本文主要是介绍LeetCode题练习与总结:二叉树的中序遍历--94,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、题目描述
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:
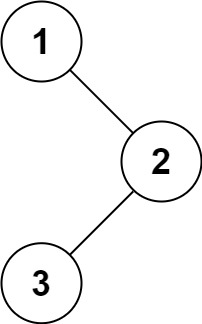
输入:root = [1,null,2,3] 输出:[1,3,2]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
二、递归方法
(一)解题思路
- 如果当前节点为空,返回。
- 递归遍历左子树。
- 访问当前节点,将节点的值添加到结果列表中。
- 递归遍历右子树。
(二)具体代码
class Solution {public List<Integer> inorderTraversal(TreeNode root) {List<Integer> result = new ArrayList<>();inorder(root, result);return result;}private void inorder(TreeNode node, List<Integer> result) {if (node == null) {return;}inorder(node.left, result);result.add(node.val);inorder(node.right, result);}
}
(三)时间复杂度和空间复杂度
1. 时间复杂度
- 递归方法会访问树中的每个节点恰好一次,因此时间复杂度与树中节点的数量成正比。
- 在这个算法中,每个节点都会被访问一次,所以时间复杂度是 O(n),其中 n 是二叉树中的节点数。
2. 空间复杂度
- 递归方法的空间复杂度主要取决于递归栈的深度,这通常与树的高度成正比。
- 在最坏的情况下,树完全不平衡,每个节点都只有左子节点或者只有右子节点,递归栈的深度会达到节点数 n,因此空间复杂度为 O(n)。
- 在最好的情况下,树是完全平衡的,递归栈的深度是 log(n),因此空间复杂度为 O(log(n))。
- 综合考虑,空间复杂度在最坏情况下是 O(n),在最好情况下是 O(log(n)),平均情况下则介于两者之间。
综上所述,递归方法的中序遍历代码的时间复杂度是 O(n),空间复杂度在最坏情况下是 O(n),在最好情况下是 O(log(n))。
(四)总结知识点
1. 递归(Recursion):
- 代码中使用了递归函数
inorder来遍历二叉树的左子树、根节点和右子树。 - 递归是一种常用的算法设计技巧,它通过函数自身调用自己来进行循环。
2. 二叉树(Binary Tree):
- 代码操作的数据结构是二叉树,每个节点包含一个值和指向左右子节点的引用。
- 二叉树是一种基础的数据结构,常用于各种算法问题。
3. 二叉树的中序遍历(Inorder Traversal of a Binary Tree):
- 中序遍历是一种遍历二叉树的方法,按照“左-根-右”的顺序访问每个节点。
- 这是二叉树遍历的三种基本方法之一(其他两种是前序遍历和后序遍历)。
4. Java 集合框架(Java Collections Framework):
- 代码使用了
ArrayList来存储遍历的结果,这是 Java 集合框架中的一个类。 ArrayList是一个可调整大小的数组实现,提供了对元素的快速随机访问。
5. 函数定义和调用(Function Definition and Invocation):
- 代码定义了两个函数:
inorderTraversal和inorder。 inorderTraversal是公共方法,供外部调用;inorder是私有辅助方法,用于递归遍历。
6. 基本语法(Basic Syntax):
- 代码使用了基本的 Java 语法,如类定义、方法定义、条件语句(if)、返回语句(return)等。
7. 递归栈(Recursive Stack):
- 虽然代码中没有显式使用栈数据结构,但递归函数在调用时会使用调用栈来存储每一层递归的状态。
三、迭代方法
(一)解题思路
- 初始化一个空栈和一个空列表。
- 将根节点及其所有左子节点入栈。
- 弹出栈顶元素,将其值添加到结果列表中。
- 将弹出节点的右子节点及其所有左子节点入栈。
- 重复步骤3和4,直到栈为空。
(二)具体代码
import java.util.Stack;class Solution {public List<Integer> inorderTraversal(TreeNode root) {List<Integer> result = new ArrayList<>();Stack<TreeNode> stack = new Stack<>();TreeNode current = root;while (current != null || !stack.isEmpty()) {while (current != null) {stack.push(current);current = current.left;}current = stack.pop();result.add(current.val);current = current.right;}return result;}
}
(三)时间复杂度和空间复杂度
1. 时间复杂度
- 中序遍历需要访问二叉树中的每个节点一次,因此时间复杂度与二叉树中节点的数量成正比。
- 在这个算法中,每个节点都会被访问一次,所以时间复杂度是 O(n),其中 n 是二叉树中的节点数。
2. 空间复杂度
- 空间复杂度主要取决于迭代过程中使用的栈的大小。
- 在最坏的情况下,树完全不平衡,每个节点都只有左子节点或者只有右子节点,栈的大小会达到节点数 n,因此空间复杂度为 O(n)。
- 在最好的情况下,树是完全平衡的,栈的大小是 log(n),因此空间复杂度为 O(log(n))。
- 综合考虑,空间复杂度在最坏情况下是 O(n),在最好情况下是 O(log(n)),平均情况下则介于两者之间。
综上所述,这段代码的时间复杂度是 O(n),空间复杂度在最坏情况下是 O(n),在最好情况下是 O(log(n))。
(四)总结知识点
1. 迭代(Iteration):
- 代码使用了一个循环结构来迭代地遍历二叉树的节点,而不是使用递归。
2. 栈(Stack)数据结构:
- 代码使用了一个
Stack来存储访问过的节点,以便后续能够按照正确的顺序访问它们的右子节点。 - 栈是一种后进先出(LIFO)的数据结构,非常适合用于这种需要回溯的场景。
3. 二叉树(Binary Tree):
- 代码操作的数据结构是二叉树,每个节点包含一个值和指向左右子节点的引用。
- 二叉树是一种基础的数据结构,常用于各种算法问题。
4. 二叉树的中序遍历(Inorder Traversal of a Binary Tree):
- 中序遍历是一种遍历二叉树的方法,按照“左-根-右”的顺序访问每个节点。
- 这是二叉树遍历的三种基本方法之一(其他两种是前序遍历和后序遍历)。
5. Java 集合框架(Java Collections Framework):
- 代码使用了
ArrayList来存储遍历的结果,这是 Java 集合框架中的一个类。 ArrayList是一个可调整大小的数组实现,提供了对元素的快速随机访问。- 同时,代码使用了
Stack类来实现栈数据结构。
6. 循环和条件语句(Loop and Conditional Statements):
- 代码使用了
while循环来迭代遍历树节点,并使用了if语句来检查当前节点是否为空。
7. 函数定义和调用(Function Definition and Invocation):
- 代码定义了一个公共方法
inorderTraversal,供外部调用。
8. 基本语法(Basic Syntax):
- 代码使用了基本的 Java 语法,如类定义、方法定义、循环结构、条件语句等。
以上就是解决这个问题的详细步骤,希望能够为各位提供启发和帮助。
这篇关于LeetCode题练习与总结:二叉树的中序遍历--94的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








