本文主要是介绍【强化学习-Mode-Free DRL】深度强化学习如何选择合适的算法?DQN、DDPG、A3C等经典算法Mode-Free DRL算法的四个核心改进方向,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【强化学习-DRL】深度强化学习如何选择合适的算法?
- 引言:本文第一节先对DRL的脉络进行简要介绍,引出Mode-Free DRL。
- 第二节对Mode-Free DRL的两种分类进行简要介绍,并对三种经典的DQL算法给出其交叉分类情况;
- 第三节对Mode-Free DRL的四个核心(改进方向)进行说明。
- 第四节对DQN的四个核心进行介绍。
DRL的发展脉络
- DRL沿着Mode-Based和Mode-Free两个脉络发展。
- Mode-Based:利用已知环境模型或未知环境模型进行显式建,并与前向搜索(Look Ahead Search)和轨迹优化(Trajectory Optimization)等规划算法结合达到提升数据效率的目的。相比而言,Mode-Based更加复杂,在实践中应用较少,在学术研究中使用较多。
- 本文对Mode-Free系列的方法进行介绍。
Mode-Free DRL算法的分类
- 按照不同的分类可以分为:Value-Based方法、Policy-Based方法。以及Off-Policy、On-Policy。
- DQN、DDPG、A3C是三种非常非常经典的方法,也是DRL的研究重点,后续提出的新算法基本都立足于这三种框架。DQN、DDPG、A3C在上述两种分类方式下交叉分类情况如下图。
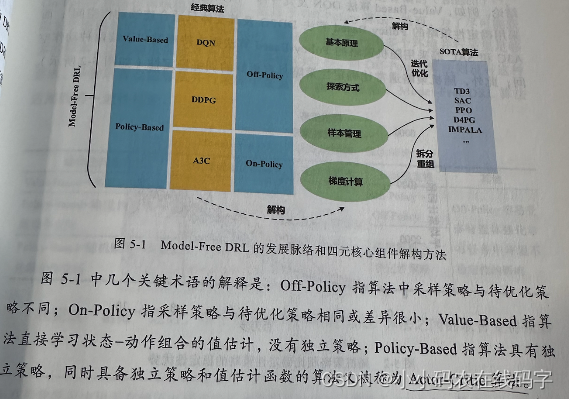
Mode-Free DRL算法的四个核心(改进方向)
- Mode-Free DRL算法的核心为:基本原理、探索方式、样本管理、梯度计算。
- 基本原理:基本原理层面进展缓慢,但是DRL未来大规模应用的关键所在。
- 探索方式: 探索方式的改进使得DRL算法更加充分地探索环境,以更好地平衡探索和利用,从而有机会学习到更好的策略。
- 如为了改善DQN的探索,使用噪声网络(Noisy Net)代替默认的 ϵ − G r e e d y \epsilon-Greedy ϵ−Greedy 。
- 样本管理:样本管理的改进,有助于提升DRL算法的样本效率,从而加快收敛速度,提高算法实用性。
- 如为了提升样本效率,可以将常规经验回放改为优先经验回放(Prioritized Experience Replay,PER)。
- 梯度计算:梯度计算的改进致力于使每一次梯度更新都稳定、无偏和高效。
- 如为了提高训练稳定性,在计算目标值时由单步Bootstrap改为多步Bootstrap。
DQN
- 我们以DQN为例子对Mode-Free DRL算法的四个核心进行说明。
基本原理
- DQN(Deep Q-Networks)继承了Q-Learning的思想,利用贝尔曼公式的Bootstrap特性,根据式子1计算目标值并不断迭代一个状态动作估值函数 Q θ ( s , a ) Q_\theta(s,a) Qθ(s,a),直到收敛。
J Q ( θ ) = E s , a ∼ D [ 1 2 r ( s , a ) + γ m a x a ′ ∈ A Q θ − ( s ′ , a ′ ) − Q θ ( s , a ) 2 ] J_{Q}(\theta) = E_{s,a \sim D}[\frac{1}{2} r(s,a) + \gamma max_{a' \in A } Q_{\theta ^- } (s',a') - Q_{\theta}(s,a)^2] JQ(θ)=Es,a∼D[21r(s,a)+γmaxa′∈AQθ−(s′,a′)−Qθ(s,a)2]
探索方式
- DQN使用 ϵ − G r e e d y \epsilon-Greedy ϵ−Greedy 的探索策略。 ϵ \epsilon ϵ在 ( 0 , 1 ] (0,1] (0,1]由大到小现行变化,DQN相应地实现从“强探索利用”逐渐过渡到“弱探索利用”。
样本管理
- DQN使用Off-Policy,即采集样本策略与当前待优化策略不一致的方法。
- DQN使用Replay Buffer的先入先出堆栈结构存储训练过程中采集的单步转移样本 ( s , a , s ′ , r ′ ) (s,a,s',r') (s,a,s′,r′) ,并每次从中选择一个Batch进行梯度计算和参数更新。
- Replay Buffer允许重复利用隶属数据,以Batch为单位进行训练覆盖了更大的状态空间,中和了单个样本计算梯度时的Variance(方差),时DQN训练和提高样本效率的重要措施。
梯度计算
- 为克服Bootstrap带来的训练不稳定。DQN设置了一个与Q网络完全相同的目标Q网络。目标Q网络专门用于计算下一步的Q值,参数用 θ − \theta^- θ−表示。目标网络的参数并不每次都迭代更新,而是每N次迭代后从主Q网络中将参数拷贝过来,这样做可以有效提升DQN的训练稳定性。
A3C
- DQN和DDPG都属于Off-Policy算法,都利用了贝尔曼公式的Bootstrap特性来更新Q网络。该方法具有运行利用历史数据,带来样本效率提升的同时,导致训练稳定性较差,并且目标值的计算不是无偏的,普遍存在overstimation问题,不利于累积回报的梯度回传。
- 与Off-Policy算法基于单步转移样本 ( s , a , s ′ , r ) (s,a,s',r) (s,a,s′,r)不同,On-Policy算法利用蒙特卡洛方法通过最新策略随机采集多个完整Episode获得当前值函数 V ( s ) V(s) V(s) 的无偏估计,从而提高了训练性能。
- A3C(Asynchronous Advantage Actor-Critic)是 On-Policy DRL的经典代表。
- A3C的具体四个核心我们之后文章中会进行分析,敬请关注收藏。
参考文献
- 深度强化学习落地指南
这篇关于【强化学习-Mode-Free DRL】深度强化学习如何选择合适的算法?DQN、DDPG、A3C等经典算法Mode-Free DRL算法的四个核心改进方向的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




