本文主要是介绍数据可视化训练第二天(对比Python与numpy中的ndarray的效率并且可视化表示),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
绪论
千里之行始于足下;继续坚持
1.对比Python和numpy的性能
使用魔法指令%timeit进行对比
需求:
- 实现两个数组的加法
- 数组 A 是 0 到 N-1 数字的平方
- 数组 B 是 0 到 N-1 数字的立方
import numpy as np
def numpy_sum(text_num):"""numpy的测试函数"""arra=np.arange(text_num) ** 2arrb=np.arange(text_num) ** 3return arra+arrbdef python_sum(text_num):"""原生Python的测试函数"""ab_sum=[]a=[value**2 for value in range(0,text_num)]b=[value**3 for value in range(0,text_num)]for i in range(0,text_num):ab_sum.append(a[i]+b[i])return ab_sumtext_num=100#保存Python的测试时间
#100,1000的数组长度测试起来时间可能比较小;可视化不太方便
python_times=[]
#进行到1000000次的时间测试
while text_num <= 1000000:result= %timeit -o python_sum(text_num)text_num=text_num*10python_times.append(result.average)#保存numpy的测试时间
numpy_times=[]
text_num=100
while text_num <= 1000000:result= %timeit -o numpy_sum(text_num)numpy_times.append(result.average)text_num=text_num*10下面通过折线图进行对比
#数据可视化对比
import matplotlib.pyplot as plt
from matplotlib.ticker import ScalarFormatterx_values=[100,1000,10000,100000,1000000]
python_y_values=np.array(python_times)*1000000
numpy_y_values=np.array(numpy_times)*1000000
fig,ax=plt.subplots()
ax.plot(x_values,python_y_values,linewidth=3,label='python')
ax.plot(x_values,numpy_y_values,linewidth=3,label='numpy')
ax.set_title("Comparing Numpy's Time with Python",fontsize=14)
ax.set_xlabel('text sum',fontsize=14)
ax.set_ylabel('time/us',fontsize=14)
#设置显示所有刻度
#ax.set_xticks(x_values,minor=True)
#使x轴完全表示,使用formatter自定义格式
formatter=ScalarFormatter(useMathText=True)#使用数学格式表示
formatter.set_powerlimits((0,7))
ax.xaxis.set_major_formatter(formatter)
ax.legend()#显示label标签
plt.show(
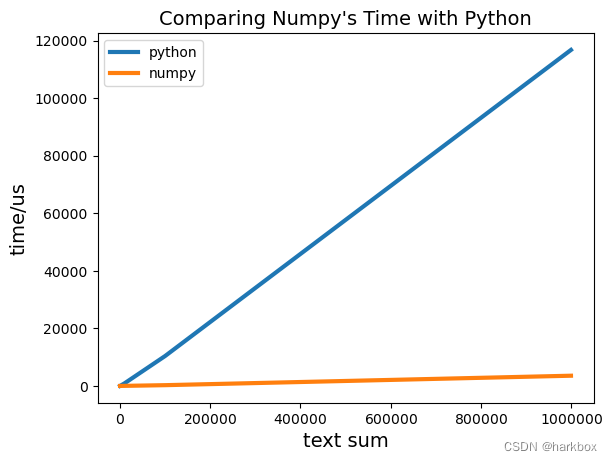
绘制柱状图
#绘制柱状图
fig,ax=plt.subplots()
bar_width=0.35
ax.bar(x_values,python_y_values,bar_width,label='Python')
ax.bar(x_values,numpy_y_values,bar_width,label='Numpy')ax.legend()#legend() 函数用于添加图例到图形上,就是右上角的图形
plt.tight_layout()
plt.show()
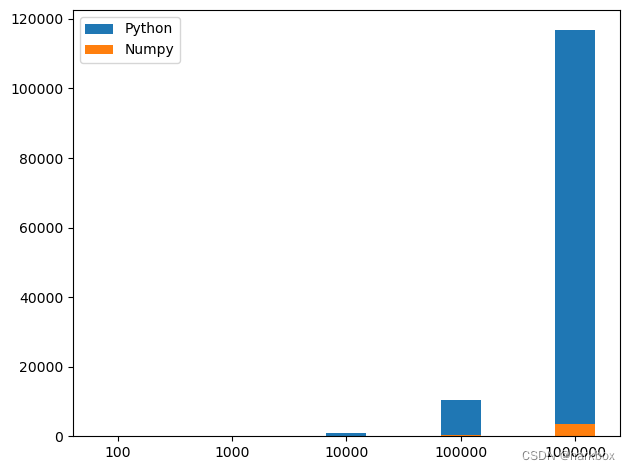
100和1000的时间太短了;可以从100000开始到100000000这样可视化会比较好看
这篇关于数据可视化训练第二天(对比Python与numpy中的ndarray的效率并且可视化表示)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





