本文主要是介绍信奥数据“信息差”,让你惊掉下巴!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
✅ 信奥红利分析

暑假信奥赛即将到来,在全国各地赛事也越来越受到重视,但是似乎关于红利这一块各地如何,并没有太多的老师给各位家长分析清楚。

那么今天曹老师就主要给从各位新手家长分析一下信奥红利地区,在开始分析之前请大家看好上面的图记住自己在第几梯队。
✅ 年龄红利分析
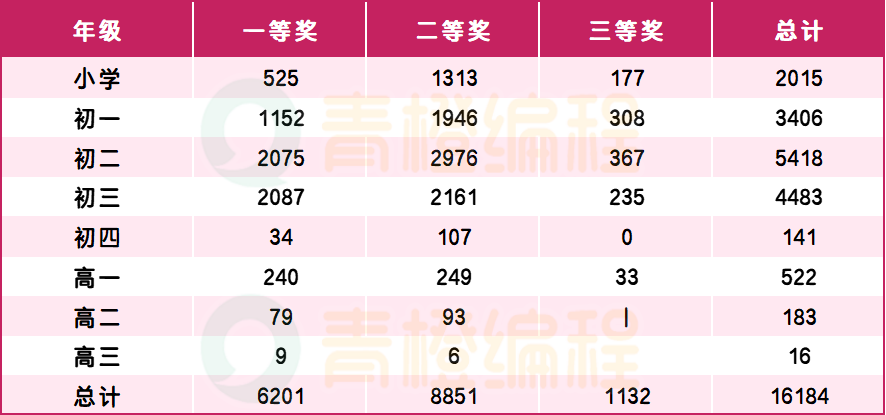
以2023年CSP-J普及组复赛获奖分析为例,在分析之前,先知道几个要素:
👉获奖证书作用:J组证书有校内分班(含综评)优势、小升初阶段点招择校、部分地区中考可走科技类特长,S组证书同样分班优势一般可为中高考特长生择校或者走三位一体(自主招生)
👉信奥参赛年级:不限制参赛年龄;
👉信奥试卷难度:全国为统一卷。
在明确上述几个点后,我们再来看上图的(2023年CSP-J组复赛成绩单),小学及初中阶段获奖的合计15,463人,其中最关键的两个阶段分别是小学阶段、初中(仅初一&初二,不含初三 因为初三获奖成绩拿到已经是高一了)。
小学获奖就意味着小升初的助力,初中就意味着中考的助力,那么我来考考各位新手家长:
# 答案将在文末公布 #
所以在这2个关键年龄段获奖的人一共10,839人,一模一样的试卷难度,其中小学就有2015个孩子是小学生占获奖人数的五分之一,因为CSP-J作为信奥赛入门级比赛,越早开始备考越有利,作为升学认证的门槛就越轻松,因为认证的门槛会随着年龄的增长而抬高例如小学复赛获奖即可,初中就需要指定获得复赛一二等奖。
✅ 地区红利分析
分析前先知道几个要素
👉竞赛分数线:竞赛的分数线是各省根据成绩评定的,非是全国一条分数线,所以如果省份竞争越激烈分数线就越高,否则反之。
👉获奖含金量:虽分数线不同,但是奖项荣誉是同样具有含金量的,这就造成了信息差,薄弱的省份分数线非常低,获奖难度也很低,往科技类发展就越轻松。
👉复赛试卷分值:共计4题,每题100分,合计总分400分。
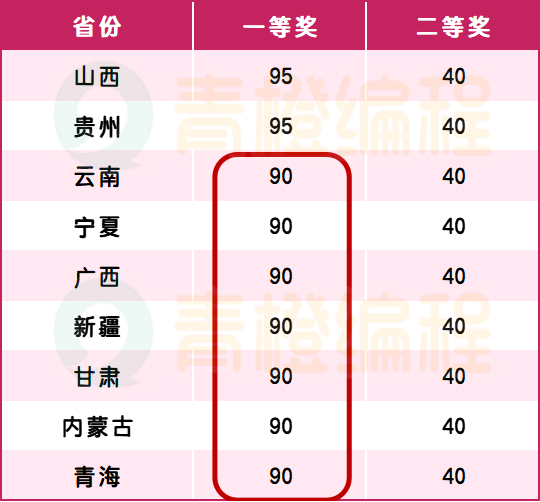
第一梯队(前10)的省份的分数线数据。

也就是说在这10个省份,一等奖的分数线,最高是重庆——250分。
最低的福建也需要190分才能拿到一等奖。而二等奖,需要拿到90分。
这个时候曹老师发现了一个现象,90分在第一梯队只能拿到二等奖,但放到新疆、青海这样的第三梯队省份,妥妥的一等奖。
云南、宁夏、广西、新疆、甘肃、内蒙古这六个省的一等奖分数线就是90分。
90分是什么概念,满分400分,四道题目只要能做对一题就够了。
像湖北、辽宁、河南、黑龙江、陕西、海南这样的省份,是排在中间的第二梯队。它们的分数线也不是特别高,100分多一点点。

这是部分省份的CSP-J晋级到第二轮的人数比例,最高的甘肃能到99%,最低的新疆也能到56%。

所以,这个差距是真真切切存在的,报名人数少,竞争少,自然获奖就容易很多。这其实就是信息差造成的红利。
✅ 以为获奖容易了?
为什么很多省份分数低、获奖率高,但是还是没什么参与?
👉1、教育信息差:普及覆盖率太低了
👉2、师资团队少:本地能拿结果的太少了
👉3、底子不够强:信息学能够做到的一定是锦上添花,而不是雪中送炭,学习的前提是自己本身学科能力就还不错,很多课程顾问会错误的表达为救命稻草!
选择了信息学,家长就得用业余时间去了解去学习规划,并不是交给了老师或者机构就好了,想学出成绩就需要投入不少的时间。
这样的获奖难度和奖项的含金量对比奥数
奥数:每年参赛人数有上百万人
信奥:每年参赛人数每年不到8万
但获奖名额却是差不多的,也就是说,信息学奥赛的参加人数,只是数学奥赛的十分之一都不到,但是获奖率却是后者的十倍之多!
✅ 投票题答案
答案:不能,因为对应阶段升学认可的是近三年的参赛获奖,小学组获得的荣誉已经超过三年了,需要在初中阶段重新参赛。
这篇文章确实干货太多了,如果有晦涩难懂的知识点,欢迎文章评论区留言老师给你解答~
✅ 资料领取
关注CSDN号:编程竞赛一站通
发送“0319”免费领取

《信奥习题集 电子版在线》
有大智慧的父母,总是能未雨绸缪
▼▼▼
♥ 青橙编程 ♥
让孩子学习有用的编程!

我知道你在看哟 ▼
这篇关于信奥数据“信息差”,让你惊掉下巴!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




