本文主要是介绍SQL奇难怪状知识点分享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SQL执行顺序
select 语句的完整结构:
select 去重 要查询的字段
from表(注意:表和字段可以取别名)
xxxx(left/right/full) join 要连接的表 on 等值判断(顺序:先on再where)
where(具体的值/子查询,不包含聚合函数的过滤条件)
group by(通过哪个字段来分组)
having(过滤分组后的信息,条件和where一样,位置不同,包含聚合函数的过滤条件)
order by通过哪个字段排序
limit(分页)
SQL语句的执行顺序:
from -> on -> join -> where -> group by -> having -> select -> distinct -> order by -> limit
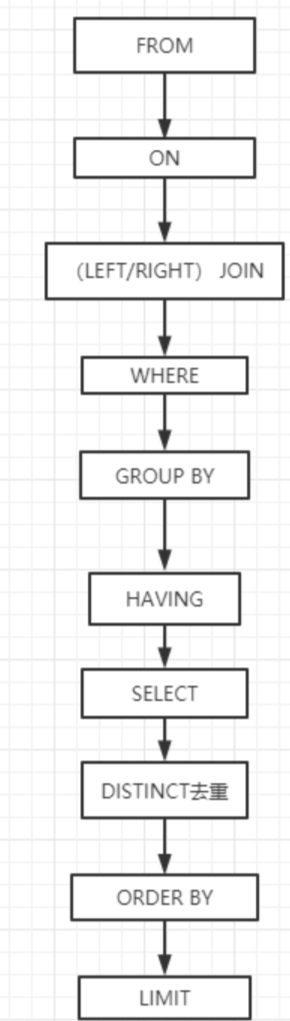
可以尝试记一下sql的执行顺序,对自己写sql以及sql调优有帮助,理解记忆也不是很难。
sql查询最重要的当然是从哪张表中查询,第一个就是from,和join后的表,当然在这之前可以确定一下,关联的字段那就是on,接下来是过滤的条件,就是where,后面紧接着就是当然就是group by和having了,然后就是返回查询结果,select选择返回指定的列,当然是distinct去重后的列,然后便是按照要求返回的数据是不是要排序啊order,返回指定的个数limit。你看,理解记忆一下,是不是还挺简单的。
group by分组题 行转列
create table tableA (Name varchar(10),Course varchar(10) ,Reslut int) ;
insert into tableA(Name , Course, Reslut) values('N1' , '语文' , 74) ;
insert into tableA(Name , Course , Reslut) values('N1' , '数学' , 83) ;
insert into tableA(Name , Course , Reslut) values('N1' , '物理' , 93) ;
insert into tableA(Name , Course , Reslut) values('N2' , '语文' , 74) ;
insert into tableA(Name , Course , Reslut) values('N2' , '数学' , 84) ;
insert into tableA(Name , Course , Reslut) values('N2' , '物理' , 94);
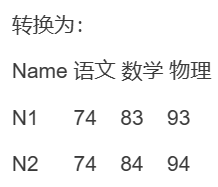
我的记录:
建表之后,表的结构为:
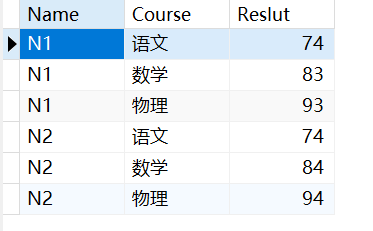
SELECTName,sum(if(course = '语文',reslut,0)) '语文',sum(if(course = '数学',reslut,0)) '数学',sum(if(course = '物理',reslut,0)) '物理'
FROMtablea
GROUP BY name;
这个题就是要注意sum和if函数的使用,其他没有什么难点,好像这道题是面试的重点题哦,好好记住它🥰
肯定是要用到group by函数,但是我group by函数不太熟悉,故记录一下此函数的学习记录。
聚合函数
SQL聚合函数是计算一组数据的集合并返回单个值。
除count以外,聚合函数忽略空值,如果count函数的应用对象是一个确定列名,并在该列存在空值,此时count仍会忽略空值。
因为聚合函数对一组值进行操作,所以它通常与select语句的group by子句一起使用,以计算每个分组提供信息的度量。
group by分组
分组是使用数据库时必须处理的最重要的任务之一。要将行分组,使用group by子句。
group by子句式select语句的可选子句,它根据指定列的匹配将行组合成组,每组返回一行。
在select子句中包含聚合函数不是强制的。但是,如果使用聚合函数,它将计算每个组的汇总值。
需要强调是的,在对行进行分组之前应用where子句,而在对行进行分组之后应用having子句。也就是说,where子句应用于行,而having子句应用于分组。
要对组进行排序,请在group by子句后添加order by子句。
group by子句中出现的列称为分组列,如果分组列包含null值,则所有null值都汇总到一个分组中,因为group by子句认为null值相等。
常见的聚合函数:sum、max、min、avg、count。
group by后面可以接多个列,表示按后面所有列相等分组。
在分组聚合的场景下,哪些字段可以出现在select子句中?
- 1.常量
- 2.聚合函数内的字段
- 3.参与分组的字段
group_concat函数
将group by产生的同一个分组中的值连接起来,返回一个字符串结构。
group_concat函数首先根据group by指定的列进行分组,将同一组的列显示出来,并用分隔符分割。
group_concat函数的语法
group_concat(distinct 字段名 order by 排序字段 asc/desc separator '分隔符')
使用distinct可以排除重复值;
separator是一个字符串值,默认为逗号;
列转行
SELECT lateral view explode()
from tablea
lateral view explode()是Hive SQL中的语法,属于UDF函数,explode()函数也被称为“炸裂函数”,顾名思义,就是将一列数据“炸裂”为多行数据,即有列转行的效果。
lateral view关键字用于扩展查询结构,使得能够在查询中使用函数或操作符处理数组或嵌套数据结构。
explode函数用于将数组或嵌套结构的数据展开成多行数据,每个元素或字段值对应一行。会在explode()函数中指定需要拆分的列名。
这段SQL语法的作用是将某列数据拆分成多行,方便后续的数据处理和分析。
连接ip人数最多

SELECTip,count(ip) 'ip连接人数最多'
from ip
GROUP BY ip
ORDER BY COUNT(ip) DEsqlUserSC
LIMIT 1
limit和offset用法
limit
limit 开始值,结束值
select * from stu limit m,n;
m:开始值 从第m+1行开始;
n:结束值 供展示n条数据
不能在limit中使用变量,例题《第N高的薪水》
在SQL中,limit子句用于限制查询结构的行数。然后它不允许直接使用变量作为行数的参数。
这是因为在查询计划生成的时候,数据库需要确定查询的结果集大小,以便进行优化和执行。因此,limit子句只能接受常量值,不能接受变量。
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
declare m int;
set m = N-1;RETURN (select(select distinct salaryfromEmployeeorder by salary desclimit m,1)as getNthHighestSalary
);
END
offset
offset n 去掉几个值
就是跳过n个数据,取第n+1值
conclusion
数据中的数据,计算是从0开始的。
第N高的薪水


CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGINdeclare m int;set m = N - 1;
RETURN (selectdistinct salaryfrom Employeeorder by salary desclimit m,1
);
END
limit函数不能直接用变量,故需要自己定义常量接收,定义函数为:
declare m int;
set m = N;
先用declare关键字定义,再用set设置。
这个题目对我来说本身其实不难,难的其实是我对sql创建函数的陌生,多看看这道题,多写写牢记它🤣
group by+having 或group by + 临时表

group by + 临时表
select email
from (select email,count(email) as numfrom persongroup by email
)as sta
where num>1;
很简单哇,临时表,就是括号as 表名,select查询出来时一张表,在这张表直接查询就行。
group by+having
selectEmail
FROMperson
group by Email
having count(Email)>1;
having是用于group by之后对数据进行筛选。
删除重复邮件

先根据email分组,筛选出每个邮件的最小id;
由于需要的是具体id值来参与条件筛选,所以要筛选出具体id;
有了筛选条件就可以进行删除了。
delete
from Person
where Person.id not in (select e.i from (select min(id) as i from Person group by email) as e
);
这道题最关键就是使用group by分组,然后用聚合函数min去找到最小的id。
测试的时候,我觉得可以使用如下代码,但是在报错了代码:1093 - you can’t specify target table
delete from person
where person.id not in
(select min(id) as id from Person group by email
)

原来是不能同时既在一张表select,又去update到这张表。所以需要增加一张临时表过渡一下。
上升的温度

select w1.id Id
from Weather w1
join Weather w2
on datediff(w1.recordDate ,w2.recordDate ) = 1
where w1.Temperature > w2.Temperature
datediff函数用于返回两个日期之间的边界数差异。这个函数可以计算两个日期之间的年、月、日、小时、分钟、秒或周数差异。
datediff(datepart,startdate,enddate)
datepart是指定要返回日期部分的参数,比如year、month、day、hour、minute、second、week等
startdate和enddate是要进行差异计算的日期,开始日期和结束日期。
IF表达式 和 case when条件表达式
IF(判断条件,结果1,结果2)
判断条件为true,则返回结果1;否则返回结果2。
if一般适合用于判断两值分类。
case when:
case
when 列名 = ‘A’ then ‘A1',
when 列名 = ‘B’ then ‘B1’,
when 列名 = ‘C’ then ‘C1'
else 'D1
end
then后面的值与else后面的值类型应一致。
也可以把列名全部提前到case后面。
case when 一般适用于两值即两值以上分类。
if和case可以作为最后生成的列返回。
事务
-- 开始事务
START TRANSACTION;-- 执行一些SQL语句
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2;-- 判断是否要提交还是回滚
IF (条件) THENCOMMIT; -- 提交事务
ELSEROLLBACK; -- 回滚事务
END IF;1.开启事务:使用begin或者start transaction命令来开始一个事务。
2:执行SQL语句:
3.判断是否提交或回滚:
根据业务逻辑判断是否要提交或回滚事务。
使用IF条件来判断,如果满足条件则执行commit提交事务,否则执行rollback回滚事务。
4.结束事务:
使用commit命令来提交事务,将所有的修改永久保存到数据库;
使用rollback命令来回滚事务,撤销自上次提交以来所做的所有更改。因为事务是多条sql语句同时执行,要是在事务运行过程中发现了某种故障,事务不能继续执行,系统将事务中对数据库所有已完成的操作全部撤销,滚回到书屋开始时的状态。
窗口函数
它对查询结果的一个窗口(也称为分区)执行计算并返回结果。
窗口函数,也叫OLAP函数(联机分析处理),可以对数据库数据进行实时分析处理,它的基本语法如下:
<窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名>)
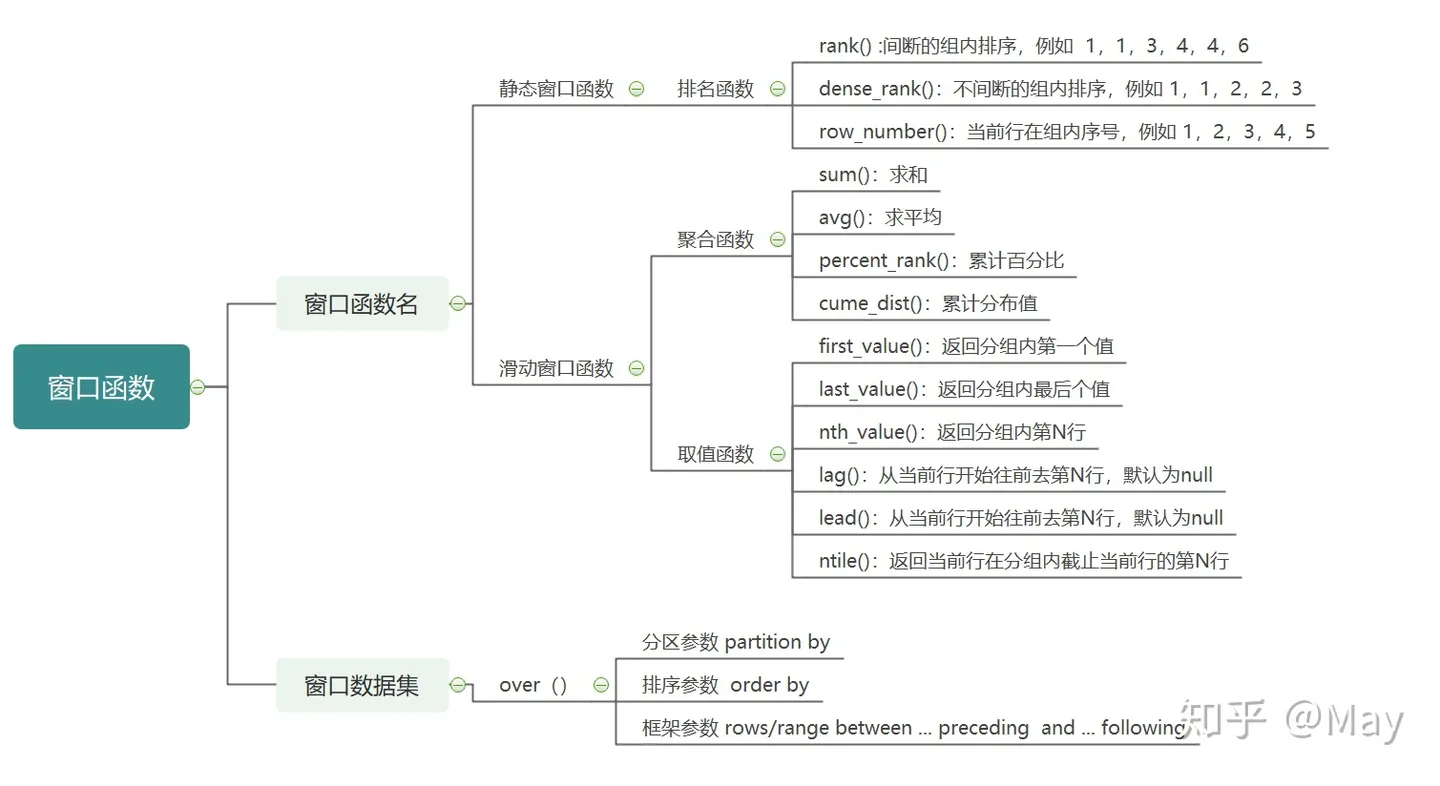
lag():查询当前行向上偏移n行对应的结果(过去)
lead():查询当前行向下偏移n行对应的结果(未来)
窗口函数原则上只能写在**select**子句中。
窗口函数的名称来源于:over子句中的partition by分组,这里的窗口表示数据的范围。总之,窗口函数具备分组和排序功能,不减少原表的行数。
窗口函数简单理解就是rank()、dense_rank()用来获取排名,可以用partition by分组,order by对某一字段的数据进行排名。
当然,也可以省略掉partition by语句,此时表示不进行分区,对目标表内所有的数据根据某列进行排序(不过此时,窗口函数就失去了其功能)。
join和union的区别
- join(连接查询):是将两个查询(或表),以‘两两横同对接’的方式。
所得到的所有行,即表示表中的某行,跟另一个表中的某行。
进行‘横向对接’,得到一个新行。
- union(联合查询):指将2个或2个以上的字段数量相同的查询结构,‘纵向堆叠’后合并为一个结果。
union操作符用于合并两个或多个select语句的结果集
union操作符只能连接字段与字段,而不能连接字段与表或者表与表,哪怕字段以及字段名称、格式都一样也不行。因为union操作符前后是不能带有括号的,因为带有括号的话,sql就容易判定这是一个子查询表,连接会报错。
union all的效率更高,不用去判断是否存在重复值。
部门工资最高的员工

select d.name Department,e.name Employee,salary Salary
from Employee e
join Department d
on e.departmentId = d.id
where (d.id,salary) in (select departmentId,max(salary)from Employee group by departmentId
)
聚合函数中的max和min只会返回1行,不会将所有的最大值都返回回来。
这道官方题解给出的是,直接找到每个部门最大薪资作为子查询,然后再在总表中找到某个部门与该薪资对应的人,就可以返回所有最高薪资的员工。
select Department.name Department,r.name Employee,salary Salary
from (select name,salary,departmentId,dense_rank() over (partition by departmentId order by salary desc) 'rank'
from Employee e
)r
join Department
on r.departmentId = Department.id and r.rank=1
也可以用dense_rank()窗口函数实现,最高薪资,就是薪水排名第一,只要将所有薪水排名第一的雇员输出即可。窗口函数是将每一行的数据划分一个窗口,然后对窗口范围内的数据进行计算,最后将计算结果返回给该行数据,这是一个新生成的字段,不能用于筛选,需要作为表返回后,对表进行筛选。
这篇关于SQL奇难怪状知识点分享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







