本文主要是介绍【三】DRF序列化进阶,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
序列化器的定义与使用
多表关联序列化
【1】准备工作
# settings.py
DATABASES = {'default': {# 数据库引擎选择使用MySQL'ENGINE': 'django.db.backends.mysql',# 指定数据库名字,需提前创建'NAME': 'books',# 指定数据库用户名'USER': 'root',# 指定数据库用户密码'PASSWORD': '123123',# 指定数据库连接IP'HOST': '127.0.0.1',# 指定数据库端口'PORT': 3306,# 指定数据库默认编码集(可选)'CHARSET': 'utf8mb4',}
}
【2】定制返回格式之source
# models.py
from django.db import modelsclass Book(models.Model):name = models.CharField(max_length=64)title = models.CharField(max_length=32)price = models.DecimalField(max_digits=8, decimal_places=2)publish_date = models.DateField()publish = models.ForeignKey(to='Publish', on_delete=models.SET_NULL, null=True)authors = models.ManyToManyField(to='Author')def __str__(self):return self.titleclass Publish(models.Model):name = models.CharField(max_length=32,)addr = models.CharField(max_length=64)# 该字段不是给models看的,而是给校验行组件使用的email = models.EmailField()def __str__(self):return self.nameclass Author(models.Model):name = models.CharField(max_length=32,null=True)age = models.IntegerField()def __str__(self):return self.name
- 创建一个序列化serial.py文件
from rest_framework import serializers
from rest_framework.exceptions import ValidationErrordef data_name(name):if name.startswith('shi'):raise ValidationError('不能用shi开头')else:return nameclass TaskSerializer(serializers.Serializer):# required=False表明该字段在反序列化时必须输入,默认True# allow_null 表明该字段是否允许传入None,默认False# default 反序列化时使用的默认值task_name = serializers.CharField(required=False,allow_null=True,default='默认字段',validators=[data_name])task_id = serializers.CharField(max_length=64,validators=[data_name])task_time = serializers.DateTimeField()class BookSerializer(serializers.Serializer):# source 定制返回字段名,跟name必须对应book_name = serializers.CharField(source='name')# 显示出版社名字-->字符串类型--》CharField 可以跨表查询book_publish = serializers.CharField(source='publish.name')# 所有字段都可以被转成CharFieldpublish_id = serializers.IntegerField(source='publish.id')title = serializers.CharField()price = serializers.IntegerField()publish = serializers.CharField()
book_name: 这是书籍的名称字段,source='name'表示它会从模型中的name字段获取数据。book_publish: 这是书籍的出版社名称字段,source='publish.name'表示它会从关联的出版社模型中的name字段获取数据。publish_id: 这是书籍的出版社ID字段,source='publish.id'表示它会从关联的出版社模型中的id字段获取数据。title: 这是书籍的标题字段,直接从模型中的title字段获取数据。price: 这是书籍的价格字段,直接从模型中的price字段获取数据。publish: 这是书籍的出版社字段。然而,在代码中没有指定source,这意味着它将尝试从模型中的publish字段获取数据。但是,publish字段是一个 ForeignKey 字段,它应该是一个模型实例,而不是字符串,因此这里会出现问题。
# views.py
from rest_framework.views import APIView
from Api02.models import Book,Task2
from Api02.serial import BookSerializer
from rest_framework.response import Responseclass BookView(APIView):# 查询所有图书def get(self,request):print(request.data)# {'name': '去死', 'price': '222', 'publish': '人民日报'}res_list = Book.objects.all()print(res_list)# <QuerySet [<Book: 剑气长城>, <Book: 低头不见脚趾>, <Book: 恐怖如斯>, <Book: 大师>]>serializer = BookSerializer(instance=res_list,many=True)return Response(serializer.data)
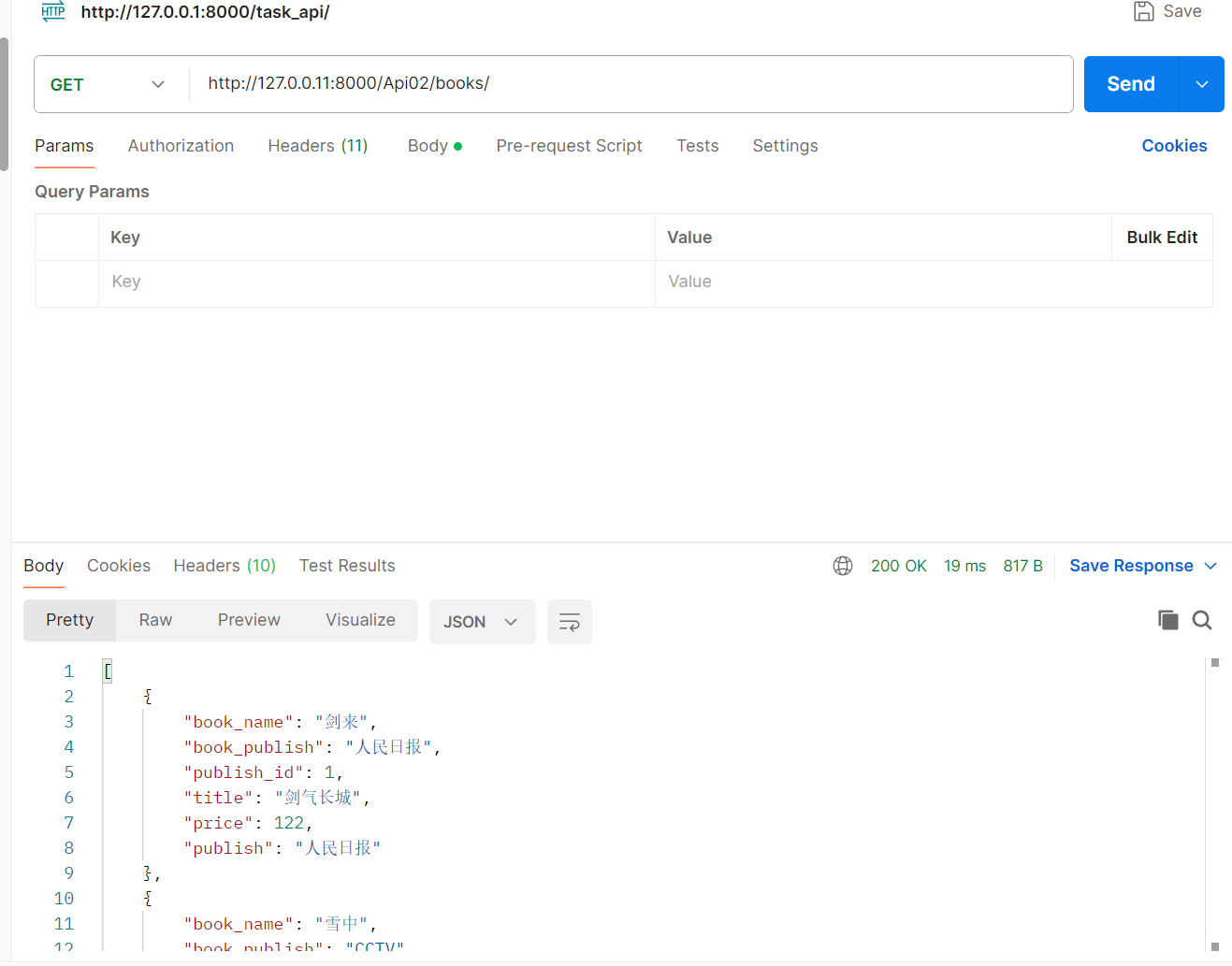
【3】定制返回字段模型类中书写方法
{name:书名,price:价格,publish:{name:出版社名,addr:地址},authors:[{},{}]}
返回详细信息
- 先在models.py要实现表中添加
def publish_detail(self)这个函数跟我定义的serial.py中的字段要一致publish_detail。
class Book(models.Model):name = models.CharField(max_length=64)title = models.CharField(max_length=32)price = models.DecimalField(max_digits=8, decimal_places=2)publish_date = models.DateField()publish = models.ForeignKey(to='Publish', on_delete=models.SET_NULL, null=True)authors = models.ManyToManyField(to='Author')def __str__(self):return self.name# 出版社对象@propertydef publish_detail(self):return {'name':self.publish.name,'addr':self.publish.addr}def authors_detail(self):list = []for author in self.authors.all():list.append({"name":author.name,'age':author.age})return list# serial.py
class BookSerializer(serializers.Serializer):name = serializers.CharField()title = serializers.CharField()price = serializers.IntegerField()publish_date = serializers.DateField()# publish = serializers.CharField() # 如果这样写,会把publish对象,打印的样子返回给前端# def __str__(self):# return self.name 你要在表中的publish写下这个# 出版社对象publish_detail = serializers.DictField()# 所有作者authors_detail = serializers.ListField()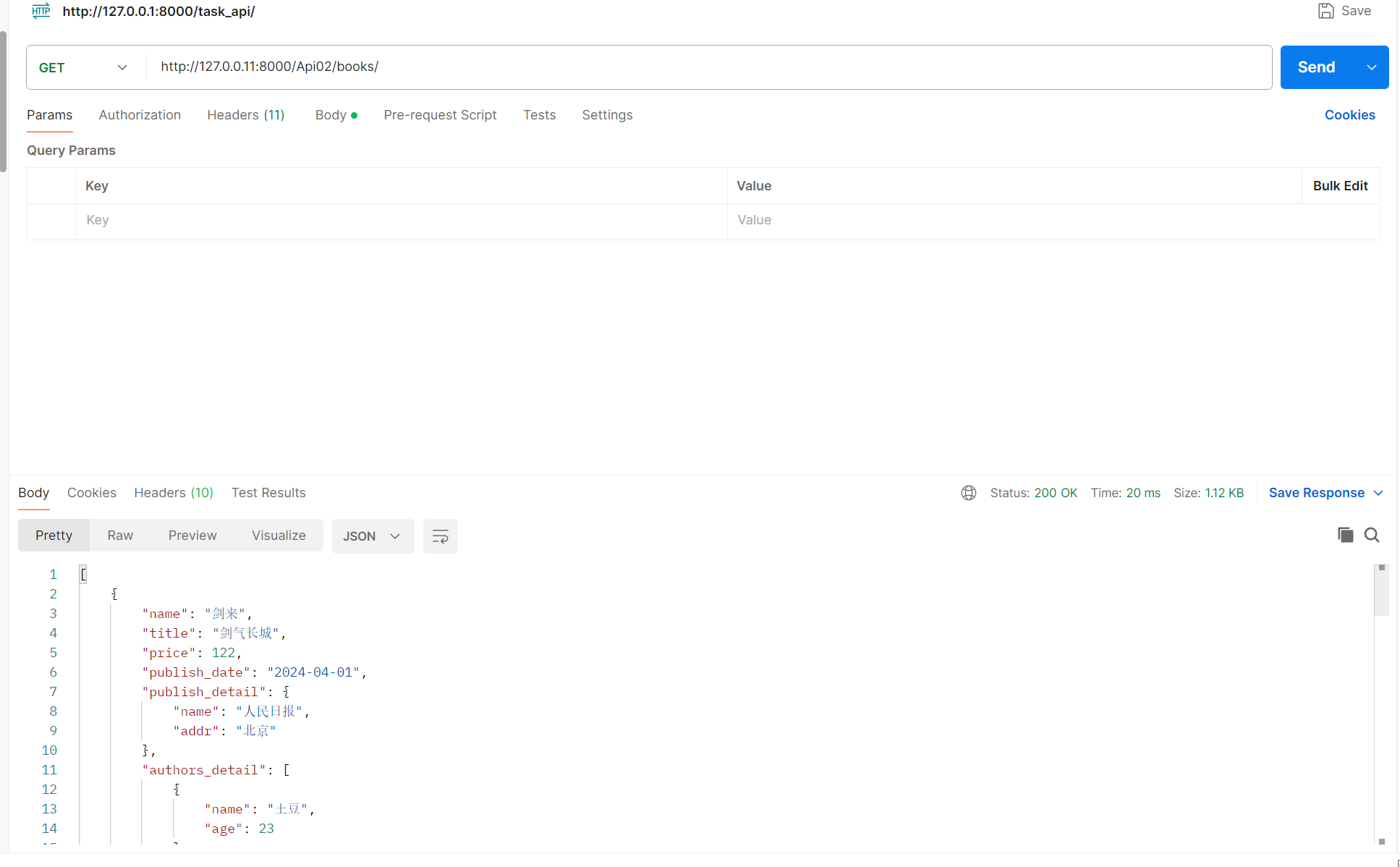
之前的更改名字也一样
就是serial.py里面的表的字段跟models.py文件中的函数一样就行def book_name(self):
class BookSerializer(serializers.Serializer):book_name = serializers.CharField()
class Book(models.Model):name = models.CharField(max_length=64)title = models.CharField(max_length=32)price = models.DecimalField(max_digits=8, decimal_places=2)publish_date = models.DateField()publish = models.ForeignKey(to='Publish', on_delete=models.SET_NULL, null=True)authors = models.ManyToManyField(to='Author')def __str__(self):return self.name# def book_name(self):# return self.name + 'xxxxxxx'

【4】通过SerializerMethodField定制字段
from rest_framework import serializers
from rest_framework.exceptions import ValidationError
class BookSerializer(serializers.Serializer):name = serializers.CharField()title = serializers.SerializerMethodField()def get_title(self, res):return res.title + '云开月明!!'price = serializers.IntegerField()publish_date = serializers.DateField()# publish = serializers.CharField() # 如果这样写,会把publish对象,打印的样子返回给前端# def __str__(self):# return self.name 你要在表中的publish写下这个# 出版社对象publish_detail = serializers.SerializerMethodField()def get_publish_detail(self, res):# res(任何obj、bai) 就是当前序列化到的book对象return {'name': res.publish.name, 'addr': res.publish.addr, 'id': res.pk}# 作者对象authors_detail = serializers.SerializerMethodField()def get_authors_detail(self, obj):data_list = []for i in obj.authors.all():data_list.append({'name': i.name, 'age': i.age, 'id': i.id})return data_list
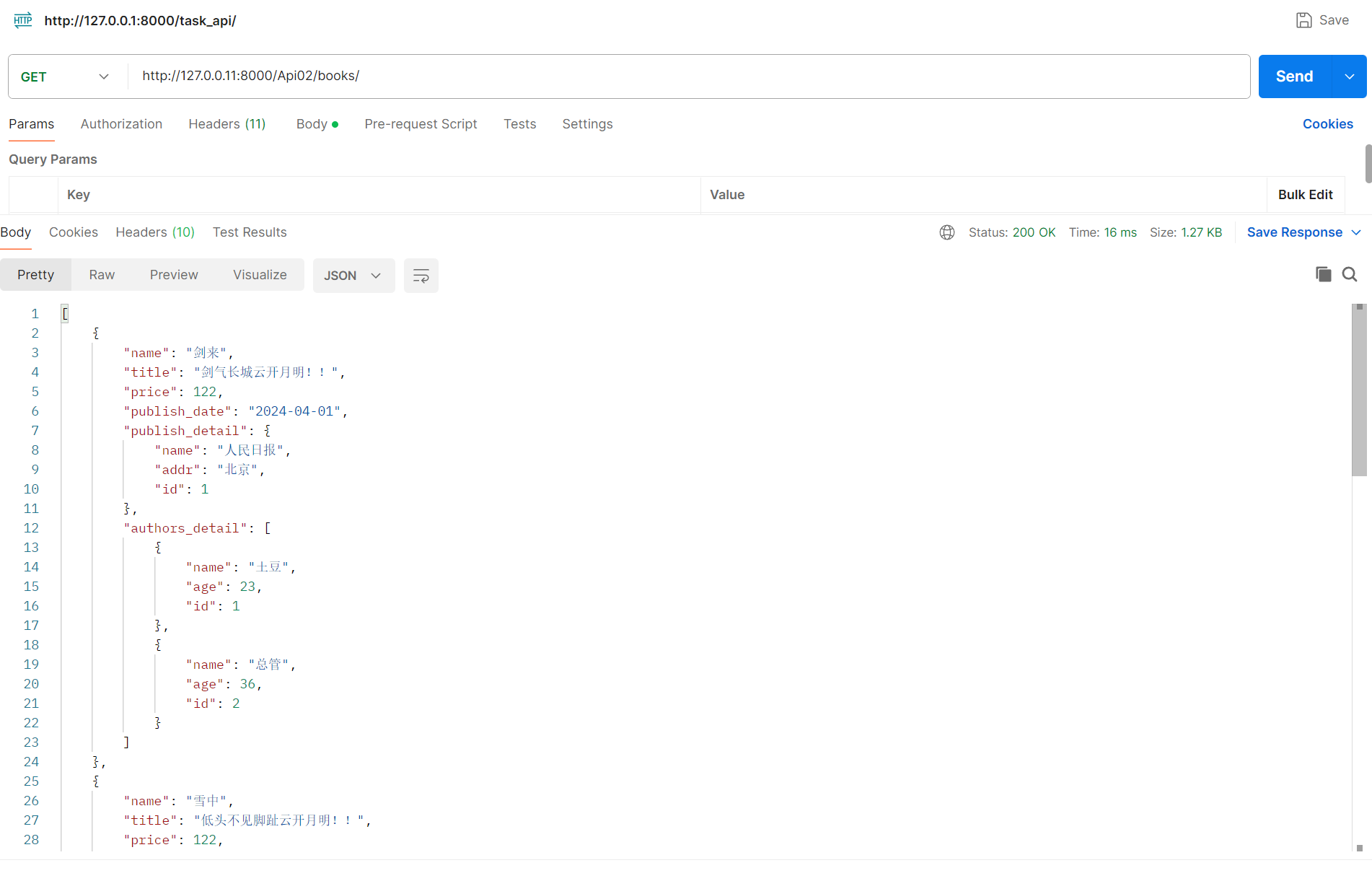
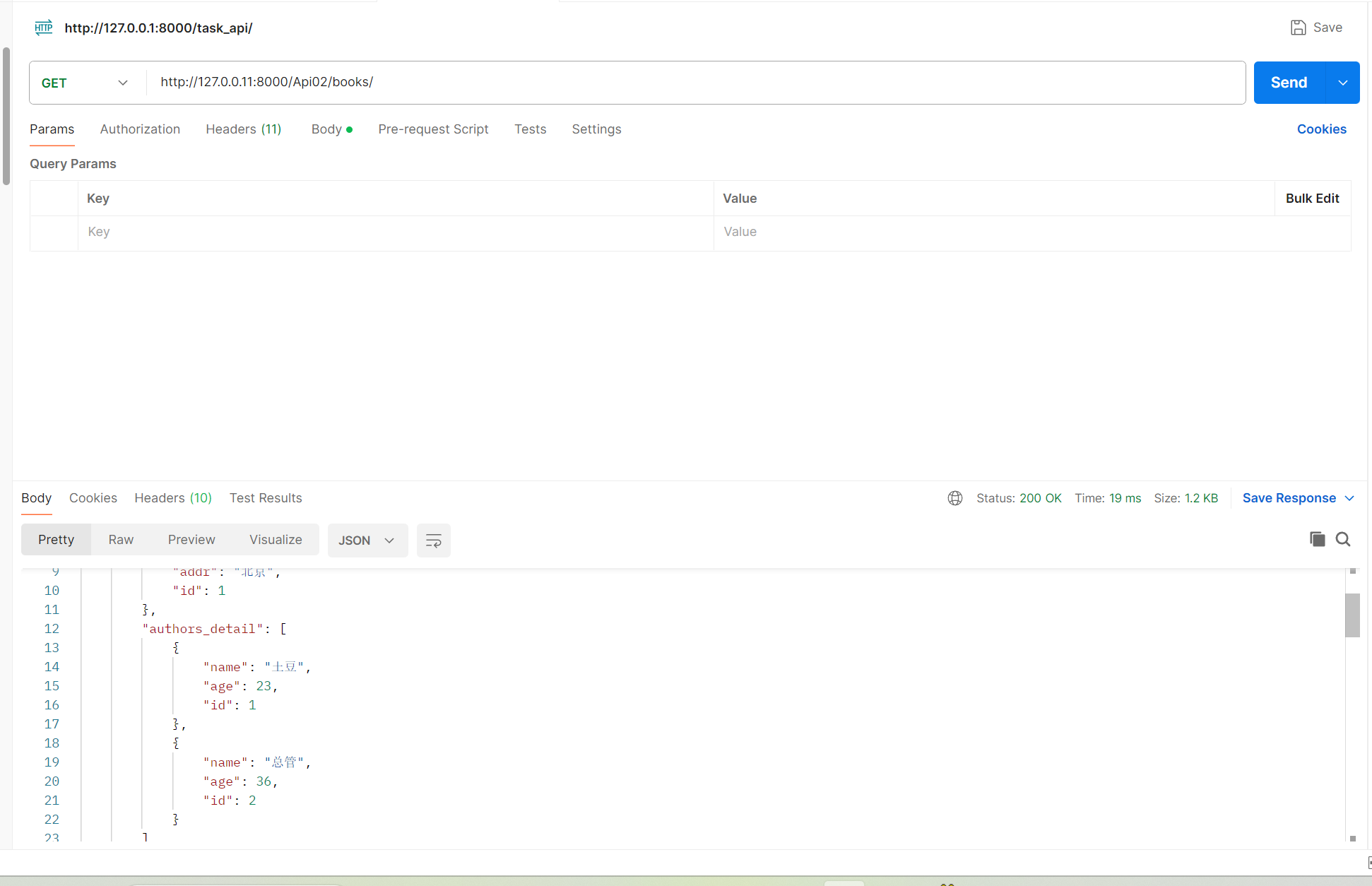
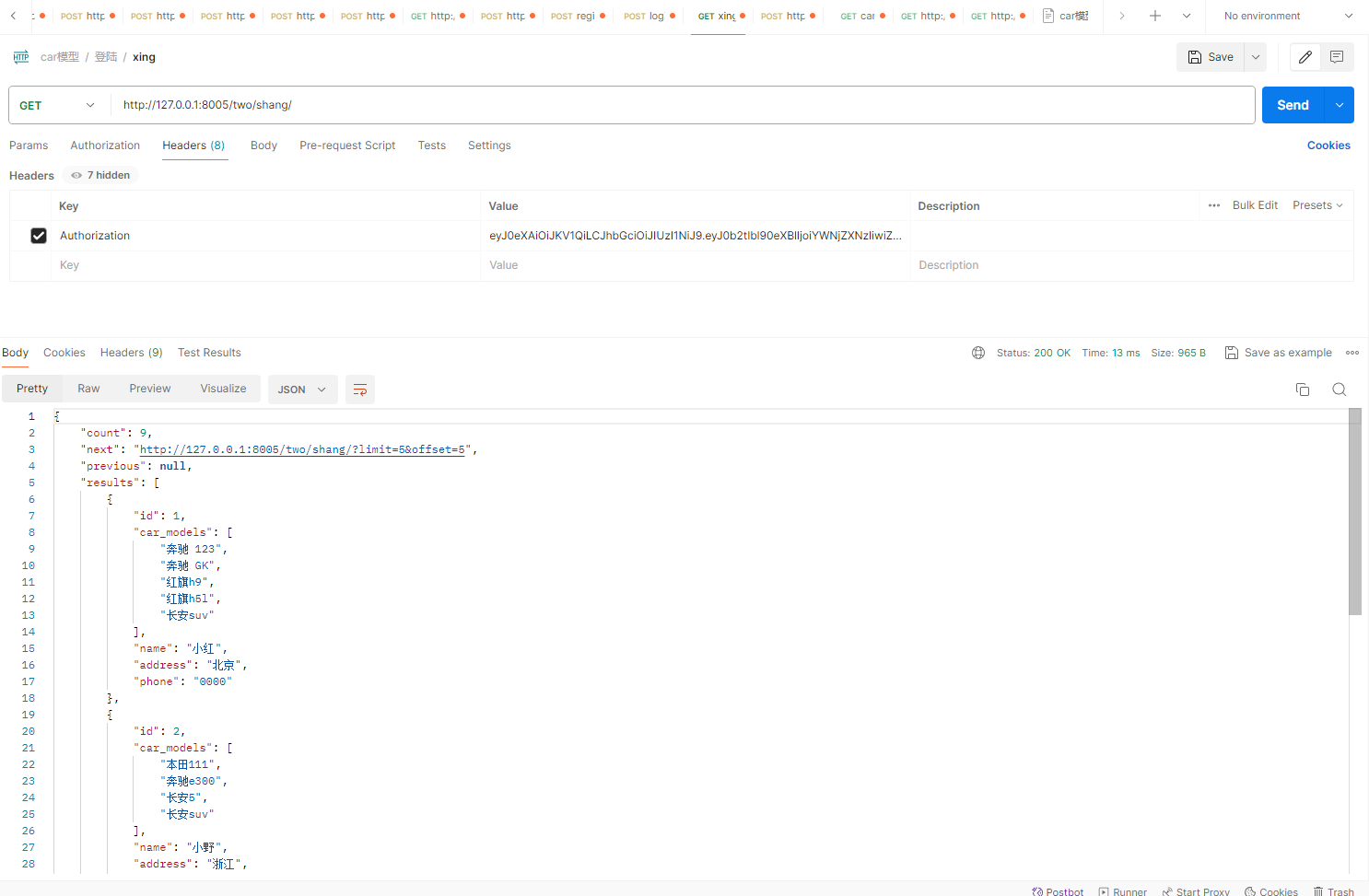
Distributor经销商跟CarModel表车型是多对多关系
class DistributorSerializer(serializers.ModelSerializer):car_models = serializers.SlugRelatedField('''
many=True 表示这是一个多对多关系,即一个经销商可能销售多个车型。
read_only=True 表示该字段是只读的,不能用于创建或更新对象。
slug_field='name' 指定了作为标识的字段名,在这里是 CarModel 表中的 name 字段。这意味着在序列化时,将使用 CarModel 对象的 name 字段来表示关联的车型。'''many=True,read_only=True,slug_field='name')class Meta:model = Distributorfields = '__all__'
# models.py
# 车厂
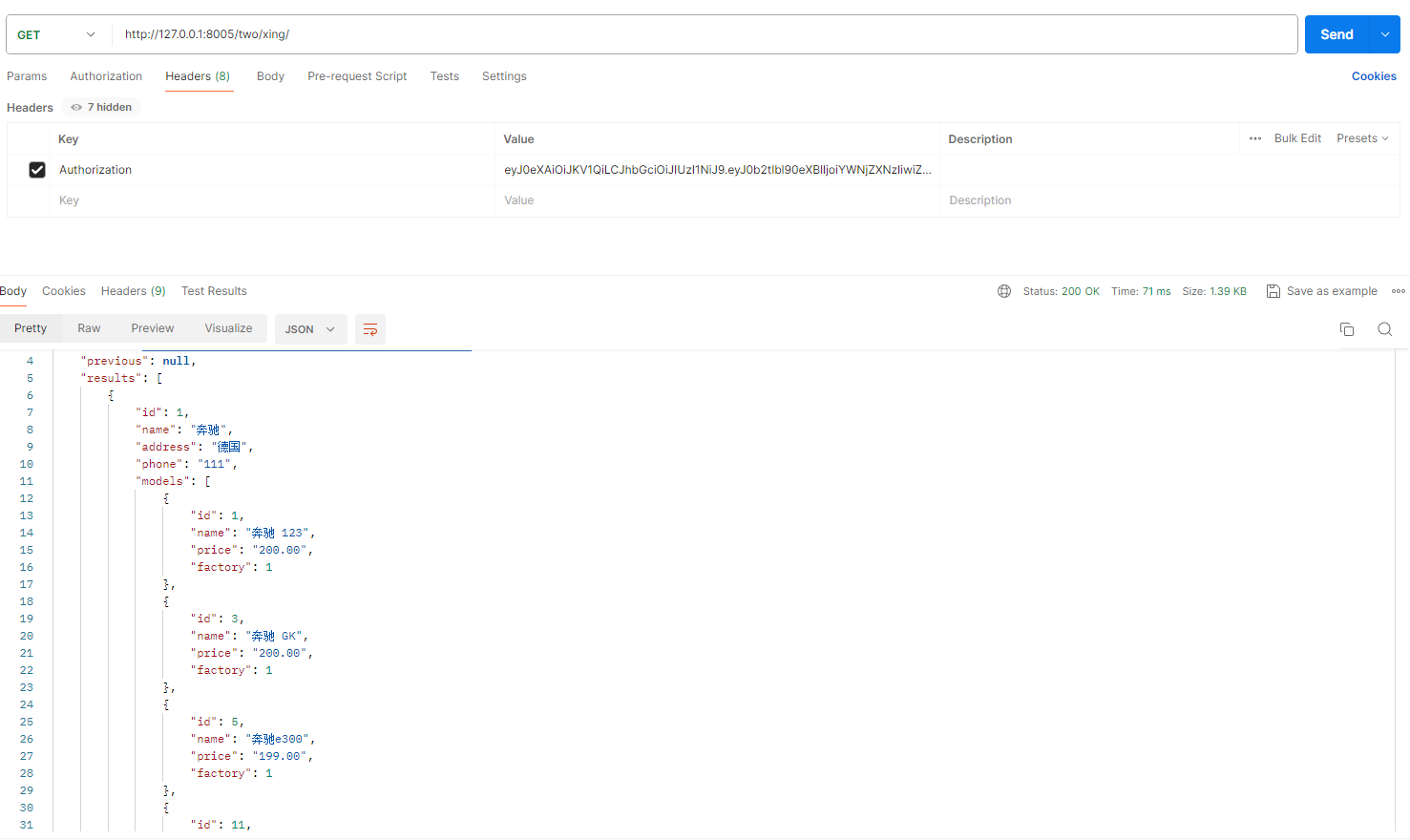
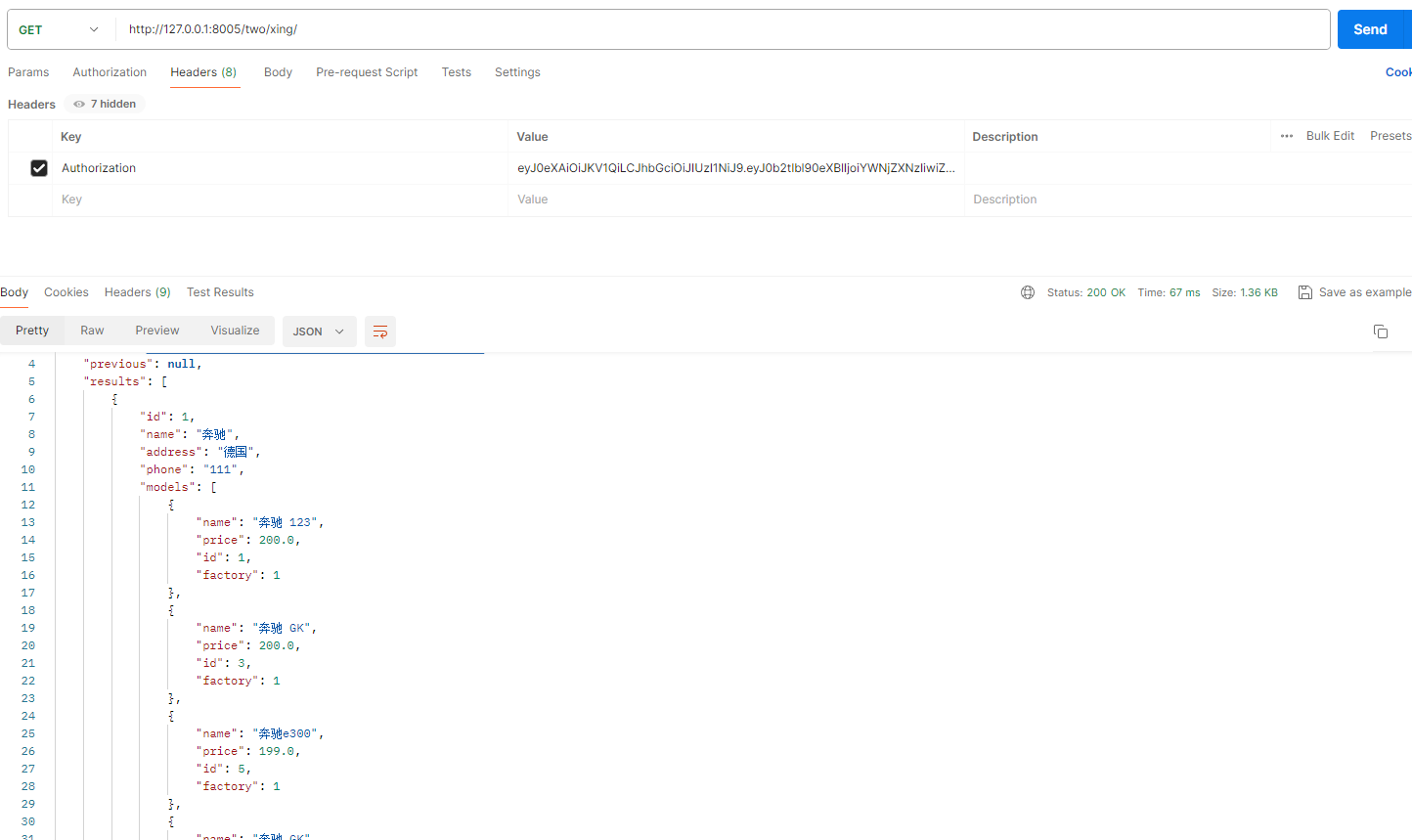
class CarFactory(models.Model):name = models.CharField(max_length=100)address = models.CharField(max_length=200)phone = models.CharField(max_length=20)def __str__(self):return self.name# 车型
class CarModel(models.Model):name = models.CharField(max_length=100)price = models.DecimalField(max_digits=10, decimal_places=2)# 一对多factory = models.ForeignKey(CarFactory, on_delete=models.CASCADE, related_name='models')def __str__(self):return self.name# serilaer.py
# 一对多关系
class CarFactorySerializer(serializers.ModelSerializer):models = serializers.SerializerMethodField()def get_models(self, obj):# 获取与当前车厂相关联的所有车型models = obj.models.all()# 序列化车型数据serializer = CarModelSerializer(models, many=True)return serializer.dataclass Meta:model = CarFactoryfields = ('id', 'name', 'address', 'phone', 'models')
def get_models(self, obj):# 获取与当前车厂相关联的所有车型car_models = obj.models.all()# 序列化车型数据serialized_models = []for car_model in car_models:serialized_model = {'name': car_model.name,'price': car_model.price,'id': car_model.pk,'factory': obj.pk # 车厂的主键作为车型的工厂信息}serialized_models.append(serialized_model)return serialized_modelsclass Meta:model = CarFactoryfields = ('id', 'name', 'address', 'phone', 'models')
多表关联反序列化
【5】定制返回之子序列化
这个的重点就是要定义一个字序列化的类PublishSerializer里面的字段名是要表中的有的字段名(列名)
当使用子序列化器时,有几个要注意的重点:
- 字段名和源字段的匹配: 确保在子序列化器中使用的
source参数与模型中的字段名匹配。这样才能正确地将父对象的属性传递给子序列化器进行序列化。 - 多对多关系处理: 如果处理的是多对多关系,确保在子序列化器中设置
many=True参数,以表示这是一个多个对象的集合。 - 数据验证: 子序列化器也可以执行数据验证。确保在子序列化器中定义了适当的验证规则,以确保父对象和子对象的数据都被正确验证。
# 子序列化class PublishSerializer(serializers.Serializer):id = serializers.IntegerField()name = serializers.CharField()addr = serializers.CharField()email = serializers.EmailField()class AuthorSerializer(serializers.Serializer):id = serializers.IntegerField()name = serializers.CharField()age = serializers.IntegerField()class BookSerializer(serializers.Serializer):name = serializers.CharField()title = serializers.CharField()price = serializers.IntegerField()publish_date = serializers.DateField()# 如果这样写,会把publish对象,打印的样子返回给前端# publish = PublishSerializer()# 修改字段的名字"publish_res"# 一对多关系publish_res = PublishSerializer(source='publish')# # 修改字段的名字"authors_list"# 多对多关系authors_list = AuthorSerializer(source='authors',many=True)

【6】反序化的保存
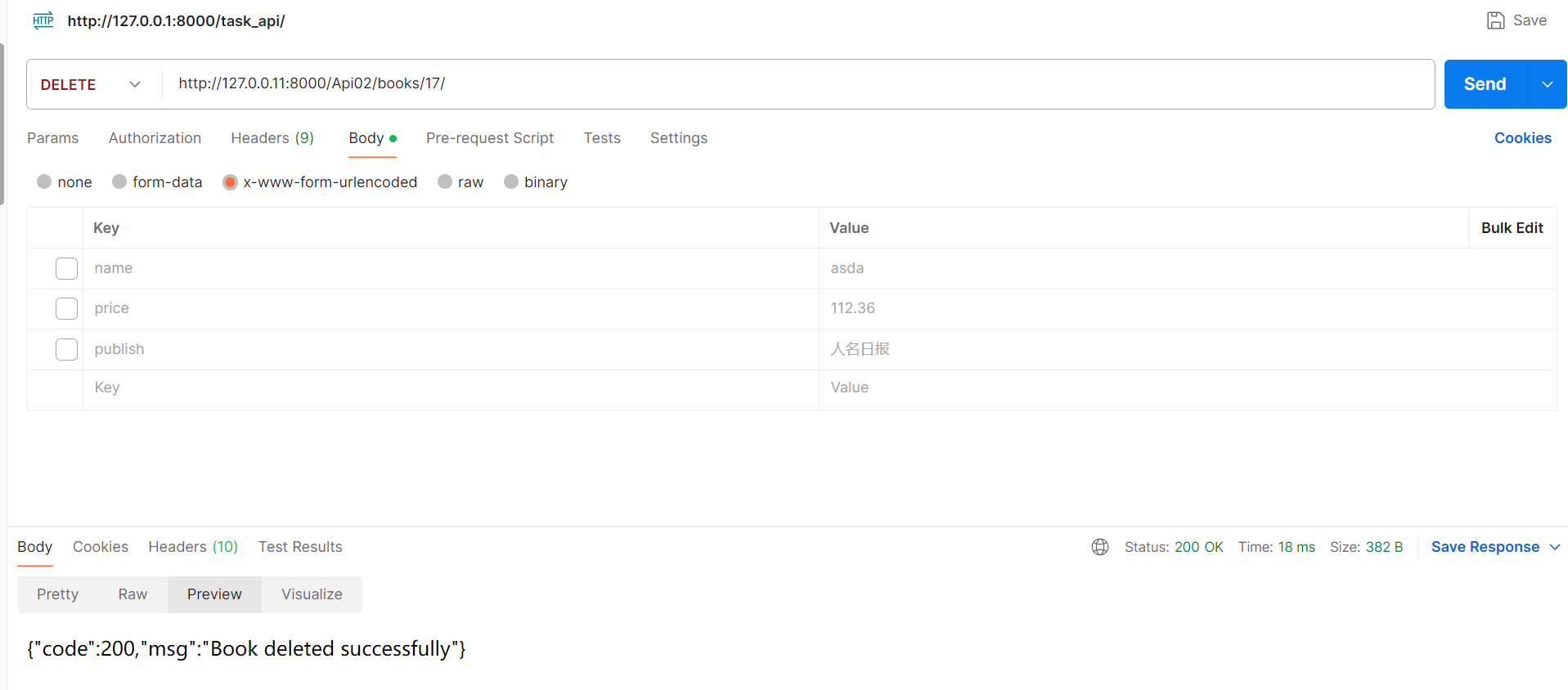
【1】删除
class BookDetailView(APIView):def delete(self, request, pk):instance = Book.objects.filter(pk=pk).first()if not instance:return Response({'code': 404, 'msg': 'Book not found'}, status=status.HTTP_404_NOT_FOUND)instance.delete()return Response({'code': 200, 'msg': 'Book deleted successfully'}, status=status.HTTP_200_OK)
在路由配置中,path('books/<int:pk>/', BookDetailView.as_view()) 表示处理单个书籍的操作,包括查找、更改和删除。而 path('books/', BookView.as_view()) 则表示处理多个书籍的操作,包括查找全部和添加。
from django.urls import path
# BookView、BookDetailView 这个就是我在views.py 定义的类
from Api02.views import BookView,BookDetailView #urlpatterns = [path('books/', BookView.as_view()),path('books/<int:pk>/', BookDetailView.as_view()),]
第一种方法
class PublishSerializer(serializers.ModelSerializer):# id = serializers.IntegerField()# name = serializers.CharField()# addr = serializers.CharField()# email = serializers.EmailField()class Meta:model = Publishfields = ['id', 'name', 'addr', 'email']class AuthorSerializer(serializers.ModelSerializer):# id = serializers.IntegerField()# name = serializers.CharField()# age = serializers.IntegerField()class Meta:model = Authorfields = ['id', 'name', 'age']class BookSerializer(serializers.ModelSerializer):# 如果这样写,会把publish对象,打印的样子返回给前端# publish = PublishSerializer()# 修改字段的名字"publish_res"publish_res = PublishSerializer(source='publish')authors_l = AuthorSerializer(source='authors', many=True)class Meta:model = Bookfields = ['id','name', 'title', 'price', 'publish_date', 'publish_res', 'authors_l', 'delete']
第二种方法
class PublishSerializer(serializers.ModelSerializer):id = serializers.IntegerField()name = serializers.CharField()addr = serializers.CharField()email = serializers.EmailField()# class Meta:# model = Publish# fields = ['id', 'name', 'addr', 'email']class AuthorSerializer(serializers.ModelSerializer):id = serializers.IntegerField()name = serializers.CharField()age = serializers.IntegerField()# class Meta:# model = Author# fields = ['id', 'name', 'age']class BookSerializer(serializers.ModelSerializer):id = serializers.IntegerField()name = serializers.CharField()title = serializers.CharField()price = serializers.IntegerField()publish_date = serializers.DateField()# 如果这样写,会把publish对象,打印的样子返回给前端# publish = PublishSerializer()# 修改字段的名字"publish_res"publish_res = PublishSerializer(source='publish')authors_l = AuthorSerializer(source='authors', many=True)class Meta:model = Bookfields = ['id','name', 'title', 'price', 'publish_date', 'publish_res', 'authors_l', 'delete']
【2】更新
class BookDetailView(APIView):def put(self, request, pk):# instance 就是序列化的 res_data就是反序列化的pk = Book.objects.filter(pk=pk).first()print(pk)res_data = BookSerializer(data=request.data, instance=pk)if res_data.is_valid():# 验证过后的数据print(res_data.validated_data)# 保存数据res_data.save()return Response({'code': 200, "msg": res_data.data})else:return Response({'code': 404, 'msg': res_data.errors})
这个两个路由跟上述一样
from django.urls import path
# BookView、BookDetailView 这个就是我在views.py 定义的类
from Api02.views import BookView,BookDetailView #urlpatterns = [path('books/', BookView.as_view()),path('books/<int:pk>/', BookDetailView.as_view()),]
ModelSerializer使用
ModelSerializer 是 Django REST Framework 提供的一个便捷的序列化器类,用于简化与数据库模型的交互。它可以自动根据模型字段生成对应的序列化字段,并提供默认的序列化和反序列化逻辑。
在序列化组中,你可以使用 ModelSerializer 来快速地将数据库模型转换为 JSON 格式的数据,或者将 JSON 格式的数据反序列化为模型对象。
# ModelSerializer使用class PublishSerializer(serializers.ModelSerializer):class Meta:model = Publishfields = ['id', 'name', 'addr', 'email']class AuthorSerializer(serializers.ModelSerializer):class Meta:model = Authorfields = ['id', 'name', 'age']class BookSerializer(serializers.ModelSerializer):class Meta:model = Bookfields = '__all__'# fields=['id','name','publish_detail','authors_list']extra_kwargs = {'name': {'max_length': 8}, # 限制name不能超过8'publish': {'write_only': True},'authors': {'write_only': True},}# 自己再重写的字段# 这个字段用来做序列化publish_detail = PublishSerializer(source='publish',read_only=True)# 这个字段用来做序列化authors_list = AuthorSerializer(source='authors', many=True,read_only=True)
这样要注意如果没有加上子序列化这种方法
class PublishSerializer(serializers.ModelSerializer):class Meta:model = Publishfields = ['id', 'name', 'addr', 'email']class AuthorSerializer(serializers.ModelSerializer):class Meta:model = Authorfields = ['id', 'name', 'age']# views.py就必须在加上 pk = Book.objects.filter(pk=pk).first()否则就会报错def put(self, request, pk):pk = Book.objects.filter(pk=pk).first()print(pk)res_data = BookSerializer(data=request.data, instance=pk)if res_data.is_valid():# 验证过后的数据print(res_data.validated_data)# 保存数据res_data.save()return Response({'code': 200, "msg": res_data.data})else:return Response({'code': 404, 'msg': res_data.errors})
第二种
这里要注意在输入的时候ID这个就是必填字段了
class BookSerializer(serializers.Serializer):id = serializers.IntegerField()name = serializers.CharField()title = serializers.CharField()price = serializers.IntegerField()publish_date = serializers.DateField()# 反序列化保持最要多表关联publish_save = serializers.IntegerField(source='publish',write_only=True)authors = serializers.ListField(write_only=True)# 更新def update(self, instance, validated_data):publish_id = validated_data.pop('publish')authors = validated_data.pop('authors')# 使用instance.pk获取主键值book_qs = Book.objects.filter(pk=instance.pk)# 使用update更新实例book_qs.update(**validated_data, publish_id=publish_id)# 获取更新后的实例instance = book_qs.first()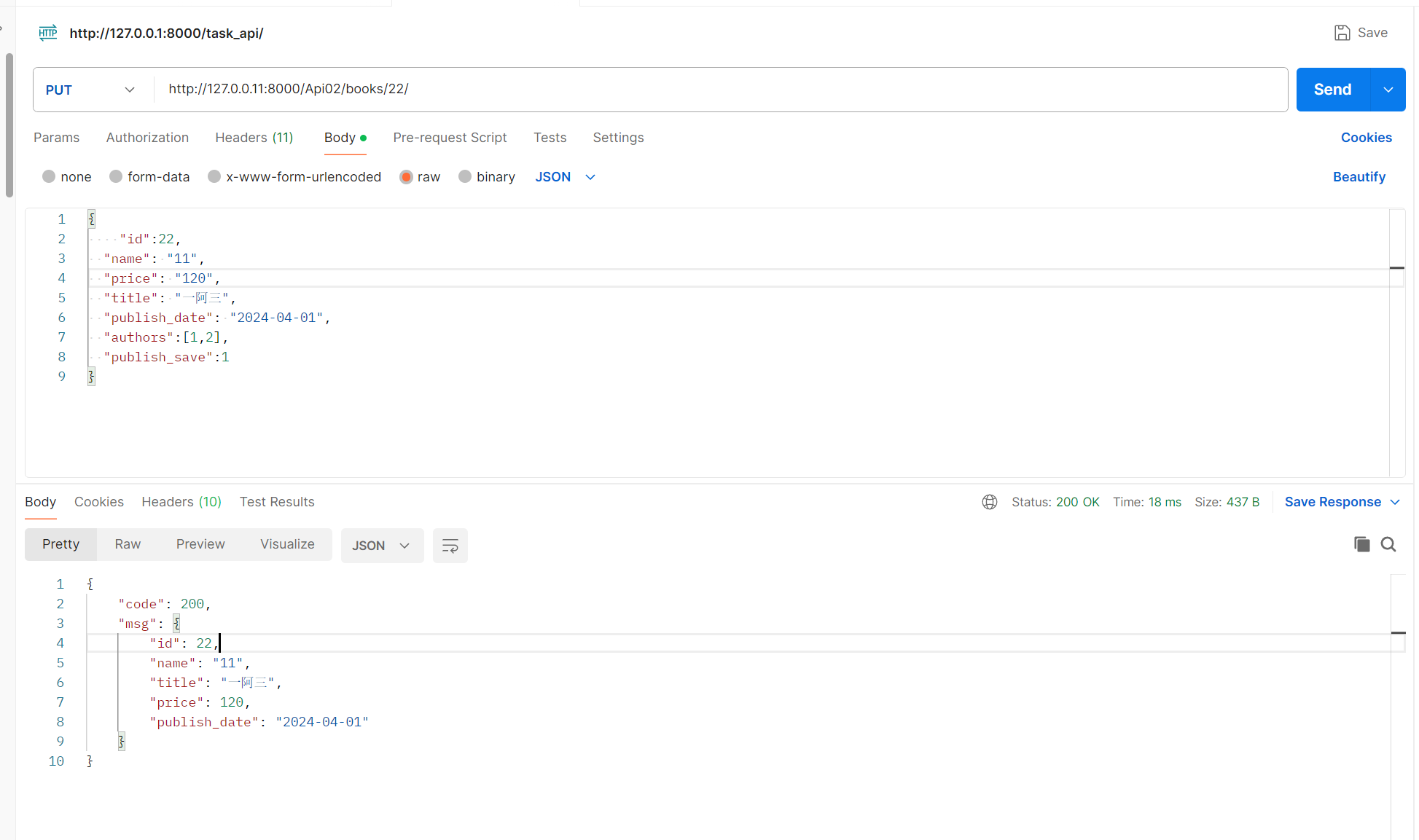

【3】添加
class BookView(APIView):def post(self, request):res_data = BookSerializer(data=request.data)print(res_data)if res_data.is_valid():# 验证过后的数据print(res_data.validated_data)# 保存数据res_data.save()return Response(res_data.data, status=status.HTTP_201_CREATED)else:return Response({'code': 404, 'msg': res_data.errors})
# 反序列化的保存
class BookSerializer(serializers.Serializer):name = serializers.CharField()title = serializers.CharField()price = serializers.IntegerField()publish_date = serializers.DateField()# 反序列化保持最要多表关联publish_save = serializers.IntegerField(source='publish',write_only=True)authors = serializers.ListField(write_only=True)
#
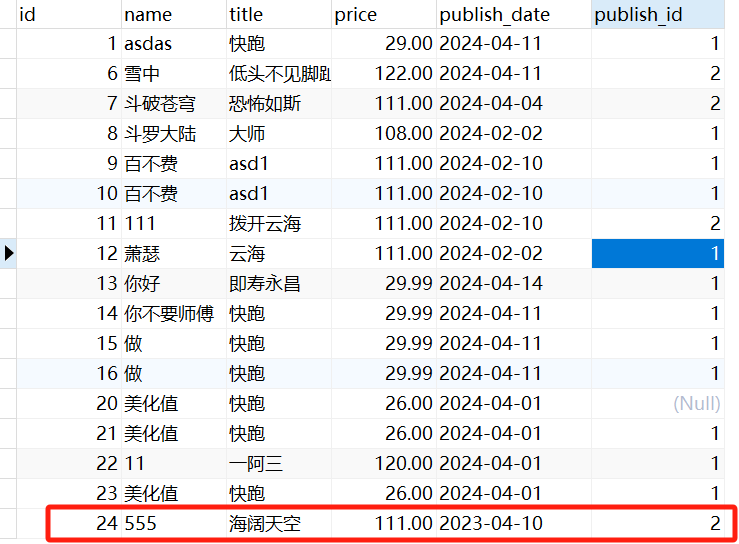
# # 添加def create(self, validated_data):publish_id = validated_data.pop('publish')authors = validated_data.pop('authors')book = Book.objects.create(**validated_data, publish_id=publish_id)book.authors.add(*authors)return book
!
这篇关于【三】DRF序列化进阶的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







