本文主要是介绍4.用python爬取保存在text中的格式为m3u8的视频,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、爬取过程详解
- 1.寻找视频的m3u8链接
- 2.从网页源码中寻找视频的m3u8链接的第二部分内容
- 3.从视频的m3u8链接获取视频
- 二、完整的代码
一、爬取过程详解
1.寻找视频的m3u8链接
这个文档承接了爬虫专栏的 第一节.python爬虫爬取视频网站的视频可下载的源url,首先我们打开一个爬取的可以播放的视频链接,然后按F12,然后选择Network,可以看到这个网站的视频不是mp4格式的视频,而是m3u8格式的视频流,这样就不能按照mp4格式那样直接下载了,就需要下载视频流的所有视频文件然后合并得到视频。
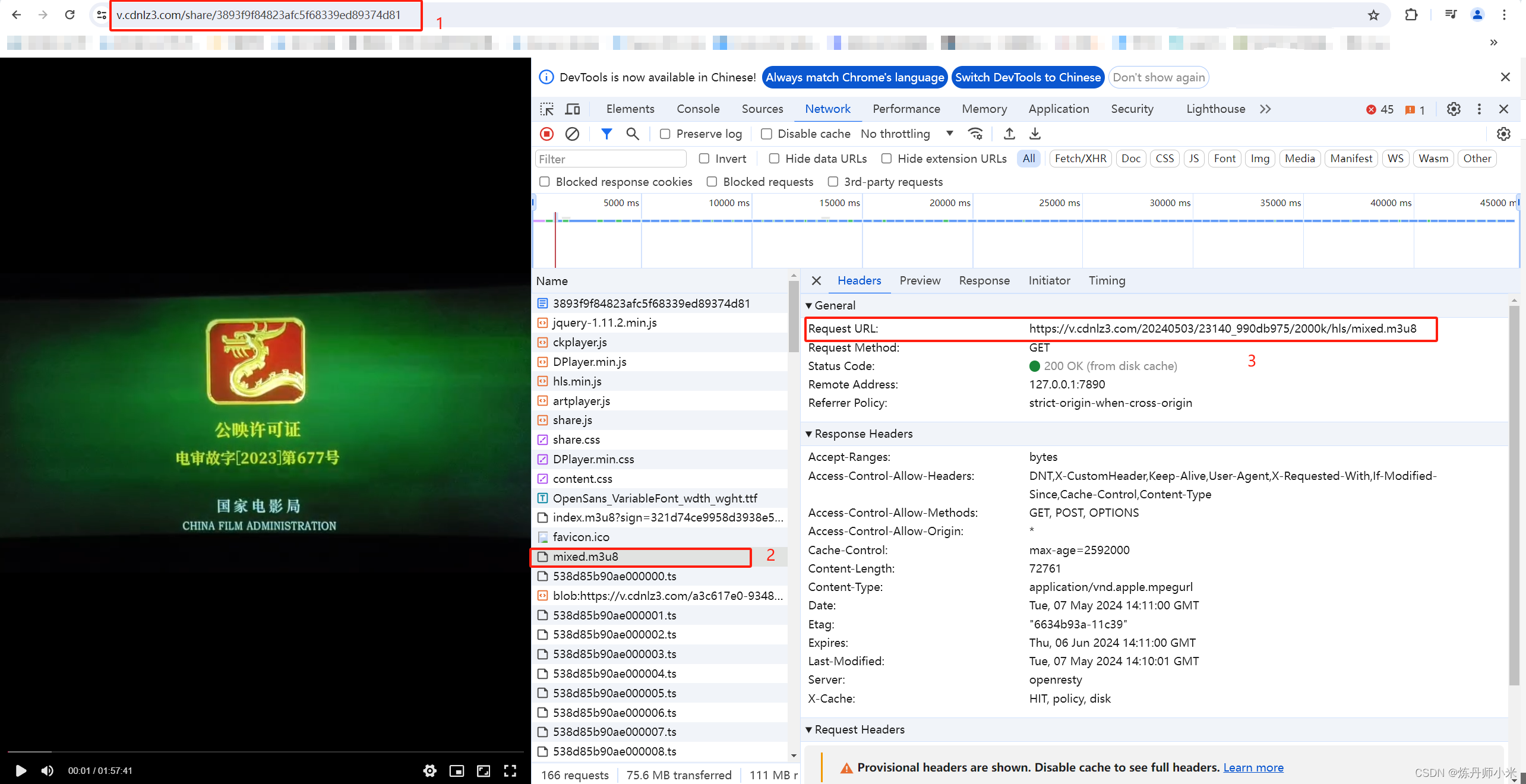
具体的,在打开了Network后,我们可以看到一个为m3u8的文件,点开这个m3u8,这个链接就是我们真实的要获取的视频信息的链接。如下图所示。可以看到,视频的链接(1)和和视频的请求链接(3)不是同一个,这是网站做了加密的处理,也是防止爬取的一种手段。但是这个其实很简单的可以寻找到规律。
我们以图中的链接为例https://v.cdnlz3.com/20240503/23140_990db975/2000k/hls/mixed.m3u8,我们打开多个爬取的不同的视频的下载链接,以同样的方式查看其m3u8链接会发现,会发现不同的视频的m3u8的链接其实都是很相似的,链接可以拆为三部分,https://v.cdnlz3.com/+20240503/23140_990db975/+ 2000k/hls/mixed.m3u8。
其中第一部分和爬取的视频的下载链接的v.cdnlz3.com/share/3893f9f84823afc5f68339ed89374d81的前面是一致的,这个信息我们已经有了,然后第三部分所有视频m3u8链接都是相同的,这个我们也有了。唯一需要寻找的信息就是第二部分的那段了。所以接下来我们就从源代码中寻找这部分的内容。
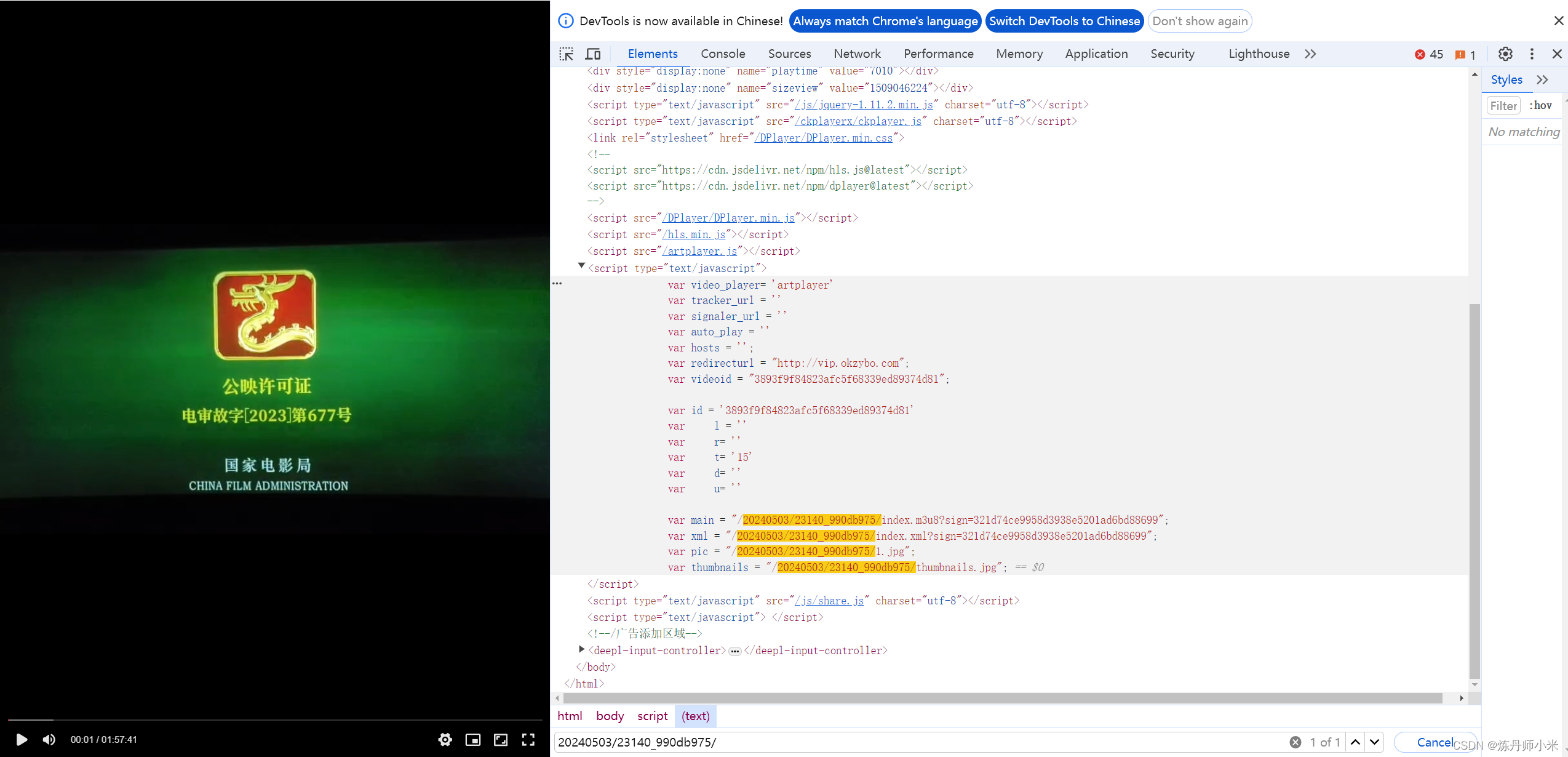
2.从网页源码中寻找视频的m3u8链接的第二部分内容
我们直接在F12中源码中搜索我们要找的内容20240503/23140_990db975/,直接就定位到了我们要找的位置了。由于这个内容也是js中渲染出来的,所以我们还是要使用requests_html来渲染网站从而获得视频的第二部分信息。然后将三部分拼起来就是视频的m3u8的链接https://v.cdnlz3.com/20240503/23140_990db975/2000k/hls/mixed.m3u8。
3.从视频的m3u8链接获取视频
我们执行一下代码:
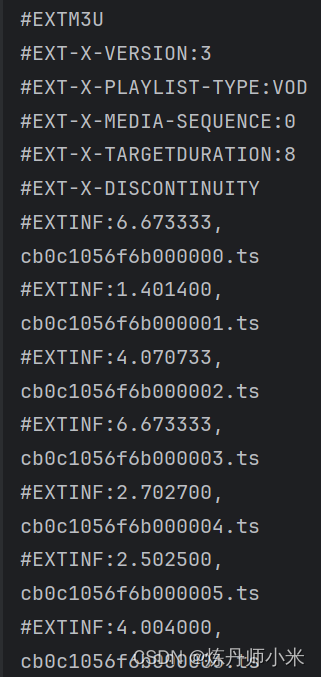
resp = requests.get(m3u8_url, headers)data = resp.textprint(data)
得到输出,输出的所有结尾为ts的名字就是我们要爬取的所有的ts视频,我们将上面的m3u8链接https://v.cdnlz3.com/20240503/23140_990db975/2000k/hls/mixed.m3u8的最后的mixed.m3u8换成爬取到的.ts就可以得到一个视频片段,然后按顺序依次获得所有的视频片段并拼接就可以得到完整的视频了。
二、完整的代码
from requests_html import HTMLSession
import requests_html
from bs4 import BeautifulSoup
import os
import requests
import randomif __name__ == '__main__':user_agent_list = [# 在这里可以写多个headers,然后随机选一个进行访问,这样可以防止频繁访问ip被封"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",]headers = {'user-agent': random.choice(user_agent_list),'Connection': 'close'}# 放视频下载链接的文件夹路径url_path = 'D:\\project\\爬虫\\爬取的视频'# 下载视频的保存路径save_path = 'D:\\project\\爬虫\\video'# 读取放视频下载链接的文件夹下的所有text文件filenames = os.listdir(url_path)for filename in filenames:print(filename)with open(os.path.join(url_path, filename), 'r') as file:# 读取text文件内容content = file.read()# try:session = HTMLSession()first_page = session.get(content)first_page.html.render(sleep=1) # 留出网页渲染的时间session.close()soup = BeautifulSoup(first_page.html.html, features="lxml") # 这里要用lxmlvideo_url = soup.findAll('script', attrs={'type': 'text/javascript'})video_url = video_url[2].stringlines = video_url.splitlines()key_url = lines[16][24:49]# print(key_url)content = content.split('/')# 爬取的有的视频的播放链接为空,所以进行一下异常测试try:head_url = content[0]+ '//' + content[2]except:print('链接无效')# print(head_url)m3u8_url = f'{head_url}{key_url}2000k/hls/mixed.m3u8'# print(m3u8_url)resp = requests.get(m3u8_url, headers)data = resp.text#print(data)url2 = f'{head_url}{key_url}2000k/hls/'index = 0for ts in data.splitlines():if ts[0] != '#':print(ts)index = index + 1url_add = url2 + tsprint(url_add)res = requests.get(url_add, headers=headers)data = res.contentwith open(os.path.join(save_path, filename+'.ts'), 'ab+') as f:f.write(data)f.flush()print("写入第{}文件成功".format(index))print("视频{}下载完毕!!!".format(filename))
这篇关于4.用python爬取保存在text中的格式为m3u8的视频的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




