本文主要是介绍英特尔StoryTTS:新数据集让文本到语音(TTS)表达更具丰富性和灵感,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DeepVisionary 每日深度学习前沿科技推送&顶会论文分享,与你一起了解前沿深度学习信息!
英特尔StoryTTS:新数据集让文本到语音(TTS)表达更具丰富性和灵感
引言:探索文本表达性在语音合成中的重要性
在当今数字化时代,语音合成技术(Text-to-Speech, TTS)已成为人机交互中不可或缺的一部分。随着深度学习的发展,TTS技术已能够生成越来越接近真实人声的语音。然而,尽管现有的TTS模型在模拟基本情感特征方面取得了显著进展,它们在处理需要高度表达性的文本,如小说、诗歌和对话等内容时,仍然面临挑战。
1. 文本表达性的定义与重要性
文本表达性是指文本在书写时所蕴含的情感和语调变化,这些特性能够影响语音的韵律和节奏,从而传达更丰富的情感和意境。例如,在叙述一个激动人心的故事时,文本中的感叹句和修辞手法可以增强语音的感染力,使听众能够感受到文字背后的情感波动。
2. 文本表达性在艺术作品语音合成中的应用
艺术作品如小说和戏剧,常常包含丰富的情感和复杂的情节,这要求TTS系统不仅要准确发音,还要能够表达文本中的情感和风格。例如,一个悲伤的场景可能需要TTS系统降低语速和调整音调,以适应文本的情感色彩。
3. 文本表达性对TTS技术发展的推动作用
随着对文本表达性研究的深入,TTS技术在表达性方面有了显著的提升。研究人员通过分析文本的语义和句法信息,提取出有助于改善语音合成的表达性特征,如句式、修辞和情感色彩等。这些特征的整合,使得TTS系统能够更加自然地模拟人类的语音表达,特别是在处理复杂和多变的情感表达时。
综上所述,文本表达性在语音合成中的重要性不言而喻。通过深入探索和利用文本的表达性特征,可以极大地提升TTS系统的自然度和表达力,使其在多种应用场景下都能提供更加真实、动人的语音输出。未来的研究可以进一步探索如何有效地从复杂文本中提取和利用这些表达性特征,以不断推动TTS技术的发展。
论文标题、机构、论文链接和项目地址(如有)
1. 论文标题
STORYTTS: A HIGHLY EXPRESSIVE TEXT-TO-SPEECH DATASET WITH RICH TEXTUAL EXPRESSIVENESS ANNOTATIONS
2. 机构
上海交通大学人工智能研究院
3. 论文链接
https://arxiv.org/pdf/2404.14946.pdf
StoryTTS数据集的构建
1. 数据选择与检索
StoryTTS数据集的构建始于选择合适的数据源。本研究选择了一场名为“Zhi Sheng Dongfang Shuo”的讲故事表演,这是一种传统的中国口头艺术形式,表演者通过模仿不同的声音和角色来讲述故事,使其富有表现力和动听。这场表演基于历史小说,内容丰富,涵盖了多种语言结构和修辞手法。从公共网站上获取了这场表演的录音数据,整理成160个连续章节,每章大约24分钟,总时长约64小时。
2. 音频质量分析
为了确保数据集的音质达到高标准,我们对录音的信噪比(SNR)进行了估算。通过使用声音活动检测(VAD)工具计算静默段的噪声功率,估算出的SNR为32dB,显示出录音的高音质。此外,与其他常用的中文和英文TTS数据集进行比较,StoryTTS在音调的标准偏差上显著高于其他数据集,这进一步证明了其音频的表现力。
3. 语音分割与自动识别
在处理原始的粗略分段语音数据时,我们采用了三步法。首先,使用VAD工具将章节级的语音分割成语句。然后,由于缺少匹配的文本转录,我们使用了Whisper这一流行的语音识别模型来获取文本转录。通过这种方式,我们能够精确地切割语音,最终得到了33108对语音和文本的配对。
4. 手动纠正识别错误
由于表演中音调和语速的极大变化,语音识别结果的错误率较高。针对这一挑战,我们逐行仔细审查每个语音段,并纠正了识别错误。此外,我们还努力用相应文本中的适当词汇替换了语音中的拟声词。
5. 标点增强
标点在文本表达中起着至关重要的作用,能够通过感叹号传达惊讶或震惊的情绪,通过双引号表示角色对话或内心思维。尽管Whisper能够识别一些标点符号,但其表现仍有不足。因此,在文本审查过程中,我们仔细地进行了标点的更正和添加,以确保尽可能精确地使用标点符号。这种对标点准确性的关注也显著地促进了我们后续的文本情感分析工作。
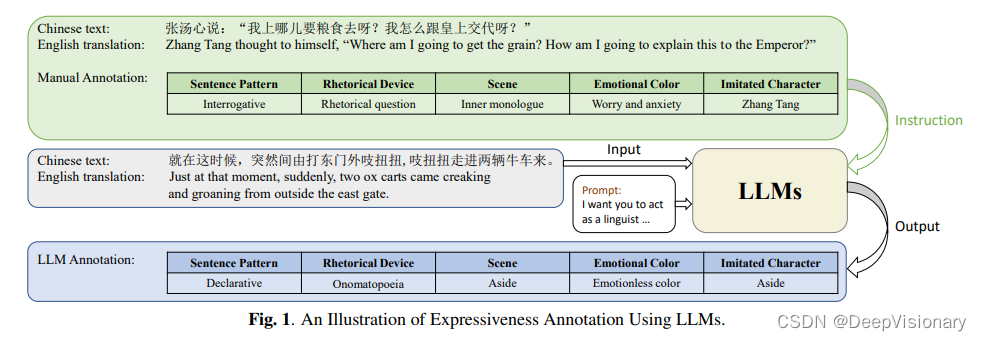
文本表达性的系统标注框架
1. 探索文本表达性的五个维度
在StoryTTS项目中,我们通过文学研究、语言学和修辞学等领域的深入分析,定义了文本表达性的五个关键维度。这些维度包括修辞手法、句式模式、场景、模仿角色和情感色彩。例如,修辞手法如夸张、对偶和拟声词等,可以增强文本的表现力;句式模式,如感叹句,可以激发听众的情感反应。此外,场景的设定,如角色扮演,通常包含丰富的情感内容,而旁白则可能缺乏情感元素。情感色彩的精确描述,如通过几个词汇概括句子的情感,比传统的分类方法更为精确。在模仿角色方面,表演者常常模仿角色的语言模式,例如在扮演老人时降低音调和放慢语速,而在模仿反派时则提高音调和加快语速。
2. 批量注释的实施:利用大型语言模型
为了高效地进行文本表达性的批量注释,我们采用了大型语言模型(LLMs),如GPT4和Claude2。这些模型不仅处理能力强大,而且成本相对较低,非常适合预算有限的个人或组织使用。在注释过程中,我们首先以语言学家的身份设定模型的角色,并向模型提供连贯文本的背景信息,强调文本中的各种表达元素,如拟声词、内心独白和角色扮演等。然后,我们指导模型按照特定的格式对每个句子进行注释,确保句式模式、场景、修辞手法和模仿角色等都被正确分类,每种情感色彩也被准确概括。
通过这种方法,我们不仅大大提高了注释的效率,还确保了注释的准确性和一致性。这对于后续的文本到语音合成研究,尤其是在提高合成语音的表现力方面,提供了宝贵的数据支持。
实验与结果
1. 模型架构与表达性编码器
在本研究中,我们构建了一个基于VQTTS的基线模型,该模型使用自监督的向量量化(VQ)声学特征而非传统的mel频谱。具体来说,它包括一个声学模型t2v和一个声码器v2w。T2v接受音素序列,然后输出VQ声学特征和辅助特征,这些特征包括音调、能量和声音的概率。V2w接收这些数据并合成波形。
为了充分利用我们的表达性注释,我们开发了一个表达性编码器。我们使用四个独立的可学习嵌入表来为模型提供四个标签的信息:句子模式、场景、修辞方法和模仿角色。对于每个句子,我们根据这四个表达标签分配四个类别编号,然后将这些编号输入到相应的嵌入表中,其向量维度分别为32、32、64和256。
在情感色彩的建模方面,我们采用了不同的模型结构。考虑到情感描述通常压缩为几个词,代表句子的总体情绪,而情绪可能在单个句子中变化。例如,在感叹句中,情绪通常在末尾加强。我们首先使用预训练的BERT提取整个句子的词级嵌入,然后使用Sentence BERT提取情感色彩的嵌入。通过这些嵌入之间的交叉注意力,我们旨在捕捉文本中不同位置的情绪分布,从而提高其表达的准确性。接着,我们根据词到音素的对应关系将结果上采样到音素级别,并将其与前四个嵌入一起添加到编码器输出中。
2. 实验设置
我们进行了实验,以评估五个文本表达性标签对合成语音表达性的影响。此外,我们还评估了同时使用所有这些标签的累积效果。对于这些实验,我们分别用300个周期训练了一个声学模型,批处理大小为8。声码器是共享的,我们在StoryTTS上训练了100个周期,批处理大小也为8。其余模型配置和参数与文献中的保持一致。每个实验都在单个2080 Ti GPU上进行。为了预处理文本数据,我们使用了内部的Grapheme-to-Phoneme(G2P)工具进行文本到音素的转换。我们还保留了5%的文本用于测试和验证集,其中测试集包括3个连续章节。为了获得真实的音素持续时间,我们使用Montreal Forced Aligner进行了强制对齐。
3. 语音合成评估:客观与主观指标
我们进行了平均意见得分(MOS)听力测试,邀请了20名母语听众对每个样本进行评分。MOS评分基于1-5的等级,以0.5为增量,置信区间为95%。在我们的测试中,我们指导听众特别评估合成语音的表达性,同时评估语音质量。对于客观评估,我们使用动态时间规整(DTW)计算了Mel倒谱失真(MCD)。此外,我们还分析了使用DTW计算的对数F0均方根误差(log-F0 RMSE)。MCD衡量一般语音质量,而log-F0 RMSE评估语音韵律的表现。这两个指标的较低值表明语音性能的声音质量和节奏更好。
结果
在客观和主观评分中,与基线模型相比,所有表达性标签的融合提供了最显著的增强。它在客观和主观指标中都显著优于其他设置,为模型提供了关于模仿角色和场景的更准确的信息。这种融合还受益于句子模式、修辞设备和情感色彩的互补性。
结论与未来工作方向
在本研究中,我们介绍了StoryTTS,这是一个从声学和文本两个角度都具有丰富表现力的文本到语音(TTS)数据集。StoryTTS基于一场普通话讲故事节目的录音构建,不仅在声学上质量高,而且在文本上具有丰富的表现力标注。通过系统地标注文本表现力,我们定义了五个独特的维度,包括修辞手法、句式、场景、模仿角色和情感色彩。此外,我们利用大型语言模型(LLM)进行批量标注,有效地提高了标注效率和准确性。
1. 实验验证
我们的实验结果显示,当TTS模型整合了StoryTTS中的文本表现力标注后,能够生成更具表现力的语音。这一结果不仅验证了我们数据集的有效性,也展示了文本表现力在提升语音合成质量中的重要作用。
2. 未来的研究方向
尽管本研究取得了一定的成果,但在表现力语音合成领域仍有许多值得探索的问题。未来的工作可以从以下几个方向进行:
-
整合声学和文本表现力:当前的研究主要集中在文本表现力的标注和应用上,将这些标注与声学表现力相结合,可能会进一步提升语音的自然度和表现力。
-
探索更多的文本表现力维度:本研究定义了五个文本表现力维度,未来可以探索更多的维度,如语调、停顿等,这可能会对表现力的理解和模拟提供更多的信息。
-
优化标注工具和方法:虽然使用LLM进行批量标注已经取得了不错的效果,但标注的准确性和效率仍有提升空间。研究和开发更高效、更准确的自动标注工具将是未来的一个重要任务。
-
跨文化和跨语言的表现力研究:StoryTTS是基于中文的数据集,将这种研究扩展到其他语言和文化,探索不同语言和文化背景下的表现力特征,将是一个有趣且具有挑战性的方向。
通过这些未来的研究方向,我们希望能够进一步推动表现力TTS技术的发展,使其在更多实际应用中发挥更大的作用。
致谢
在本研究的进行过程中,我们得到了多方面的支持和帮助,特此表达我们诚挚的感谢。
首先,我们要感谢中国国家自然科学基金项目(项目编号:92370206)对本研究的资助。此外,上海市科学技术重大项目(项目编号:2021SHZDZX0102)以及江苏省中国重点研发计划(项目编号:BE2022059)的支持也对我们的研究起到了至关重要的作用。
我们还要特别感谢所有参与StoryTTS数据集构建和实验的研究人员和技术人员。他们的辛勤工作和专业知识确保了研究数据的质量和实验的顺利进行。
此外,我们对上海交通大学人工智能研究院的同事们表示感谢,他们提供了宝贵的意见和技术支持,使我们能够顺利完成这项研究。
最后,我们感谢所有参与本文审稿的专家和编辑,他们的建议和指导帮助我们提高了研究的质量和论文的表达。
再次感谢所有支持和参与本研究的个人和机构,是你们的帮助使得这项研究能够成功完成。
关注DeepVisionary 了解更多深度学习前沿科技信息&顶会论文分享!
这篇关于英特尔StoryTTS:新数据集让文本到语音(TTS)表达更具丰富性和灵感的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





