本文主要是介绍StarRocks 跨集群数据迁移,SDM 帮你一键搞定!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:严祥光,StarRocks Active Contributor,StarRocks 存算分离核心研发,在社区中主要负责数据导入、跨集群同步、数据迁移和容灾等工作。
有时候,你可能会为以下需求而苦恼,苦苦搜索更好的解决方案:
情景一: 想象一下,你急需 验证新版本 , 但又不能影响线上已有集群的运行。你需要在不影响现有集群的基础上将数据迁移到新集群以进行验证。
情景二: 听说 StarRocks 新推出的 存算分离 模式超级给力,你肯定也想试试水,为业务降本增效吧?但问题来了,怎么把现有的数据平滑而高效地迁移到这个新模式下呢?
情景三: 你想实现 读写分离 ,即主集群写入数据后,自动同步到备集群,然后在备集群进行查询。
情景四: 你的业务需要实现 跨机房灾备 ,这样即使主机房集群挂了,也可以从其他机房的备集群快速启动。
我相信,正在使用 StarRocks 的你或许也正经历这些复杂的需求。别担心,今天我要教大家如何使用好 StarRocks 自带的 跨集群迁移解决方案- StarRocks Data Migration。 掌握了它,数据迁移将变得更轻松而高效,让你的数据处理如同行云流水般顺畅。
StarRocks Data Migration 简介
StarRocks Data Migration 是 StarRocks 推出的 跨集群 数据 同步 工具 。 借助该工具,你可以灵活的配置要同步的库、表、甚至整个集群的数据,然后无需人工干预,数据会按照配置好的规则自动从源集群同步到目标集群,而且效率非常高。StarRocks Data Migration 具有以下特点:
-
全量与增量同步支持:对于每张要同步的表,首先进行一次全量同步,然后周期性进行增量同步。
-
支持多种同步模式: 不仅 支持从存算一体集群同步到存算一体集群, 还 支持存算一体到存算分离集群 的 同步。 未来还将支持存算分离到存算一体的同步。
-
源集群 0 侵入:相较于市面上一些基于 Change log 的跨集群数据同步方案,StarRocks Data Migration 不需要用户升级源集群版本,也不会在同步过程中产生不必要的 Change log,因此源集群无需任何改变即可轻松完成数据迁移。
-
源集群影响小:通过设计多级限流机制,最大程度地保护源集群,避免影响其正常负载,用户可以放心将其用于生产环境。
-
同步效率高:数据同步采用直接点对点拷贝物理文件的方式,因此具有非常高的效率,具体的同步性能测试结果请参考后文。
关于 StarRocks Data Migration 的具体使用方法,请参考官方文档:https://docs.starrocks.io/zh/docs/administration/data_migration_tool
性能
同步效率是数据迁移同步中最重要的指标之一,因此我们进行了专项测试,以下是测试结果的展示。
测试环境
我们选择在阿里云上部署两个集群测试迁移速度,两个集群的规格如下:
td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}| 节点角色 | 节点数量 | 实例规格 | 磁盘大小(G) | 磁盘数量 | 磁盘类别 | 磁盘性能级别 |
|---|---|---|---|---|---|---|
| FE | 1 | ecs.c5.16xlarge | 1024 | 1 | cloud_essd | PL1 |
| BE | 10 | ecs.g5.16xlarge | 2048 | 3 | cloud_essd | PL1 |
测试过程中向源集群导入 SSB 1T 和 TPCH 1T 数据集,完成数据同步后,我们在目标集群查看每个表的同步事务的开始时间与提交时间,进而计算同步耗时和同步速度。
SSB 迁移
| 表名 | 数据量 | 同步开始 | 同步结束 | 同步耗时 | 同步速度 |
|---|---|---|---|---|---|
| customer | 4.056 GB | 11:30:04 | 11:30:08 | 4s | 1.014 GB/s |
| dates | 100.438 KB | 11:28:04 | 11:28:06 | 2s | 50.219 KB/s |
| lineorder | 457.092 GB | 11:26:04 | 11:27:05 | 61s | 7.4933 GB/s |
| part | 54.118 MB | 11:24:04 | 11:24:06 | 2s | 27.059 MB/s |
| supplier | 274.588 MB | 11:22:54 | 11:22:56 | 2s | 137.294 MB/s |
同步速度最快的为 lineorder 表: 7.4933 GB /s
TPCH 迁移
| 表名 | 数据量 | 同步开始 | 同步结束 | 同步耗时 | 同步速度 |
|---|---|---|---|---|---|
| customer | 38.611 GB | 12:23:05 | 12:23:17 | 12s | 1.60879 GB/s |
| lineitem | 580.284 GB | 12:15:05 | 12:16:29 | 84s | 6.90814 GB/s |
| nation | 6.343 KB | 12:17:05 | 12:17:07 | 2s | 3.1715 KB/s |
| orders | 186.446 GB | 12:21:05 | 12:21:32 | 27s | 6.9054 GB/s |
| part | 20.968 GB | 12:19:05 | 12:19:12 | 7s | 2.99543 GB/s |
| partsupp | 121.661 GB | 12:13:15 | 12:13:45 | 30s | 4.05537 GB/s |
| region | 2.458 KB | 12:23:05 | 12:23:07 | 2s | 1.229 KB/s |
| supplier | 2.453 GB | 12:17:05 | 12:17:08 | 3s | 0.81767 GB/s |
同步速度最快的为 lineitem 表: 6.90814 GB/s
原理
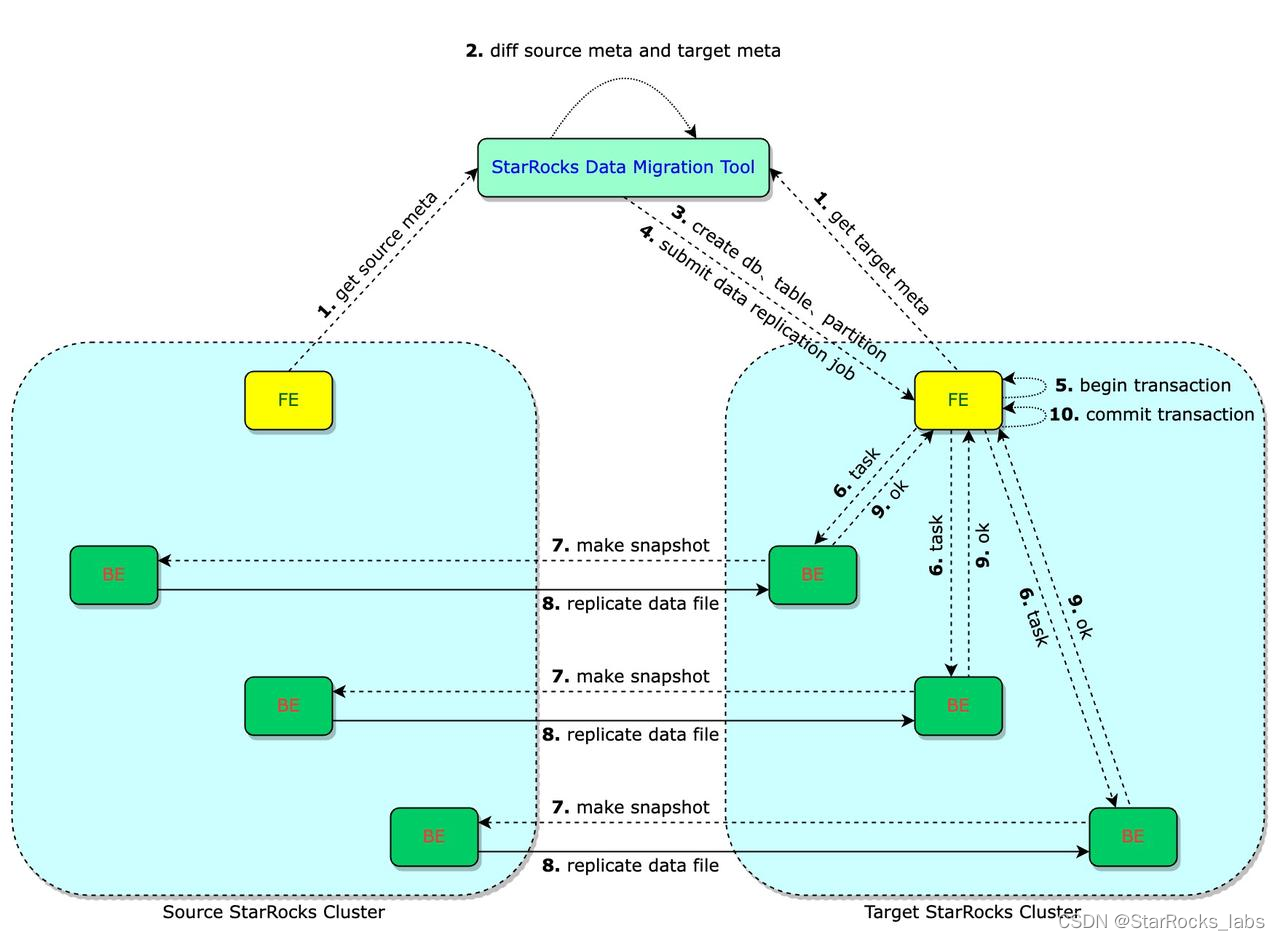
看完了 StarRocks Data Migration 工具的介绍和性能测试之后,接下来要带大家了解它是怎么实现的。
StarRocks Data Migration Tool 会周期性地获取源集群和目标集群的元数据进行对比,根据比对结果在目标集群创建所需的库、表、分区等,并提交数据同步任务。
数据同步以表为单位,每次同步启动一个事务,保证了同步任务的原子性,要么全部成功,要么全部失败,不会出现部分成功部分失败的情况,确保了数据一致性。
目标集群接受数据同步任务后,首先开启一个事务,然后向相关的 BE 下发同步任务。BE 收到任务后,先请求源集群进行一次快照,防止同步过程中数据被清理。目标集群在高负载情况下会拒绝新的数据同步任务,以进行自我保护。
快照是一个轻量级操作,不会影响源集群。一旦完成快照,目标集群就可以拷贝快照中的数据文件。数据拷贝采用 BE 之间的点对点方式,速度快,效率高,并在拷贝过程中自动限流,避免对源集群产生过大压力。
当本次同步任务的所有数据拷贝完成后,FE 即可提交同步事务,使本次同步数据立即生效。同时,事务提交后,源集群上生成的快照也会被清理,确保数据同步后的环境整洁。
使用指南与注意事项
-
源集群与目标集群的 BE 节点需要保证网络能够互通,因为涉及到数据拷贝。
-
数据同步不会自动结束,如果源集群持续有新数据写入,数据同步会一直进行。
-
数据同步过程中,可以查询目标集群中同步的表,但不要写入数据,否则会导致目标集群数据与源集群不一致。
-
StarRocks Data Migration 是 StarRocks 集群间的同步工具; 如果你需要将外部数据库数据导入StarRocks 你需要了解另一个工具:StarRocks migration tool(SMT)。
StarRocks migration tool(简称 SMT)是 StarRocks 提供的数据迁移工具,用于将源数据库的数据通过 Flink 导入 StarRocks。 其主要有两个功能:
根据源数据库和目标 StarRocks 集群的信息,生成 StarRocks 建表语句。
生成 Flink 的 SQL 客户端 可执行的 SQL 语句,以提交同步数据的 Flink job,简化链路中全量或增量数据同步流程。
文档链接:https://docs.starrocks.io/zh/docs/integrations/loading_tools/SMT/
更多交流,联系我们:https://wx.focussend.com/weComLink/mobileQrCodeLink/33412/8da64
这篇关于StarRocks 跨集群数据迁移,SDM 帮你一键搞定!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





