本文主要是介绍深度学习技术之加宽前馈全连接神经网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
深度学习技术
- 加宽前馈全连接神经网络
- 1. Functional API 搭建神经网络模型
- 1.1 利用Functional API编写宽深神经网络模型进行手写数字识别
- 1.1.1 导入需要的库
- 1.1.2 加载虹膜(Iris)数据集
- 1.1.3 分割训练集和测试集
- 1.1.4 定义模型输入层
- 1.1.5 添加隐藏层
- 1.1.6 拼接输入层和第二个隐藏层
- 1.1.7 添加输出层
- 1.1.8 创建模型
- 1.1.9 打印模型的摘要
- 1.1.10 模型编译并训练
- 1.2 利用Functional API编写多输入神经网络模型进行手写数字识别
- 1.2.1 分割子集
- 1.2.2 定义输入层
- 1.2.3 定义全连接层
- 1.2.4 创建模型
- 1.2.5 编译与训练模型
- 1.2.6 训练历史数据的可视化
- 2. SubClassing API 搭建神经网络模型
- 2.1 前馈全连接神经网络手写数字识别
- 2.1.1 定义一个Keras模型类
- 2.1.2 定义方法
- 2.1.3 初始化模型
- 2.1.4 通过在初始化中传递参数改变模型元素默认值
- 2.1.5 编译与训练模型
- 2.1.6 打印模型摘要
加宽前馈全连接神经网络
1. Functional API 搭建神经网络模型
1.1 利用Functional API编写宽深神经网络模型进行手写数字识别
1.1.1 导入需要的库
利用Sequential API建立一个顺序传播的前馈全连接神经网络,导入numpy、pandas,tensorflow等库,以及导入matplotlib的pyplot模块。从sklearn库的datasets模块中导入load_iris函数,以及从sklearn库的model_selection模块中导入train_test_split函数。从TensorFlow库中导入Keras模块。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow import keras
1.1.2 加载虹膜(Iris)数据集
虹膜(Iris)数据集是scikit-learn库中内置的一个样本数据集,它包含了150个样本,分为三个类,每个类有50个样本。这三个类分别是山鸢尾(Iris Setosa)、杂色鸢尾(Iris Versicolour)和维吉尼亚鸢尾(Iris Virginica)。
iris = load_iris()
1.1.3 分割训练集和测试集
将虹膜(Iris)数据集分割为训练集和测试集,得到训练集x_train和y_train,再将分割得到的训练集x_train和y_train分割为新的训练集和验证集。
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target, test_size=0.2, random_state=23)
X_train, X_valid, y_train, y_valid=train_test_split(x_train, y_train,test_size=0.2, random_state=12)
1.1.4 定义模型输入层
使用X_train.shape[1:]作为输入层的形状,因为X_train.shape[0]是批量大小,通常在训练过程中改变,而X_train.shape[1:]包含了特征的数量,这些数量在训练过程中保持不变。
inputs = keras.layers.Input(shape=X_train.shape[1:])
1.1.5 添加隐藏层
隐藏层,包含神经元,并使用ReLU激活函数。
hidden1 = keras.layers.Dense(300, activation="relu")(inputs)
hidden2 = keras.layers.Dense(100, activation="relu")(hidden1)
1.1.6 拼接输入层和第二个隐藏层
将输入层和第二个隐藏层的输出进行拼接,得到一个融合了输入和中间层信息的特征向量。
concat = keras.layers.concatenate([inputs, hidden2])
1.1.7 添加输出层
添加了一个输出层,包含10个神经元,使用softmax激活函数,因为模型是用于多类分类任务。
output = keras.layers.Dense(10, activation="softmax")(concat)
1.1.8 创建模型
创建了一个完整的模型,将输入层和输出层连接起来,形成了一个有监督学习的模型结构。
这个模型结构结合了“宽”模型(wide model)和“深”模型(deep model)的特点,通过输入层和隐藏层的拼接来融合这两种模型。
model_fun_WideDeep = keras.models.Model(inputs=[inputs], outputs=[output])
运行结果:
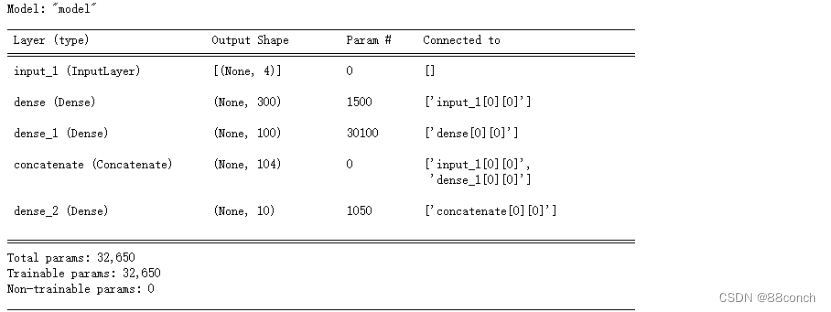
1.1.9 打印模型的摘要
model_fun_WideDeep.summary()
1.1.10 模型编译并训练
model_fun_WideDeep.fit()方法将开始模型的训练过程,并在每个轮次结束后使用验证数据评估模型的性能。训练过程中,模型将逐渐学习如何将输入特征映射到正确的输出类别。
model_fun_WideDeep.compile(loss="sparse_categorical_crossentropy",optimizer="sgd",metrics=["accuracy"])
h=model_fun_WideDeep.fit(X_train, y_train, batch_size=32, epochs=30, validation_data=(X_valid, y_valid))
运行结果:

1.2 利用Functional API编写多输入神经网络模型进行手写数字识别
1.2.1 分割子集
将训练集X_train和验证集X_valid分割为两个子集。
X_train_A, X_train_B = X_train[:, :200], X_train[:, 100:]
X_valid_A, X_valid_B = X_valid[:, :200], X_valid[:, 100:]
1.2.2 定义输入层
input_A = keras.layers.Input(shape=X_train_A.shape[1])
input_B = keras.layers.Input(shape=X_train_B.shape[1])
1.2.3 定义全连接层
hidden1 = keras.layers.Dense(300, activation="relu")(input_B)
hidden2 = keras.layers.Dense(100, activation="relu")(hiddenl)
1.2.4 创建模型
将输入层和输出层连接起来。
model_fun_MulIn = keras.models.Model(inputs=[input_A, input_B], outputs=[output])
1.2.5 编译与训练模型
在训练过程中,模型将使用指定的损失函数和优化器来更新权重,并使用准确率作为评估指标来监控性能。
model_fun_MulIn.compile(loss="sparse_categorical_crossentropy",optimizer="sgd",metrics=["accuracy"])
运行结果:

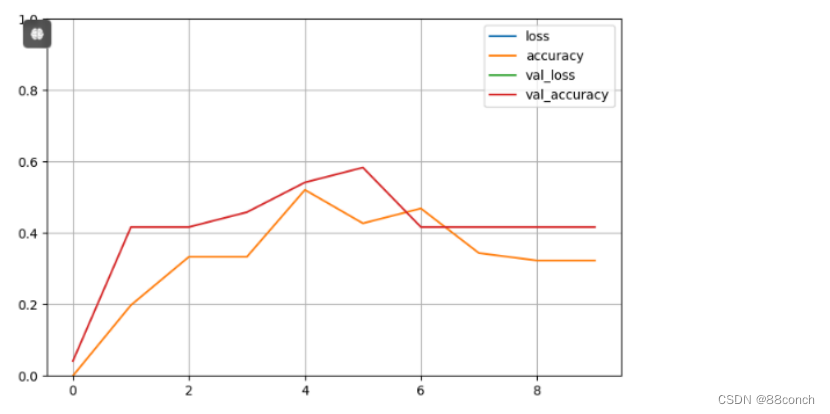
1.2.6 训练历史数据的可视化
图中显示了训练和验证集上的损失和准确率随轮次的变化情况。
pd.DataFrame(h.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show()
运行结果:
2. SubClassing API 搭建神经网络模型
2.1 前馈全连接神经网络手写数字识别
2.1.1 定义一个Keras模型类
定义一个自定义的Keras模型类Model_sub_fnn,继承自keras.models.Model。这个类定义了一个简单的全连接神经网络,它有两个隐藏层和一个输出层。
class Model_sub_fnn(keras.models.Model):def __init__(self, units_1=300, units_2=100, units_out=10, activation='relu'):super().__init__()self.hidden1 = keras.layers.Dense(units_1, activation=activation)self.hidden2 = keras.layers.Dense(units_2, activation=activation)self.main_output = keras.layers.Dense(units_out, activation='softmax')
2.1.2 定义方法
给Model_sub_fnn类定义一个call方法。这个方法是Keras模型中的一个特殊方法,它定义了模型的前向传播过程,它将输入数据通过模型的所有层,并返回最终的输出。
def call(self, data):hidden1 = self.hidden1(data)hidden2 = self.hidden2(hidden1)main_output = self.main_output(hidden2)return main_output
2.1.3 初始化模型
model_sub_fnn = Model_sub_fnn()
2.1.4 通过在初始化中传递参数改变模型元素默认值
model_sub_fnn2 = Model_sub_fnn(300, 100, 10, activation='relu')
2.1.5 编译与训练模型
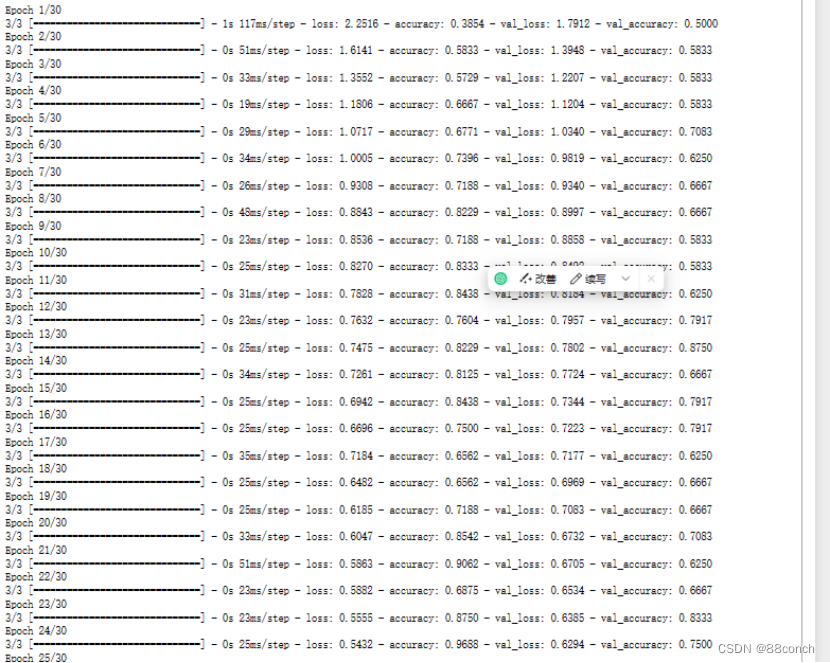
编译模型,使用训练数据和验证数据进行训练。在训练过程中,模型将使用指定的损失函数和优化器来更新权重,并使用准确率作为评估指标来监控性能。训练完成后,将得到模型的摘要,其中包含了模型的详细信息。
model_sub_fnn.compile(loss='sparse_categorical_crossentropy',optimizer='sgd',metrics=["accuracy")
h= model_sub_fnn.fit(X_train,y_train,batch_size=32,epochs=30,validation_data = (X_valid,y_valid))
运行结果:
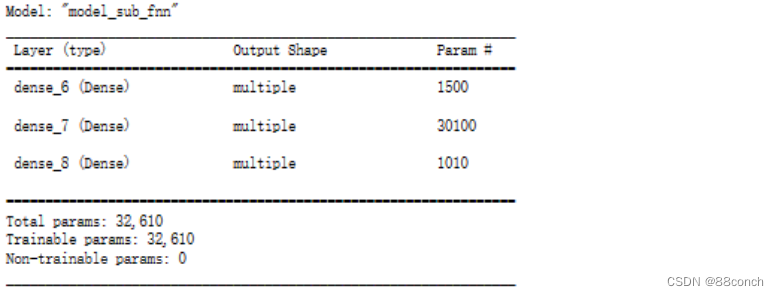
2.1.6 打印模型摘要
打印出模型的摘要,其中包括模型的层结构、每个层的输出形状、层的参数数量以及整个模型的总参数数量。
model_sub_fnn.summary()
运行结果:
这篇关于深度学习技术之加宽前馈全连接神经网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





