本文主要是介绍python爬虫入门(所有演示代码,均有逐行分析!),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬虫的初学者们,只看这一篇就够了,看到就是赚到!
目录
1.爬虫简介
2.版本及库的要求
3.爬虫的框架
4.HTML简介
5.爬虫库及演示
(1)requests库(网页下载器)
(2)BeautifulSoup库(网页解析器)
6.爬虫框架补充
(1)URL管理模块
7.对目标网站进行解析
8.举个栗子
(1)所需库
(2)爬取目标
(3)网页分析
(4)编写爬虫前的准备
(5)编写代码
9.参考资料
1.爬虫简介
网络爬虫,也称为网页蜘蛛或网络机器人,是一种自动抓取万维网信息的程序或脚本。
爬虫的基本原理是通过模拟人的网络行为,如点击按钮、查看数据等,来获取服务器上的数据。这些数据可以是文本、图片、视频等多种格式。爬虫分为通用爬虫和聚焦爬虫两大类,其中通用爬虫的目标是在保持一定内容质量的情况下爬取尽可能多的站点,如搜索引擎;而聚焦爬虫则主要针对特定对象或网站,有一台指定的爬取路径、数据抽取规则。
此外,爬虫还被广泛应用于多个领域,如数据聚合、舆情分析、网络安全、税务稽查等。
2.版本及库的要求
2.1python使用版本:3.7.9
2.2爬虫所需库
[1]resquests
[2]Beautifulsoup4
[3]selenium
ps:上述库可通过
pip install requests
直接安装,安装完在pycharm新建test.py文件,输入一下代码进行验证,查看库是否安装成功
import requests
from bs4 import BeautifulSoup
import seleniumprint("ok")若安装成功则输出如下图所示:

3.爬虫的框架
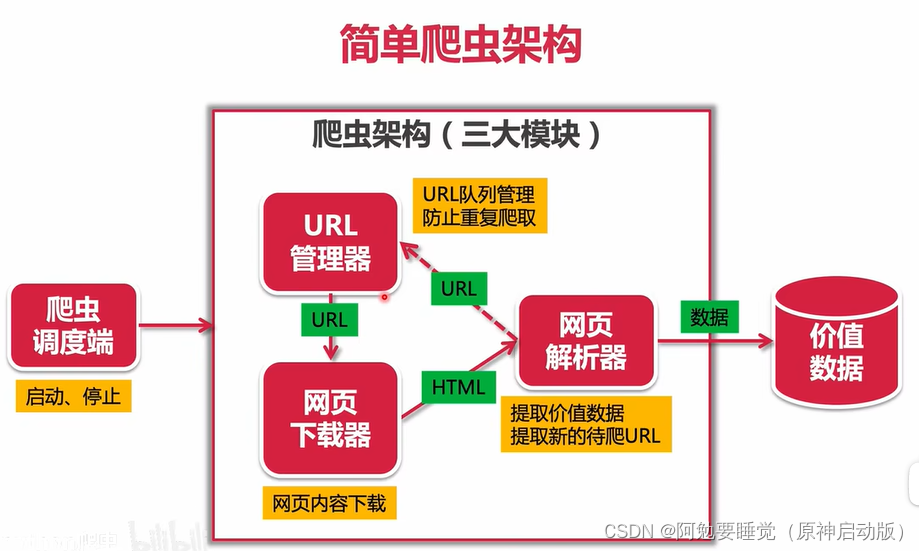
(1) URL管理器:相当于一个数据容器,其中包含待爬取及爬取过的url。
模块作用:防止爬虫重复爬取页面,或循环爬取陷入死循环中。
(2)网页下载器:用python获取网页的信息。
模块作用:爬取页面信息。复杂页面的爬取,动态页面,需要登录验证码的页面,或者有一些防御手段禁止爬取的页面,都需要在此模块中解决。(一般网页使用动态加载数据,需要使用到selenium框架解决。)
(3)网页解析器:获取网页下载器下载下来的HTML,提取其中有价值的信息和待爬取的新URL,传输给URL管理器,循环爬取数据。
(4)并发爬取,在爬虫调度端实现。
(5)数据存储,像将数据保存在数据库中,统一在价值数据模块中实现。
4.HTML简介
这部分内容简单看一下
想深入了解看可以看看HTML 教程

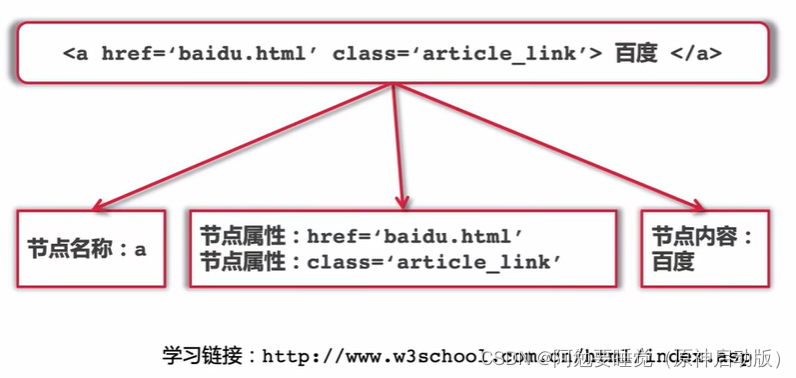
5.爬虫库及演示
(1)requests库(网页下载器)
一个优雅的、简单的Python、HTTP库,常常用于爬虫对网页内容的下载。
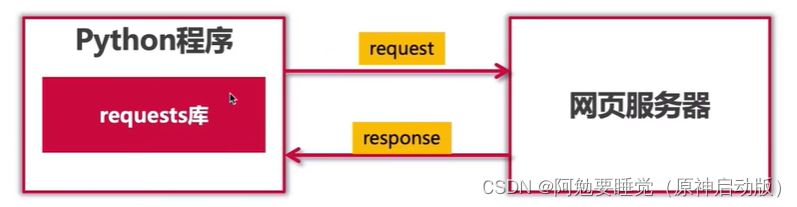
requests库用法:


以下代码可以直接在pycharm中运行,看看返回结果
代码段1:
import requestsurl = "http://www.crazyant.net"r = requests.get(url)print(r.status_code)
print(r.headers)
print(r.encoding)
print(r.text)
print(r.cookies)代码段2:
import requests#url = “http://www.crazyant.net”
#url = "http://www.baidu.com"
url = "http://www.httpcn.com"r = requests.get(url)
#r.encoding = "UTF-8"print(r.status_code)
print(r.headers)
print(r.encoding)
print(r.text)
print(r.cookies)
当编码不规范时,爬取的中文信息中可能会出现乱码,此时需要我们手动更改编码信息
import requests#url = “http://www.crazyant.net”
#url = "http://www.baidu.com"
url = "http://www.httpcn.com"r = requests.get(url)
r.encoding = "UTF-8"print(r.status_code)
print(r.headers)
print(r.encoding)
print(r.text)
print(r.cookies)
更改前: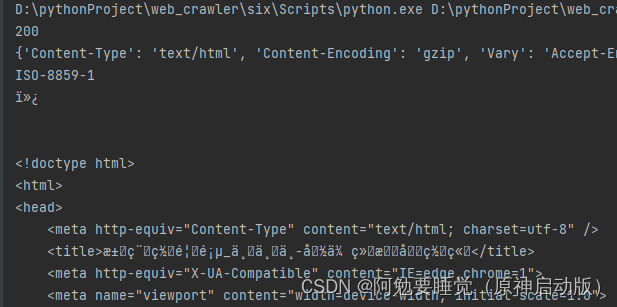
更改后: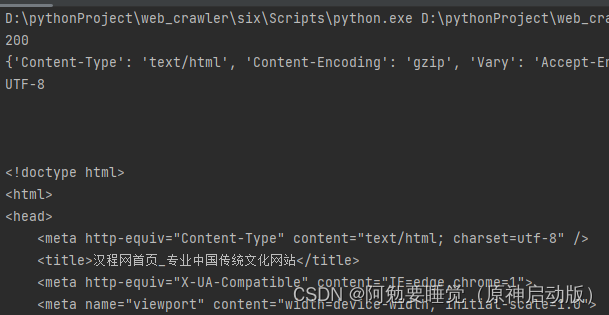
(2)BeautifulSoup库(网页解析器)
BeautifulSoup库官网:Beautiful Soup: We called him Tortoise because he taught us.
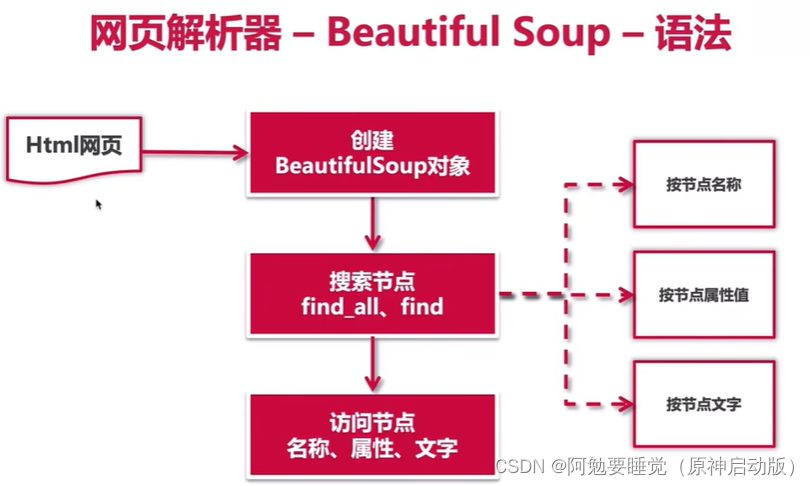



方便练习,我们先自己写一个简单的网页
<html>
<head><meta http-equiv=Content-Type content="text/html;charset=utf-8"><title>网页标题</title>
</head>
<body><h1>标题1</h1><h2>标题2</h2><h3>标题3</h3><h4>标题4</h4><div id="content" class="default"><p>段落</p><a href="http://www.baidu.com">百度</a> </br><a href="http://www.crazyyant.net">疯狂的蚂蚁</a> </br><a href="http://www.iqiyi.com">爱奇艺</a> </br><img src="http://www.python.org/static/img/python-logo.png"/></div>
</body>
</html>运行之后长这样:

爬取上述简单网页:
创建一个Python Package,命名为bs4_test
把上述网页放在Package下,命名为test.html
再在Package中创建一个test.py文件
结构如下图:

test.py文件中的代码:
from bs4 import BeautifulSoupwith open("./test.html", encoding="utf-8") as fin:
#打开当前目录下的HTMLhtml_doc = fin.read()#读取HTML中的内容作为一个字符串soup = BeautifulSoup(html_doc, "html.parser")
#创建一个BeautifulSoup对象div_node = soup.find("div", id="content")
#指定查找模块的id为content
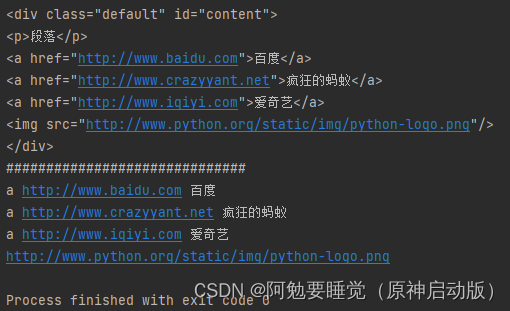
print(div_node)
print("#" * 30)links = soup.find_all("a")
#查找所有用的a节点
for link in links:print(link.name, link["href"], link.get_text())
#循环遍历a节点,并将遍历的a节点名称、href属性、文字内容打印出来img = soup.find("img")
print(img["src"])
#打印图片地址运行结果:
6.爬虫框架补充
(1)URL管理模块
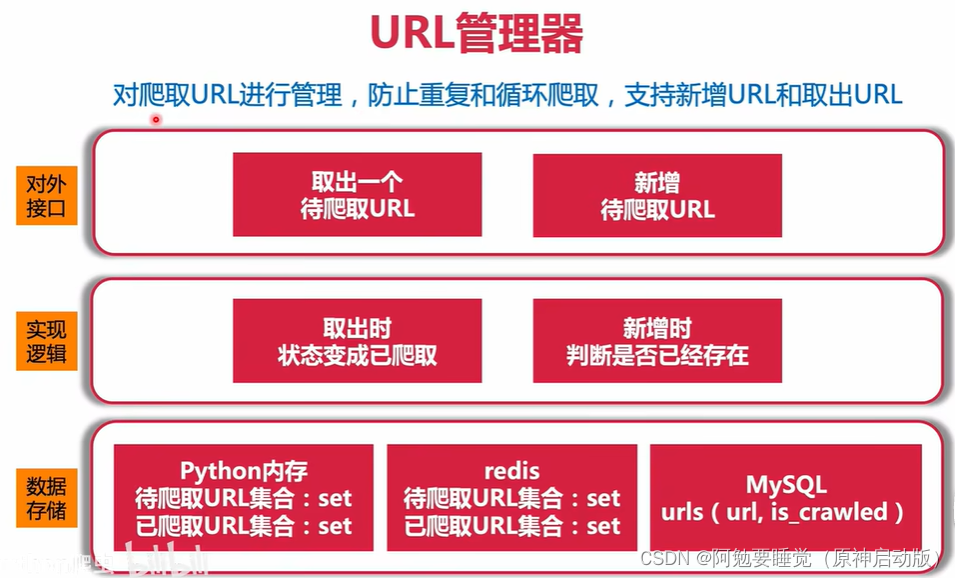
url管理器的实现代码:
class UrlManager():'''url管理器'''def __init__(self):#定义一个初始化函数self.new_urls = set()#新的待爬取url的集合self.old_urls = set()#已爬取url的集合def add_new_url(self, url):#定义新增单个url的方法一,传一个参数urlif url is None or len(url) == 0:#判断url是否为空或长度为0return#符合上述条件就停止增加if url in self.new_urls or url in self.old_urls:#判断url是否已经被记录在集合里return#已经载集合里的url不新增self.new_urls.add(url)#上述干扰条件排除后,url就可以加入待爬取的集合中def add_new_urls(self,urls):#定义新增url的方法二,传一个参数urlsif urls is None or len(urls) == 0:#判断参数urls是否为空returnfor url in urls:#不为空就将单个url循环传入单个判断url方法中经行判断存储self.add_new_url(url)def get_url(self):#定义获取新url的函数if self.has_new_url():#如果存在待爬取的urlurl = self.new_urls.pop()#就将待爬取的url从集合中移除并返回self.old_urls.add(url)#将移除的url加入已爬取的集合中return url#并将其返回else:return Nonedef has_new_url(self):#定义一个判断url是否存在等待爬取的urlreturn len(self.new_urls) > 0#如果待爬取集合中有元素就分返回这个集合'''测试代码'''
if __name__ == "__main__":
#文件内置变量,仅在执行当前文件时可用。当此文件被调用时,此出变量不会被执行。因此测试代码时一般加上这句话url_manger = UrlManager()#调用整个类url_manger.add_new_url("url1")url_manger.add_new_urls(["url1", "url2"])#故意增加一个重复的urlprint(url_manger.new_urls, url_manger.old_urls)print("#" * 30)new_url = url_manger.get_url()print(url_manger.new_urls, url_manger.old_urls)print("#" * 30)new_url = url_manger.get_url()print(url_manger.new_urls, url_manger.old_urls)print("#" * 30)print(url_manger.has_new_url())7.对目标网站进行解析
这点需要听课,来来来都给我听!(作者用的不是Windows系统,有点不一样,不影响,稳!)
[2.8]--爬虫前提之对目标网站进行分析_哔哩哔哩_bilibili
听不懂没关系,有个印象就行
8.举个栗子
(1)所需库
[1]requests
[2]BeautifulSoup
(2)爬取目标
网页的所有标题的文本和链接
(3)网页分析
打开检查,鼠标点击到标题,定位到它的源码

可以看到标提包裹在h2标签中,class="entry-title"
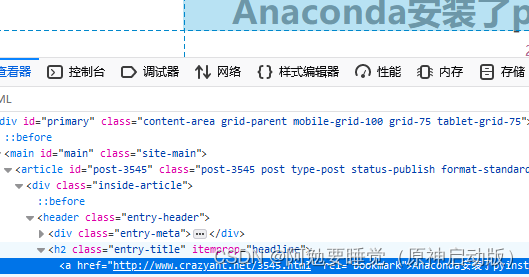
往下多看几个,发现都是这样的
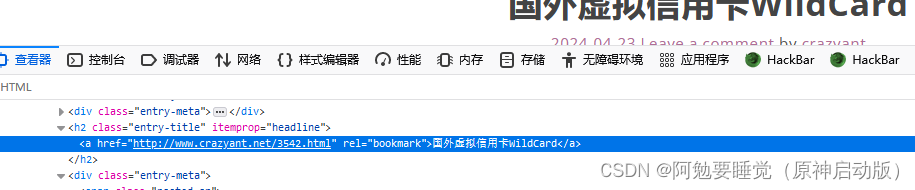
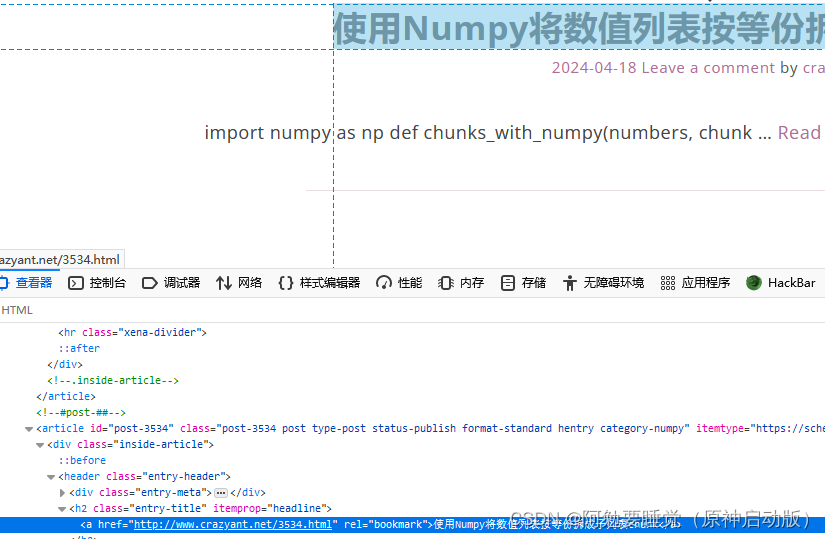
我们就可以指定查找模块h2,class为class="entry-title"
(4)编写爬虫前的准备
[1]新建一个python package,命名为blog_test
[2]新建一个main.py文件
(5)编写代码
import requests
from bs4 import BeautifulSoupurl = "http://www.crazyant.net/"r = requests.get(url)
if r.status_code != 200:raise Exception()#程序出现问题,退出程序html_doc = r.text
#获取文本
soup = BeautifulSoup(html_doc, "html.parser")
#定义变量h2_nodes = soup.find_all("h2", class_="entry-title")
#找到h2,class_="enter-title"for h2_node in h2_nodes:#h2_node是h2_nodes中的一条信息link = h2_node.find("a")#在查找的信息内,找到a标签的内容,传递给参数linkprint(link["href"], link.get_text())#输出a标签中herf属性,和文本内容9.参考资料
B站视频:
python爬虫入门实战案例教程-入门到精通(收藏版)_哔哩哔哩_bilibili
爬虫简介参考:
搜索智能精选
Python部分语法:
Python 中的 if __name=='__main__'作用浅析 - 简书
这篇关于python爬虫入门(所有演示代码,均有逐行分析!)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







