本文主要是介绍FastText 算法原理及使用方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1. 前言
- 2. 模型架构
- 2.1 Hierarchical Softmax
- 2.2 n-gram 特征
- 3. 训练及评估
- 4. 使用
- 5. 参考
1. 前言
FastText 是一个由 Facebook AI Research 在2016年开源的文本分类器,它的设计旨在保持高分类准确度的同时,显著提升训练和预测的速度。
论文:《Enriching Word Vectors with Subword Information》
github 源码:FastText
常见的文本分类算法:《常用的文本分类算法概览》
2. 模型架构
FastText 的模型架构与 word2vec 中的连续词袋模型(CBOW)相似,但其任务是分类而不是生成词向量。它包括以下组成部分:
(1)输入层:接收文本数据,通常是将文本转化为词序列或者词袋表示。
(2)隐藏层:对输入数据进行变换,通常涉及词向量的查找或计算。
(3)输出层:使用层次 softmax 或其他技术来预测文本所属的类别
如下图:
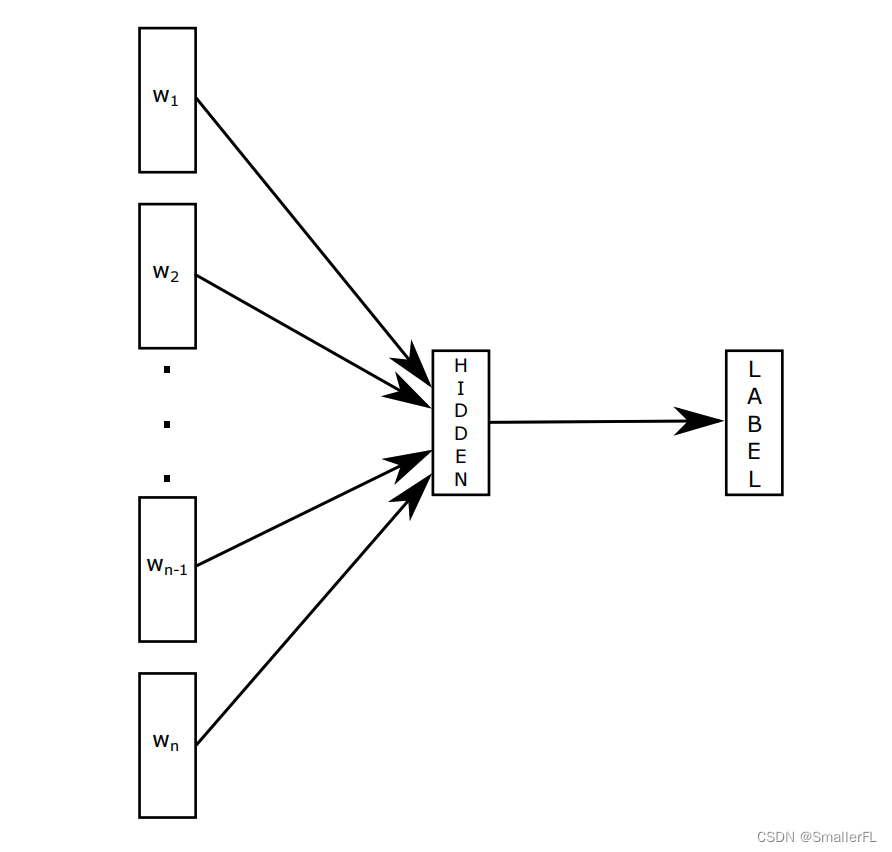
其中,上图仅仅表示有1个隐藏层的情况, w 1 , . . . , w n w_1,...,w_n w1,...,wn 表示句子中的每一个词的词嵌入向量。
2.1 Hierarchical Softmax
当目标类别数量很大时,计算线性分类器花费的计算成本高昂。为了提高运行效率,FastText 使用了基于 Huffman 树的层次化 softmax。在训练时,计算复杂度降低到 O(d log2(K)),其中 d 是隐藏层的维度,K 是目标类别的数量。
Hierarchical Softmax 讲解参考这里
2.2 n-gram 特征
词袋模型对词序不变,但考虑词序可以提高性能。FastText 使用 n-gram 作为额外特征来捕获局部词序信息,这样做既高效又能达到与显式使用词序的方法相当的性能。
3. 训练及评估
根据论文内容:
训练:FastText 的训练类似于 word2vec,使用随机梯度下降(SGD)和反向传播,学习率线性衰减。模型异步在多个 CPU 上进行训练。
模型性能:FastText 在多个数据集上的性能与基于深度学习的方法相当,同时在训练和评估上快几个数量级。
效率:FastText 能够在标准多核 CPU 上,在不到十分钟的时间内训练超过十亿个单词,并且在不到一分钟内对五十万个句子进行分类。
实验:
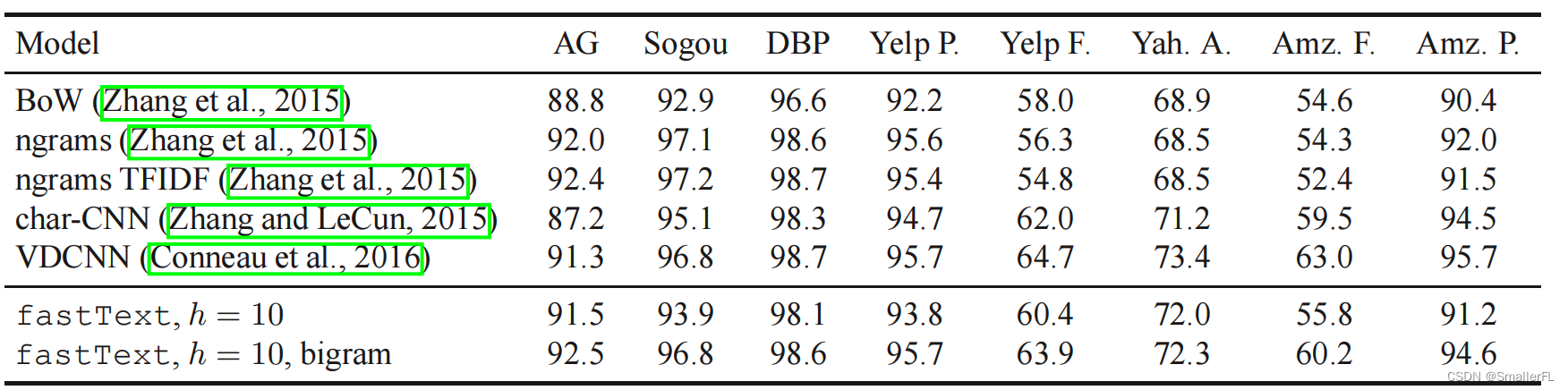
4. 使用
python 安装 fasttext
pip install fasttext
python 训练
def train(train_dataset_path: str, test_dataset_path: str, model_path: str):model = fasttext.train_supervised(train_dataset_path)model.save_model(model_path)print(model.test(test_dataset_path))
train_supervised() 是一个用于训练监督学习模型的函数,通常用于文本分类任务,参数:
input # training file path (required)lr # learning rate [0.1]dim # size of word vectors [100]ws # size of the context window [5]epoch # number of epochs [5]minCount # minimal number of word occurences [1]minCountLabel # minimal number of label occurences [1]minn # min length of char ngram [0]maxn # max length of char ngram [0]neg # number of negatives sampled [5]wordNgrams # max length of word ngram [1]loss # loss function {ns, hs, softmax, ova} [softmax]bucket # number of buckets [2000000]thread # number of threads [number of cpus]lrUpdateRate # change the rate of updates for the learning rate [100]t # sampling threshold [0.0001]label # label prefix ['__label__']verbose # verbose [2]pretrainedVectors # pretrained word vectors (.vec file) for supervised learning []
下面介绍主要参数:
-
input: 输入数据文件的路径或者文件对象。输入文件应该是一个包含训练样本的文本文件,每一行代表一个样本,样本由文本内容和标签组成,二者之间用制表符或空格分隔。
-
lr (float, optional): 学习率(learning rate),用于控制模型参数更新的步长,默认为 0.1。
-
epoch (int, optional): 迭代次数,即训练过程中整个训练数据集被遍历的次数,默认为 5。
-
wordNgrams (int, optional): 用于构建 n-gram 特征的窗口大小,通常用于捕捉词序信息,默认为 1,表示只考虑单个词的特征。
-
dim (int, optional): 词向量的维度,默认为 100。较高的维度可能会导致更丰富的特征表示,但也会增加模型的复杂度和训练时间。
-
loss (str, optional): 损失函数,用于优化模型参数。可选值包括 “hs”(hierarchical softmax)和 “ns”(negative sampling),默认为 “softmax”。
-
thread (int, optional): 用于并行训练的线程数,默认为 12。增加线程数可以加快训练速度,但也会增加计算资源的消耗。
-
label_prefix (str, optional): 标签的前缀,默认为 __label__。用于标识样本的类别。
-
pretrained_vectors (str, optional): 预训练的词向量文件的路径,用于初始化模型参数。如果提供了预训练的词向量,则模型会在训练开始时加载这些向量,并根据需要微调。
-
verbose (int, optional): 控制训练过程中的输出信息的详细程度。默认为 2,表示输出训练进度和性能指标。
训练的数据格式:
__label__0 第一种是在上下文中选定多个词汇作为输入,选定一个单词作为输出
__label__1 将每个词的one-hot编码与哈夫曼编码计算出来。
其中 __label__ 为前缀,可以在参数 label_prefix 修改,0、1是所属的类别。
5. 参考
《Enriching Word Vectors with Subword Information》
欢迎关注本人,我是喜欢搞事的程序猿;一起进步,一起学习;
欢迎关注知乎/CSDN:SmallerFL
也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤
这篇关于FastText 算法原理及使用方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






