每次多要运行项目,减少麻烦)
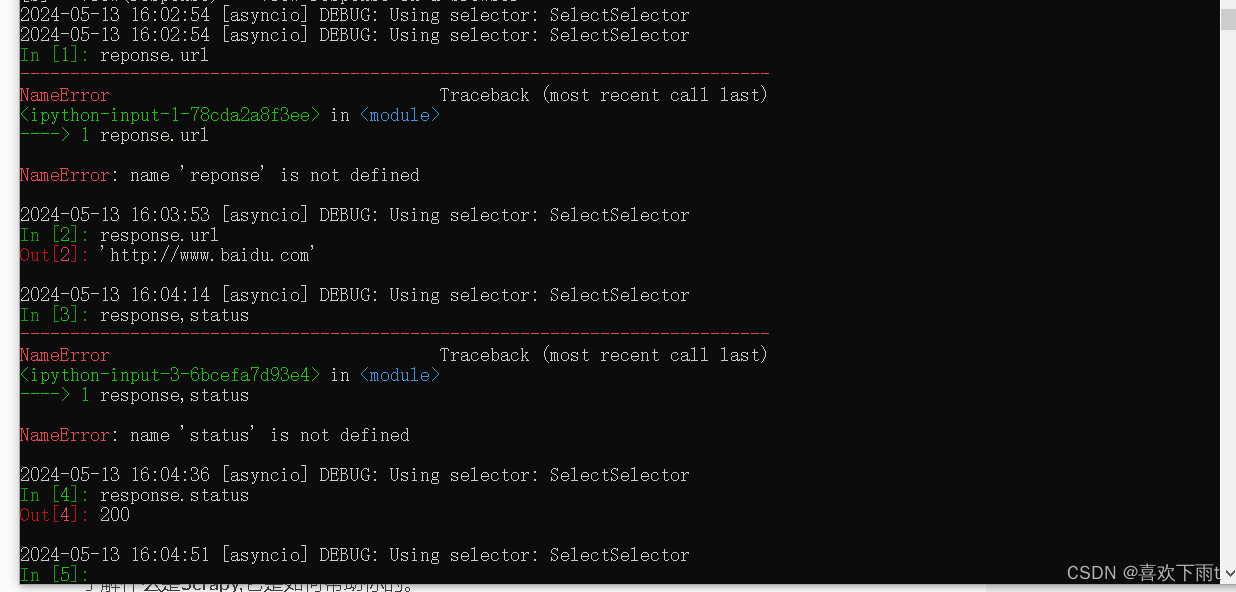
当当网爬取案例
1. 创建当当网爬虫项目
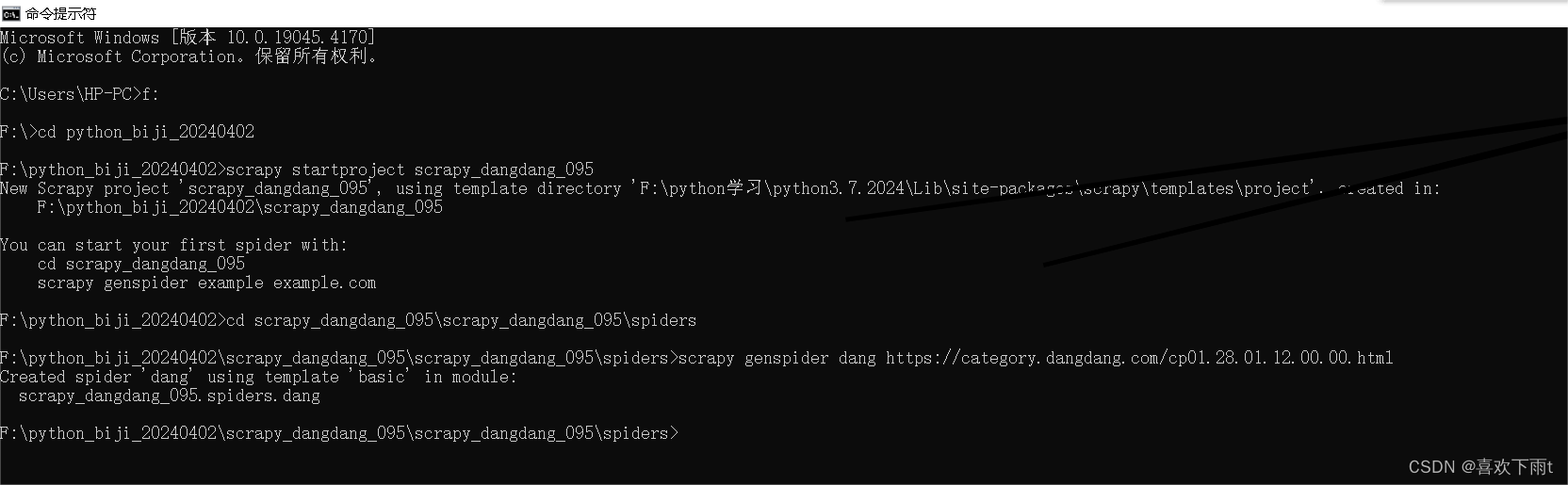
2. 检查网址
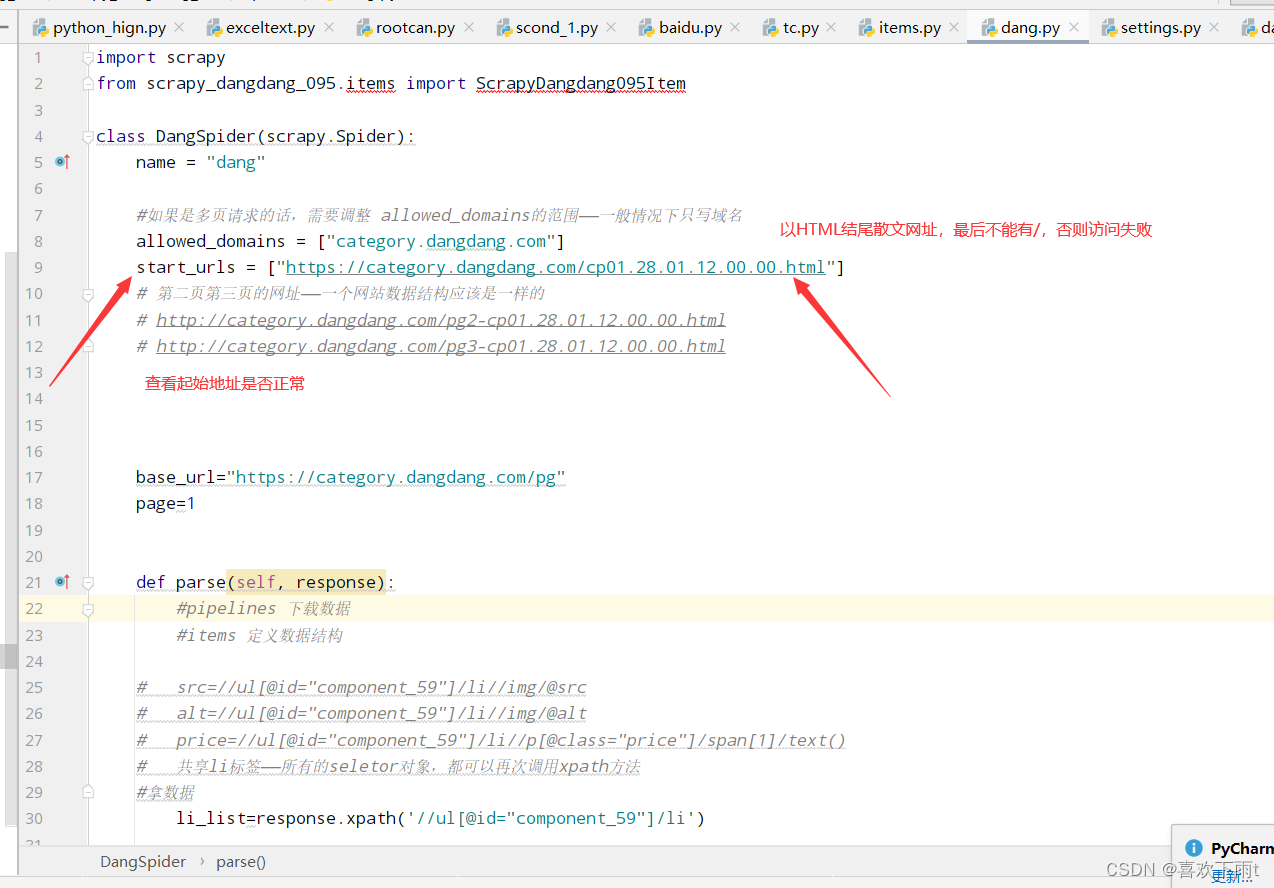
3. 在函数中打印一条数据,看是否网站有反爬机制
图1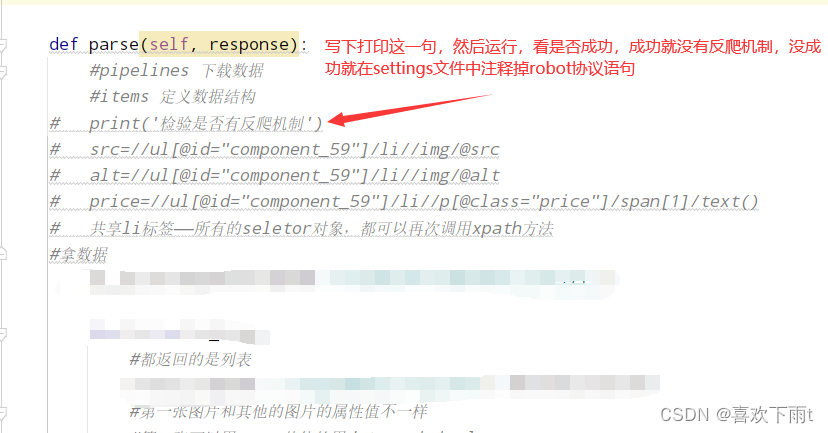
图2
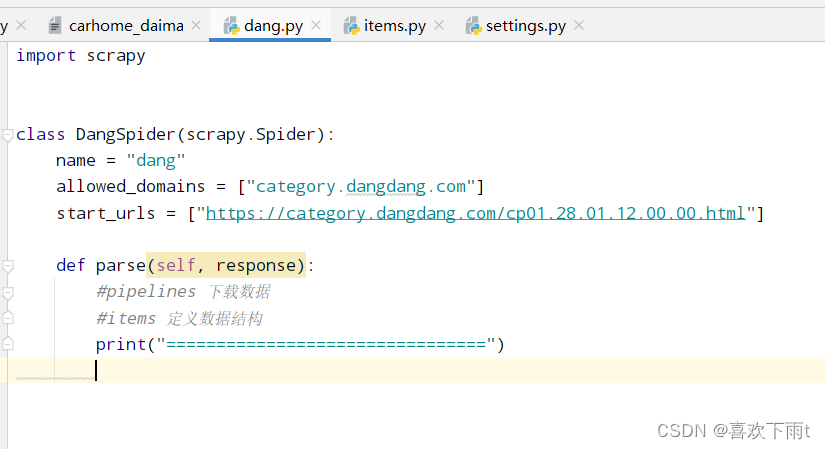
4. 定义数据结构——选择要爬取哪些属性
5. 去网址分析数据——拿到xpath表达式
(1)拿到图片
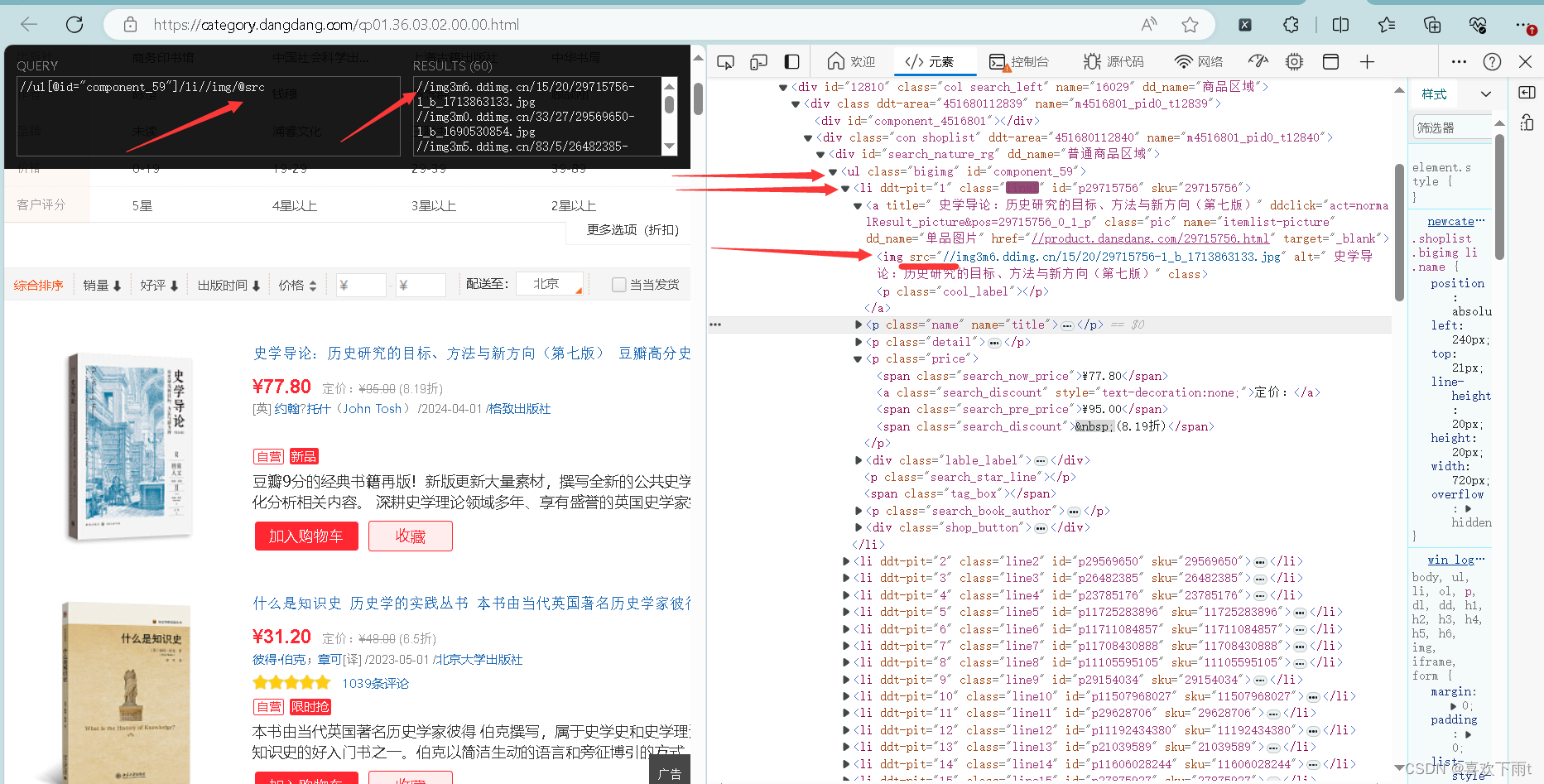
(2)拿到名字
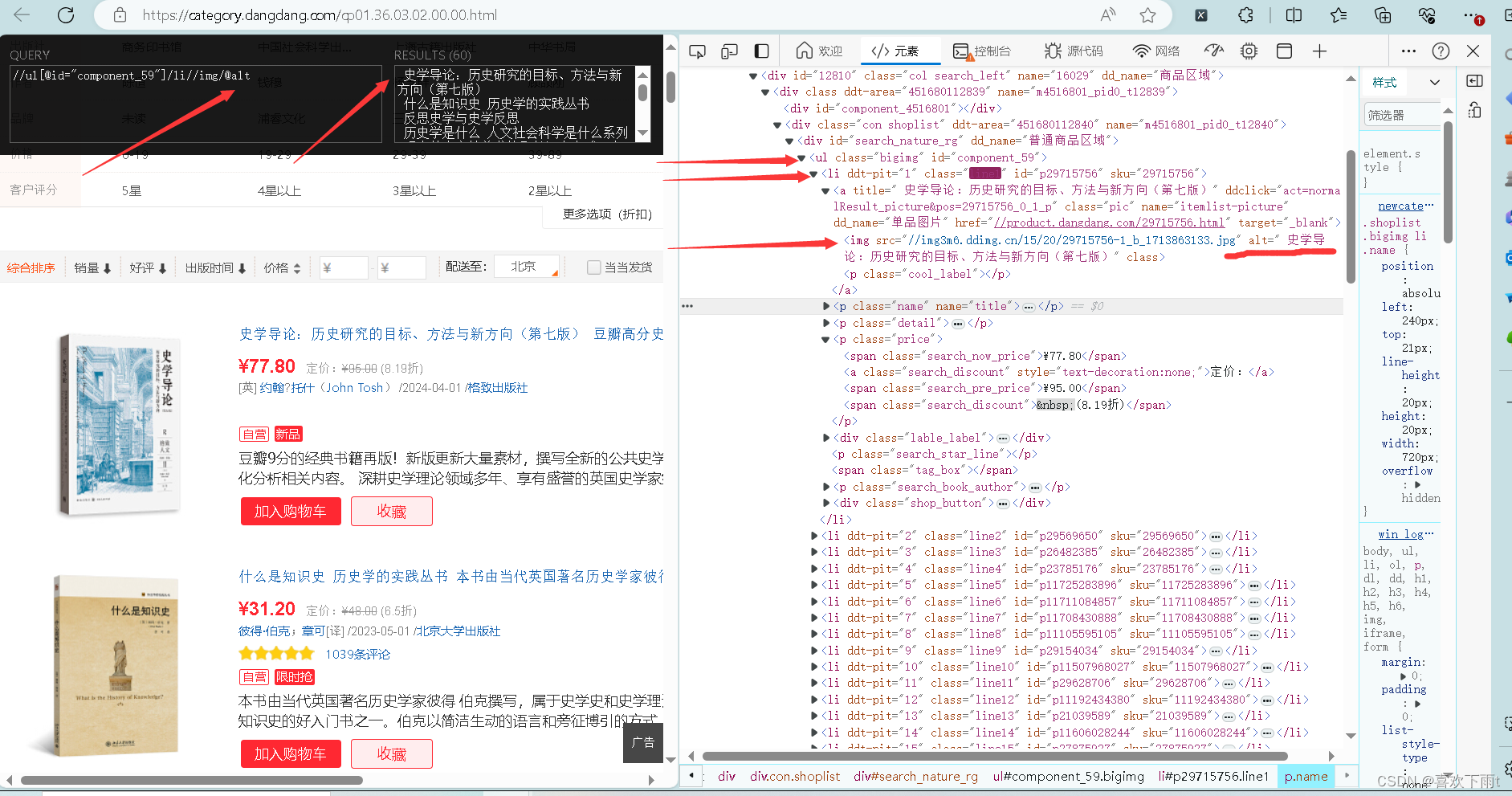
(3)拿到价格
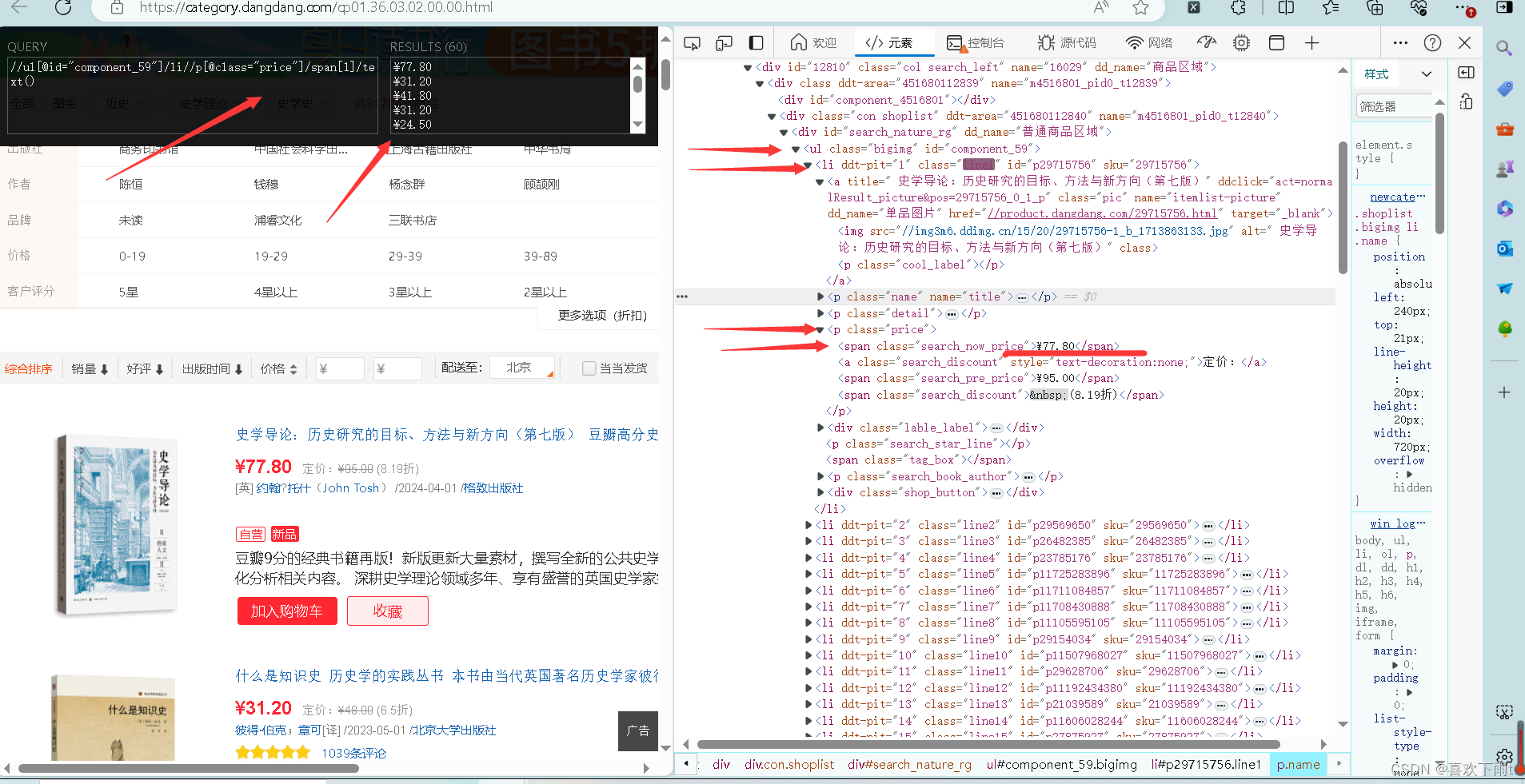
6. 编写函数
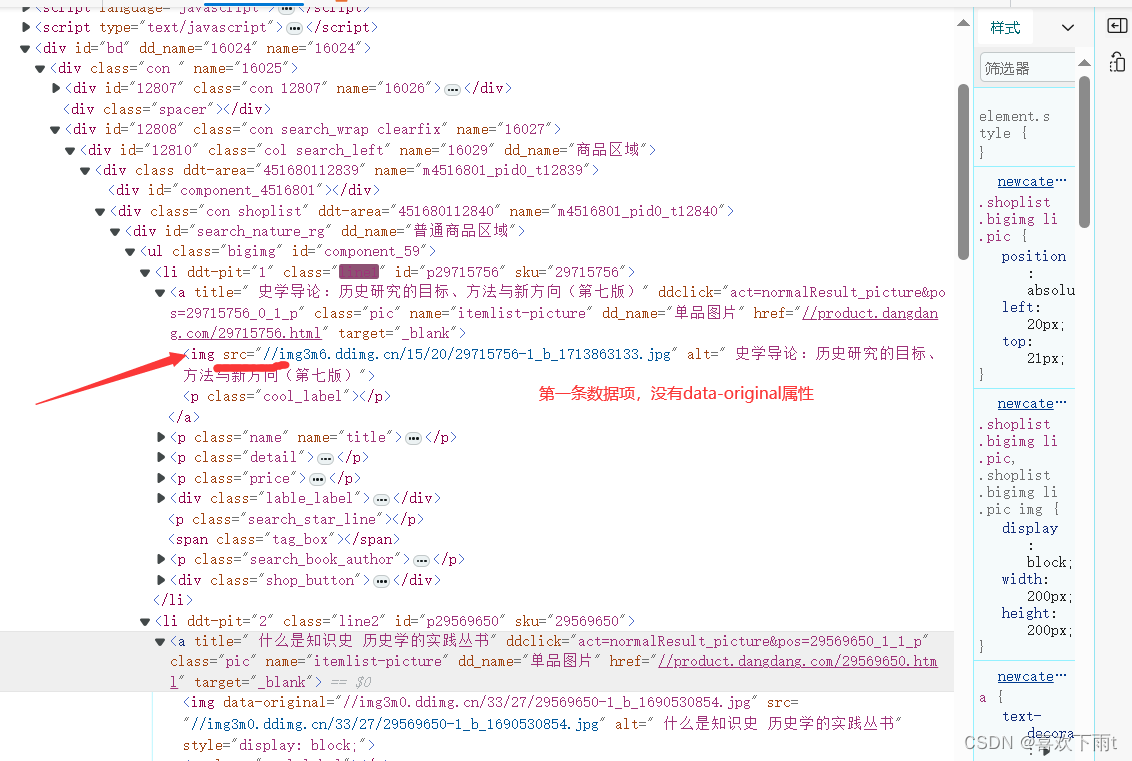
(1)懒加载处理
图1——非第一张图片(懒加载——有data-original)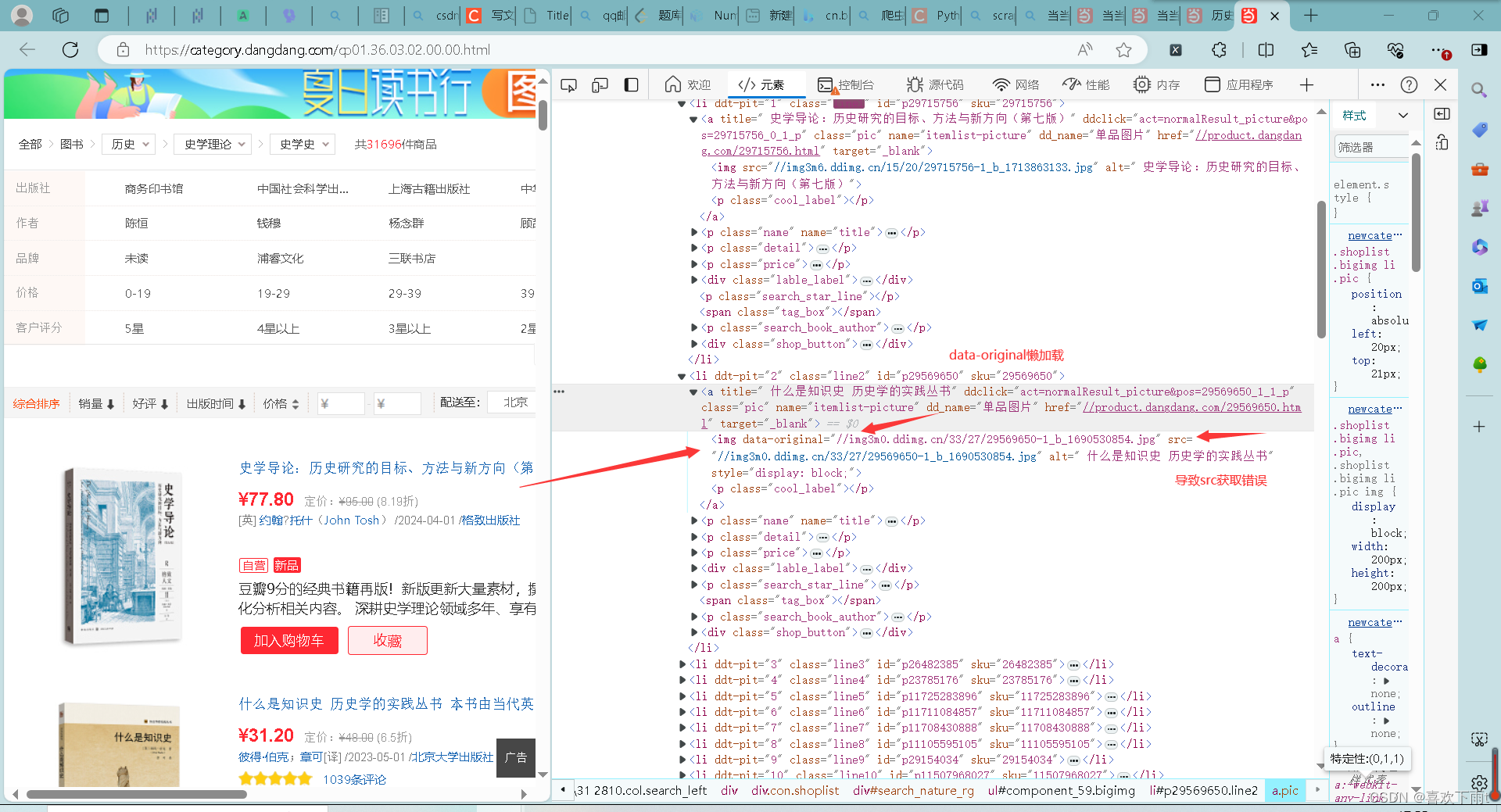 图2——第一张图片和其他的图片的属性值不一样
图2——第一张图片和其他的图片的属性值不一样
注:第一张可以用src,其他的用data-original
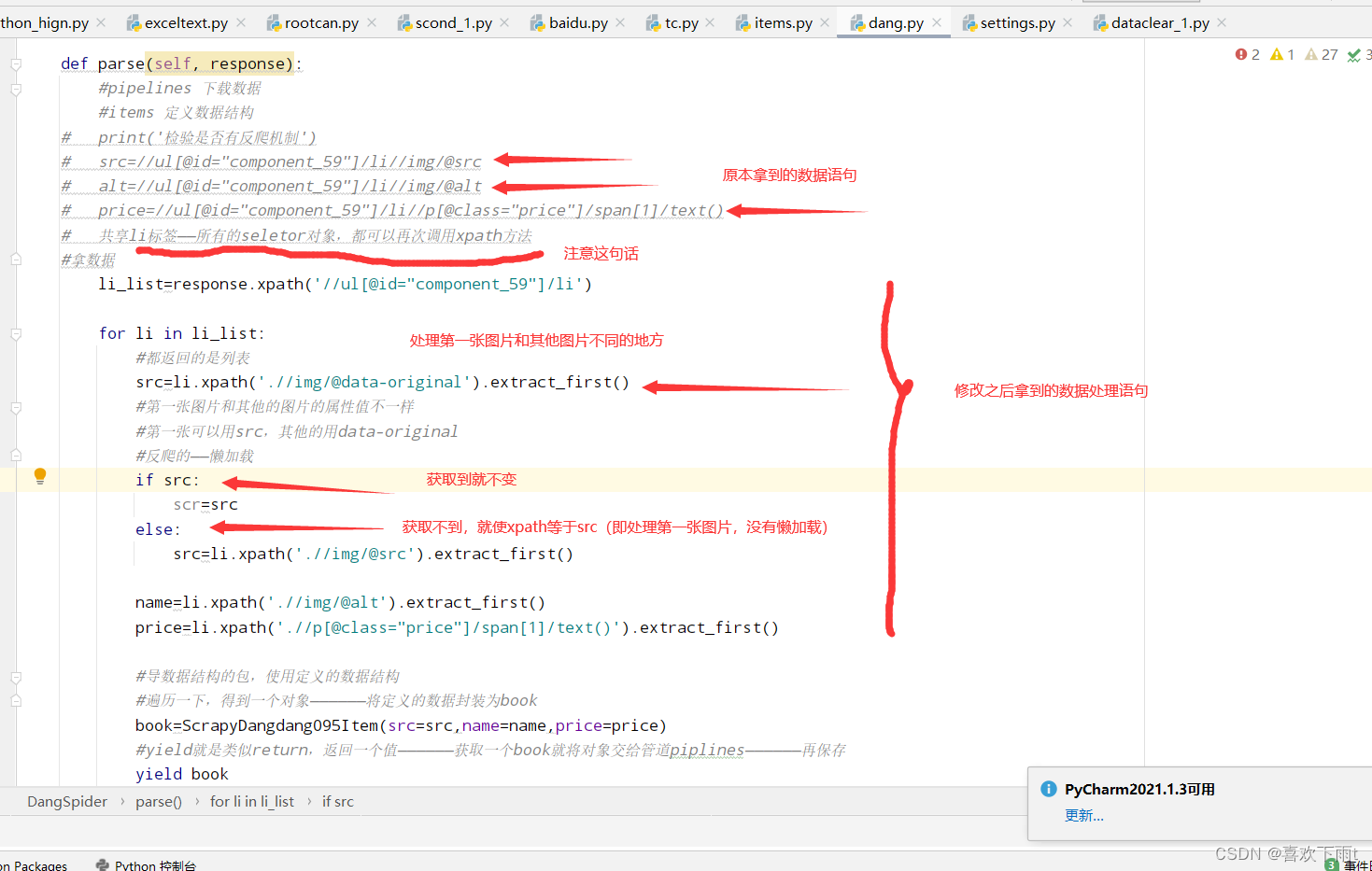
(2)代码解释如图:
7.运行后拿到数据
scrapy crawl 爬虫的名字
8.保存数据
(1)封装数据——yield提交给管道
(2)开启管道——保存内容
图1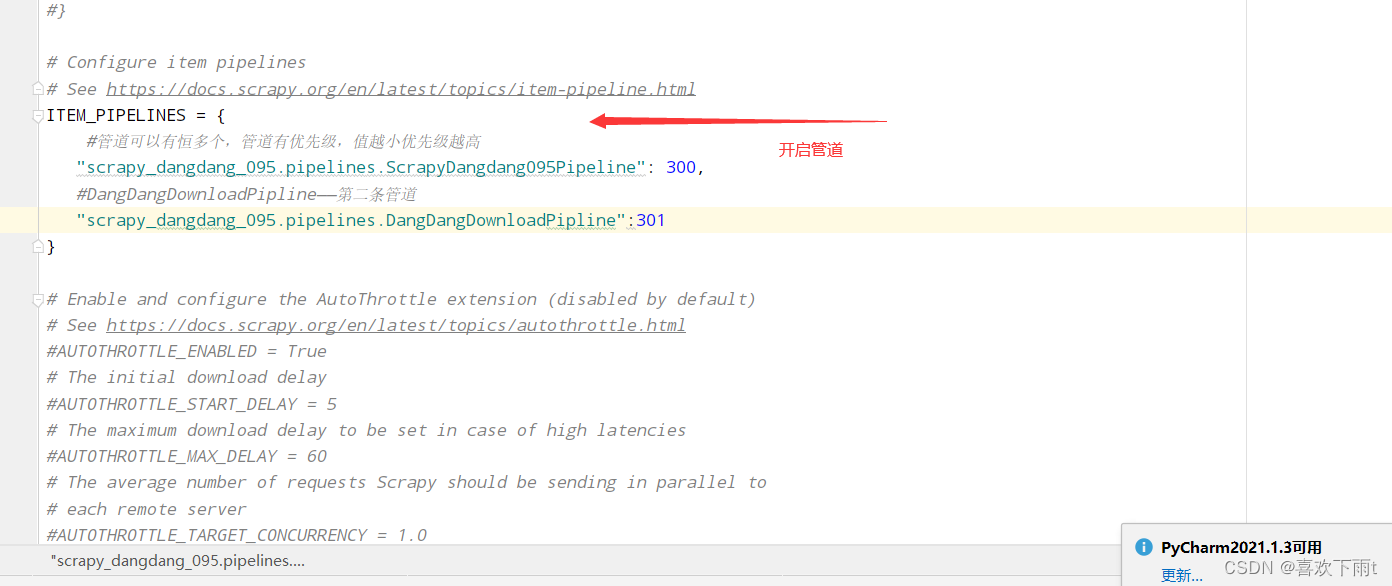
图2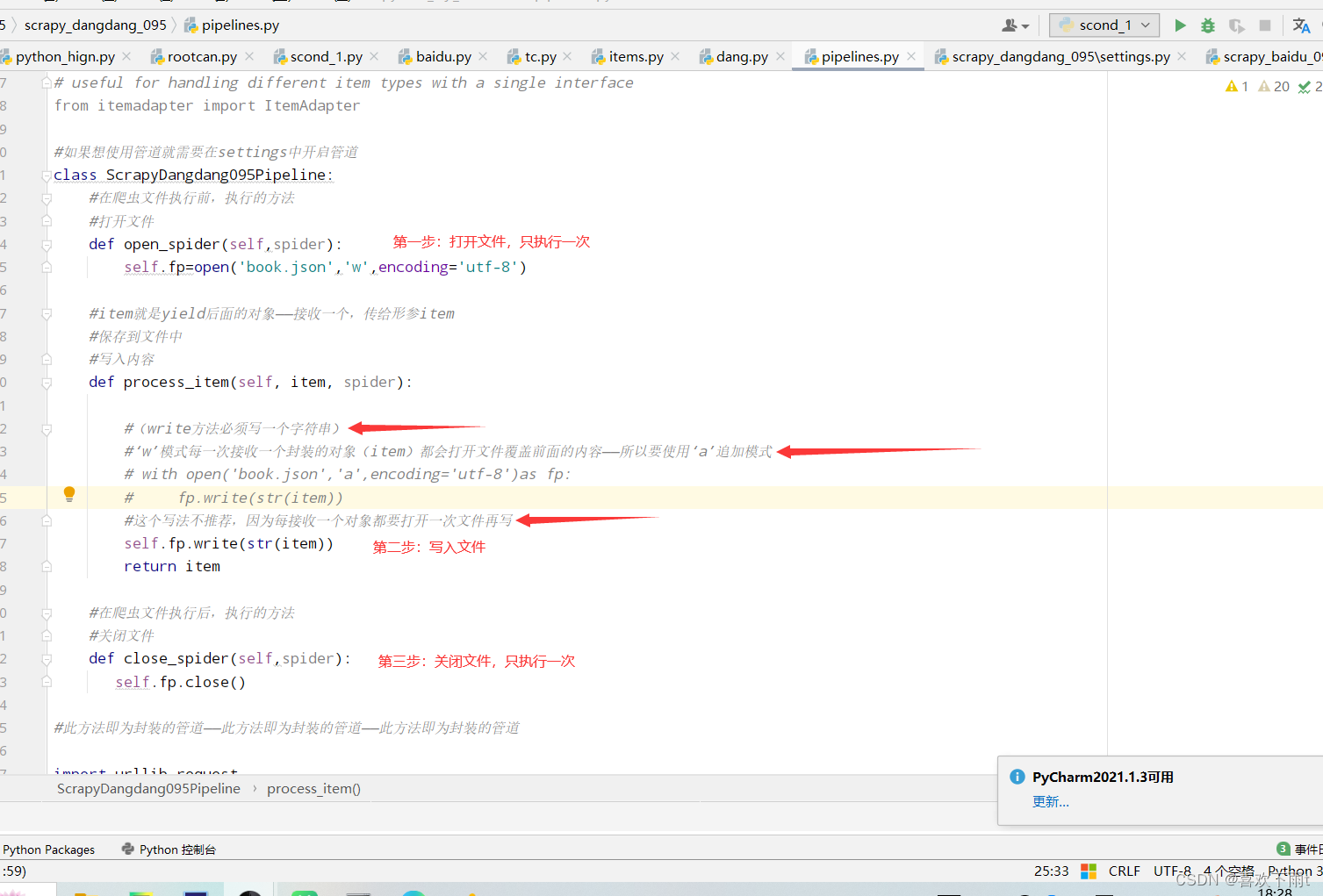
9.多条管道下载
(1)定义管道类
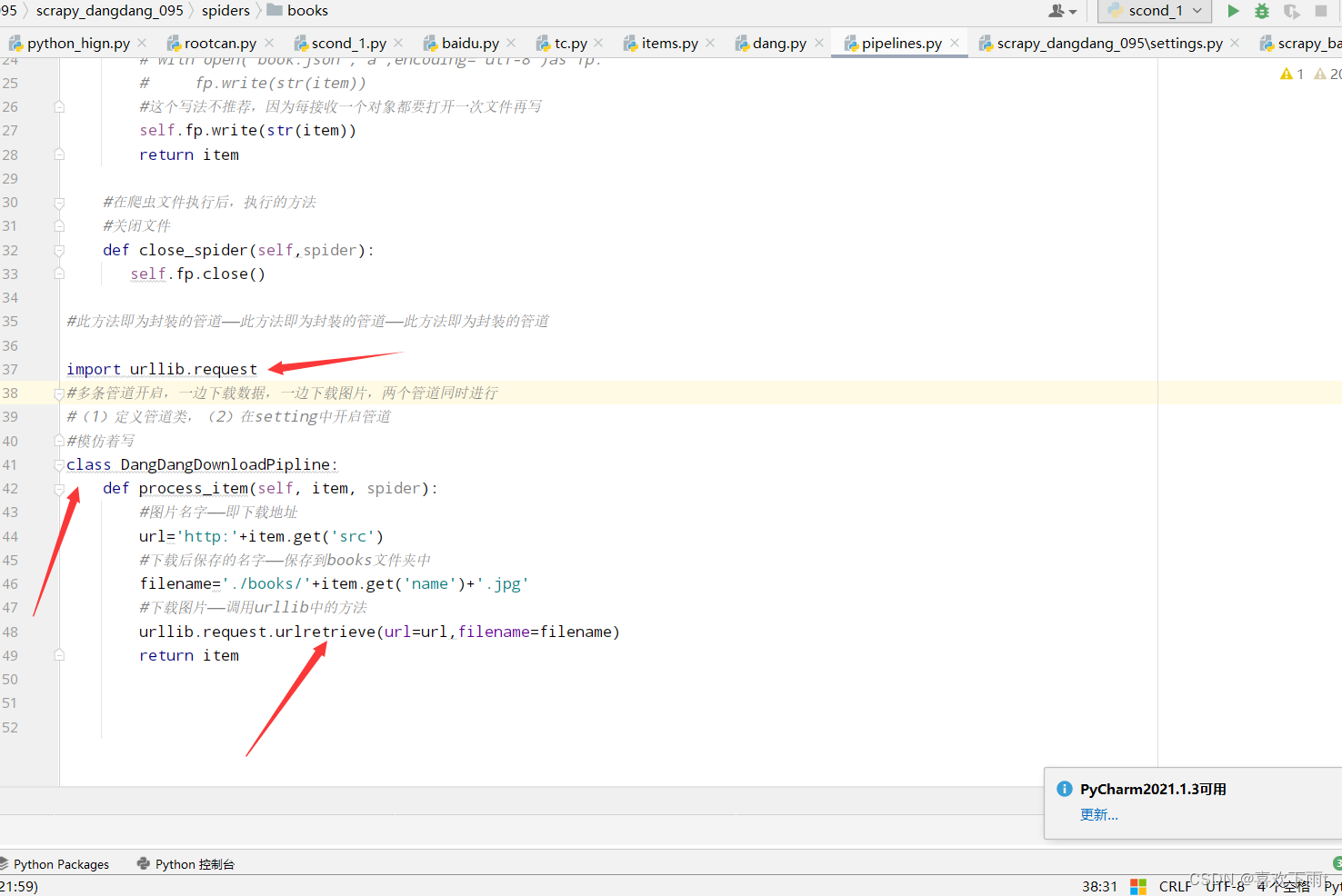
(2)在settings中开启管道
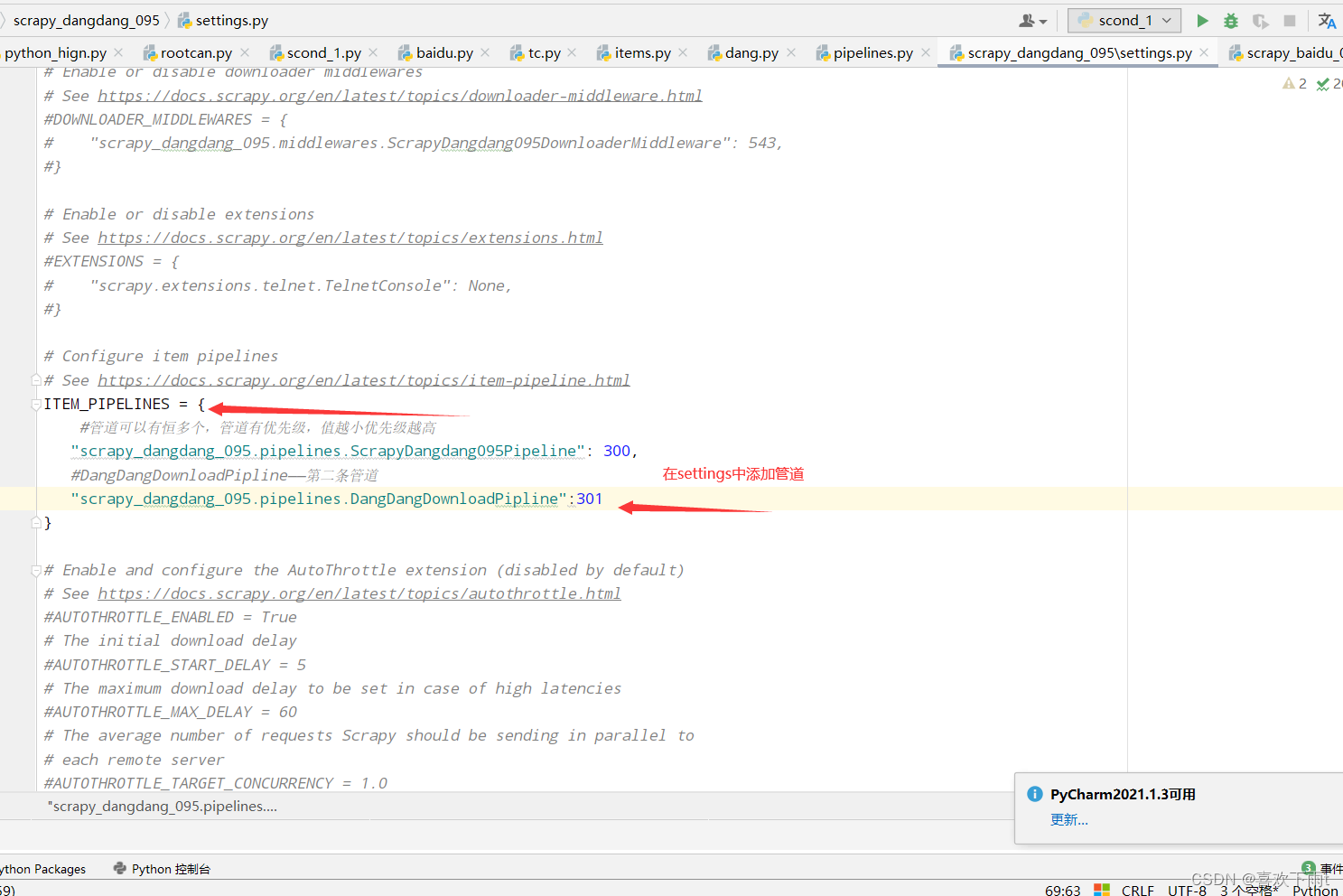
10.多页数据的下载
(1)定义一个基本网址和page
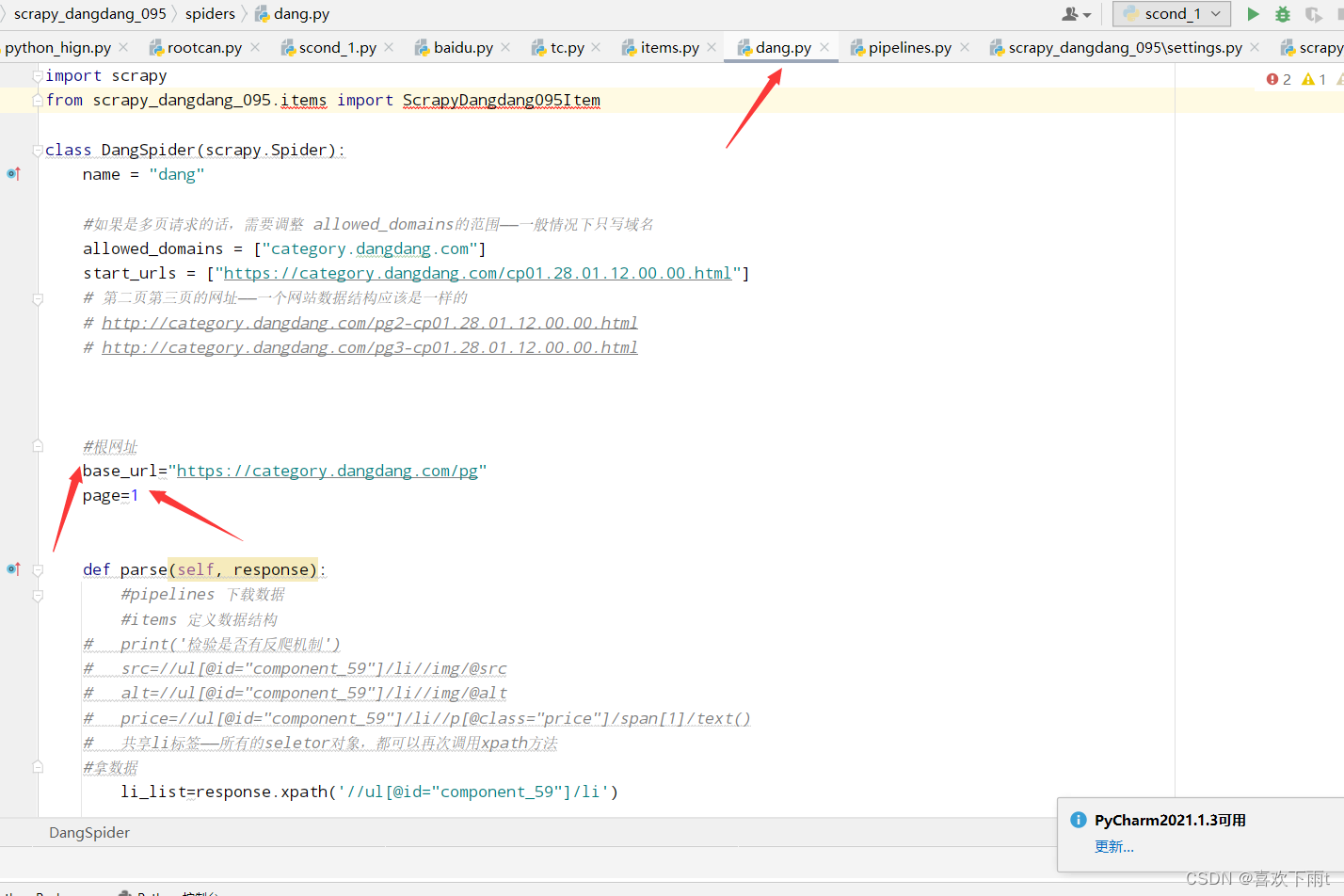
(2)重新调用def parse(self, response):函数——编写多页请求
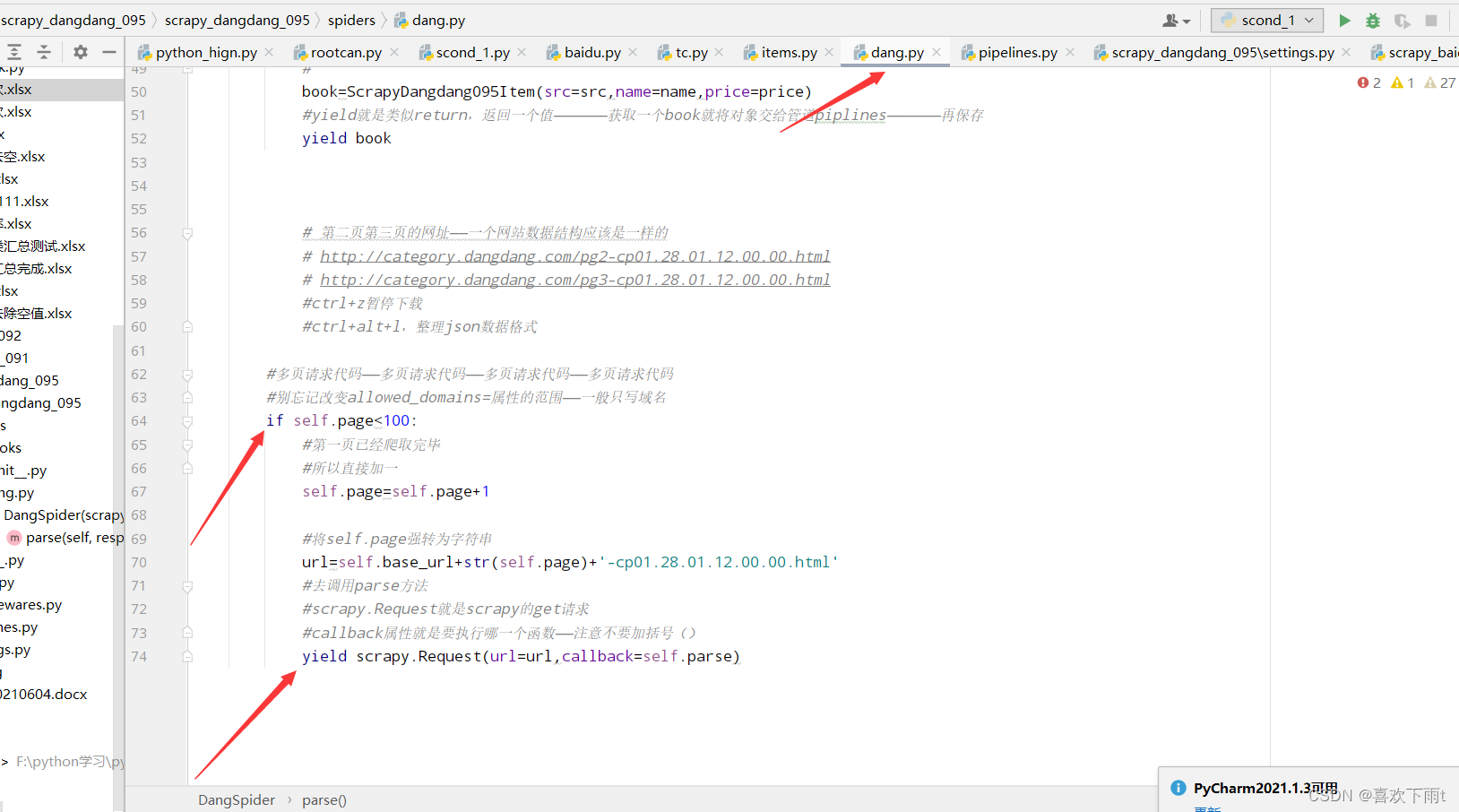
(3)修改allowed_domains的范围——一半多页请求范围编写域名即可
11.爬取核心代码
import scrapy
from scrapy_dangdang_095.items import ScrapyDangdang095Itemclass DangSpider(scrapy.Spider):name = "dang"#如果是多页请求的话,需要调整 allowed_domains的范围——一般情况下只写域名allowed_domains = ["category.dangdang.com"]start_urls = ["https://category.dangdang.com/cp01.28.01.12.00.00.html"]# 第二页第三页的网址——一个网站数据结构应该是一样的# http://category.dangdang.com/pg2-cp01.28.01.12.00.00.html# http://category.dangdang.com/pg3-cp01.28.01.12.00.00.html#根网址base_url="https://category.dangdang.com/pg"page=1def parse(self, response):#pipelines 下载数据#items 定义数据结构# print('检验是否有反爬机制')# src=//ul[@id="component_59"]/li//img/@src# alt=//ul[@id="component_59"]/li//img/@alt# price=//ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()# 共享li标签——所有的seletor对象,都可以再次调用xpath方法#拿数据li_list=response.xpath('//ul[@id="component_59"]/li')for li in li_list:#都返回的是列表src=li.xpath('.//img/@data-original').extract_first()#第一张图片和其他的图片的属性值不一样#第一张可以用src,其他的用data-original#反爬的——懒加载if src:scr=srcelse:src=li.xpath('.//img/@src').extract_first()name=li.xpath('.//img/@alt').extract_first()price=li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()#导数据结构的包,使用定义的数据结构#from scrapy_dangdang_095.items import ScrapyDangdang095Item#遍历一下,得到一个对象——————将定义的数据封装为book#book=ScrapyDangdang095Item(src=src,name=name,price=price)#yield就是类似return,返回一个值——————获取一个book就将对象交给管道piplines——————再保存yield book# 第二页第三页的网址——一个网站数据结构应该是一样的# http://category.dangdang.com/pg2-cp01.28.01.12.00.00.html# http://category.dangdang.com/pg3-cp01.28.01.12.00.00.html#ctrl+z暂停下载#ctrl+alt+l,整理json数据格式#多页请求代码——多页请求代码——多页请求代码——多页请求代码#别忘记改变allowed_domains=属性的范围——一般只写域名if self.page<100:#第一页已经爬取完毕#所以直接加一self.page=self.page+1#将self.page强转为字符串url=self.base_url+str(self.page)+'-cp01.28.01.12.00.00.html'#去调用parse方法#scrapy.Request就是scrapy的get请求#callback属性就是要执行哪一个函数——注意不要加括号()yield scrapy.Request(url=url,callback=self.parse)
这篇关于【爬虫之scrapy框架——尚硅谷(学习笔记one)--基本步骤和原理+爬取当当网(基本步骤)】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







