本文主要是介绍【python】python水浒传小说文本分析词云可视化(源码+文本+报告)【独一无二】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

系列文章目录
目录
- 系列文章目录
- 一、设计目的
- 二、详细设计
一、设计目的
- 设计要求
1.完成《水浒传》人物姓名词云,
2.生成形状词云主要内容(提纲式的内容要求)
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “水浒” 获取。👈👈👈
-
总体方案设计
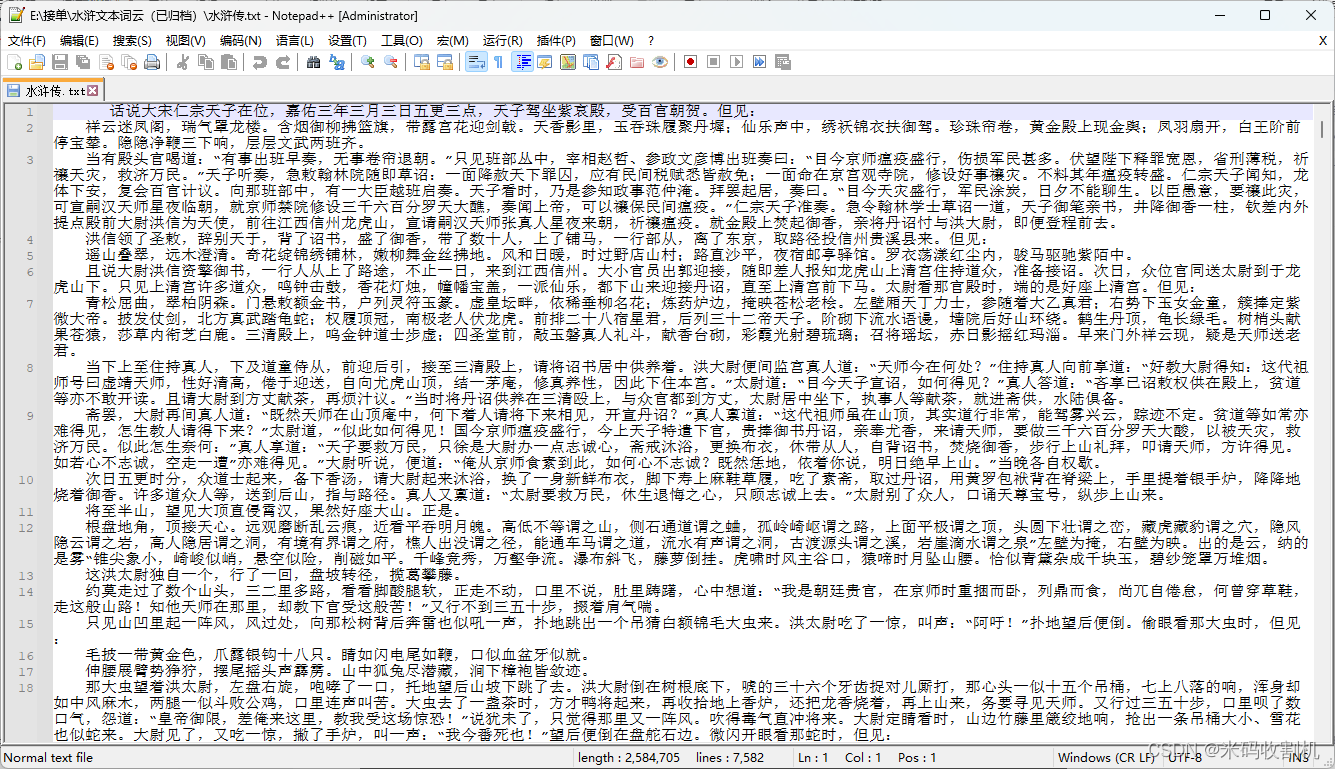
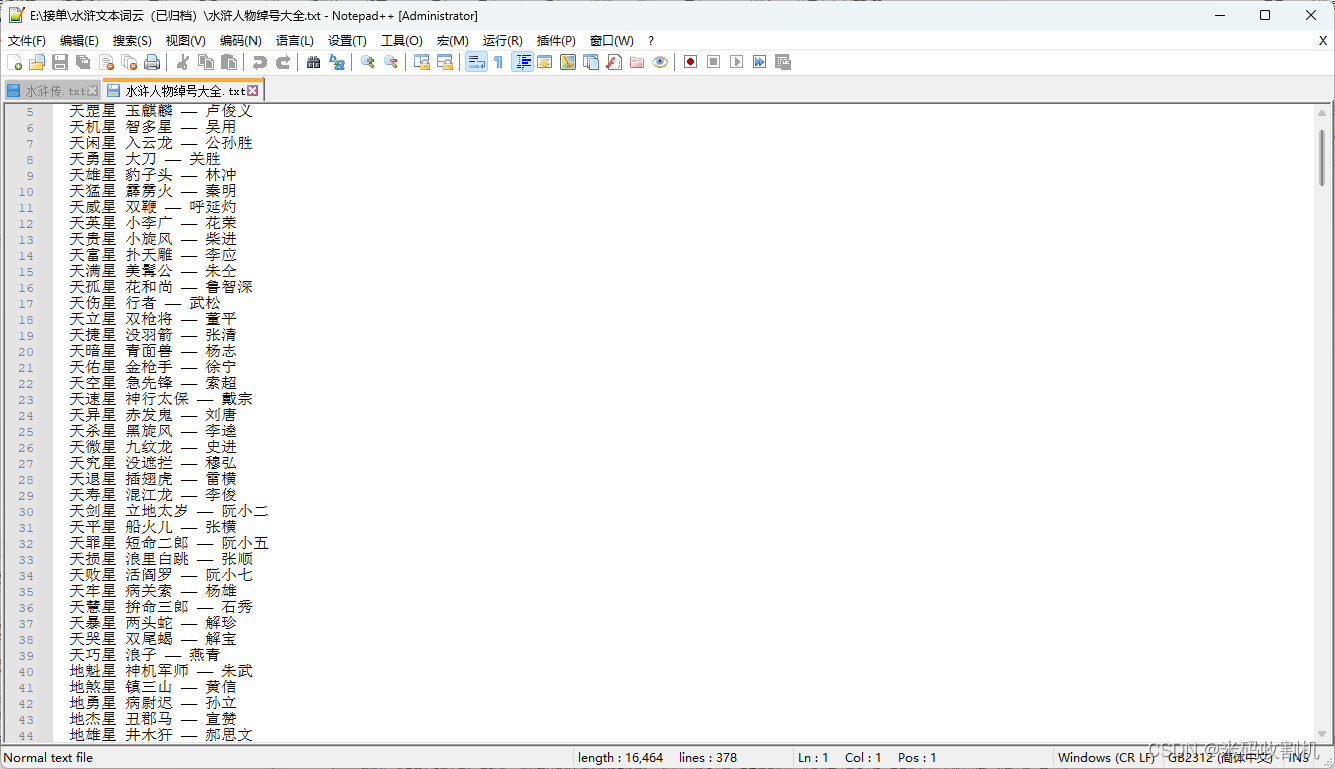
(1)《水浒传》人物姓名词云
(2)完成《水浒传》词频统计及图表
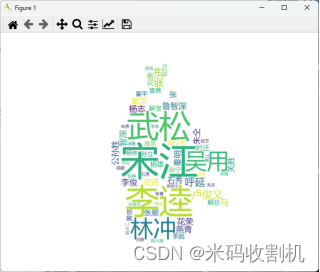
(3)以文中最高频人物图片为形状的词云 -
详细设计
(1)获取数据源
(2)iieba库将句子解析成词
(3)Wordcloud库将词转化为词云可视化输出
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “水浒” 获取。👈👈👈
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “水浒” 获取。👈👈👈
二、详细设计
本代码旨在利用Python编程语言,结合第三方库(如jieba、wordcloud等)对《水浒传》文本进行分词、词频统计和词云生成,以便深入分析该文学作品中的人物角色及其关系。以下是代码的设计思路及实现步骤:
-
导入所需库和模块
首先,我们导入需要使用的Python库和模块,包括jieba用于中文分词、Counter用于词频统计、WordCloud用于生成词云图、matplotlib.pyplot用于图形展示,以及PIL和numpy用于图像处理和数据处理。import jieba from collections import Counter from wordcloud import WordCloud import matplotlib.pyplot as plt from PIL import Image import numpy as np -
读取文本文件
通过Python的文件操作,我们读取《水浒传》的文本文件,并将其内容存储在一个字符串变量中,以便后续的分词和文本处理操作。with open('水浒传.txt', 'r', encoding='utf-8') as file:text = file.read()
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “水浒” 获取。👈👈👈
-
使用jieba进行分词
利用jieba库对文本进行中文分词处理,将文本分割成一个个词语,形成一个词语列表,以便后续的词频统计和词云生成。 -
统计词频
利用Python的Counter模块,对分词后的词语列表进行词频统计,得到每个词语出现的次数,从而了解《水浒传》中各个词语的重要程度。word_counts = Counter(seg_list) -
生成词云
利用WordCloud库生成词云图,根据词频统计结果,将词语以不同大小、颜色等形式展现在词云图中,直观地展示出《水浒传》中人物形象的特点和故事主题。wordcloud = WordCloud().generate_from_frequencies(word_counts) -
图片处理
如果需要将词云图生成特定形状的词云,我们还可以利用PIL库读取图片文件,并转换为Numpy数组,以便在词云生成时指定形状。img = Image.open("xxx.png") img_array = np.array(img)
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “水浒” 获取。👈👈👈
- 展示词云图
最后,利用matplotlib.pyplot库展示生成的词云图,通过图形化的方式呈现出《水浒传》中人物形象的特点和故事主题,为读者提供更直观、生动的阅读体验。
宋江词云如下:

👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “水浒” 获取。👈👈👈
这篇关于【python】python水浒传小说文本分析词云可视化(源码+文本+报告)【独一无二】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







