本文主要是介绍用自己的数据训练和测试“caffenet”,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本次实验本来参考examples/imagenet下的readme.txt进行,但因为数据集过于庞大,所以模拟学习,参考薛开宇的学习方式,模仿搭建自己的数据库。
首先在caffe/data下新建文件夹myself,然后在网上下载猫、鸟、狗的训练图片各50张,测试图片17,11,14张。为了方便,把图片名修改,使用python,代码如下:
import os;
def rename():count=0;name="dog";path='/home/jack/caffe/data/myself/train/dog';filelist=os.listdir(path)for files in filelist:olddir=os.path.join(path,files);if os.path.isdir(olddir):continue;filename=os.path.splitext(files)[0];filetype=os.path.splitext(files)[1];newdir=os.path.join(path,name+str(count)+filetype);os.rename(olddir, newdir);count+=1;
rename();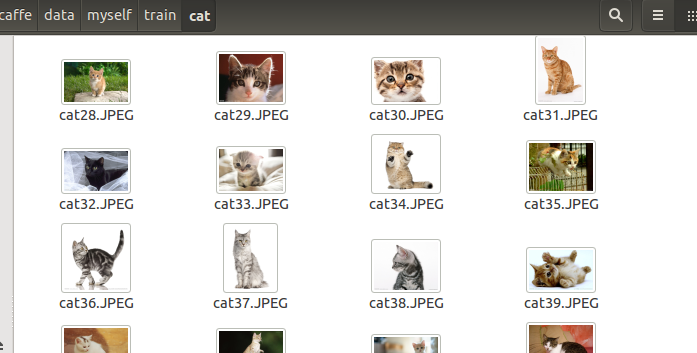
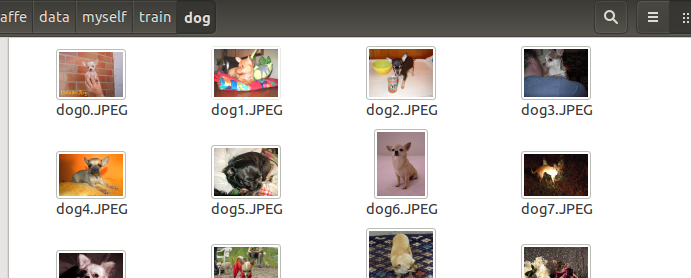
重复使用下面这几句话,最后将三类训练数据的文件名都复制到一起。至于文件格式为何要这样.是参考data/ilsvrc12下的train.txt和val.txt.
find train/dog -name *.JPEG |cut -d '/'这篇关于用自己的数据训练和测试“caffenet”的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




