本文主要是介绍探索大语言模型在信息提取中的应用与前景,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着人工智能技术的快速发展,大语言模型(LLMs)在自然语言处理(NLP)领域取得了显著的进展。特别是在信息提取(IE)任务中,LLMs展现出了前所未有的潜力和优势。信息提取是从非结构化文本中抽取结构化信息(如实体、关系和事件)的过程,对于知识图谱构建、自动问答系统等应用至关重要。然而,传统的IE方法面临领域依赖性强、泛化能力弱等挑战。
LLMs,如GPT-3和LLaMA,因其在文本理解和生成上的卓越表现,为解决上述挑战提供了新的可能性。这些模型能够捕捉文本间的复杂关系,通过生成而非简单的抽取来构建结构化信息,从而在多个IE子任务中展现出了强大的能力。
最新的研究工作表明,LLMs可以通过不同的学习范式(如监督微调、少样本学习、零样本学习)来适应IE任务。这些方法不仅提高了模型在标准IE设置下的性能,而且在开放IE环境中也显示出了优越的泛化能力。

1. 超级微调(Supervised Fine-Tuning, SFT)
在监督微调中,LLMs在特定任务上进行进一步训练,以学习任务相关的特定模式。这种方法通常需要一定量的任务相关标注数据。通过SFT,模型能够更好地捕捉数据中的结构化信息,从而在标准IE设置下实现高性能。
2. 少样本学习(Few-Shot Learning)
少样本学习是指模型使用非常有限的标注样本进行学习。LLMs由于其庞大的参数量和丰富的预训练知识,能够在只有少量标注数据的情况下快速适应新任务。在IE任务中,少样本学习允许模型在新领域或新任务上快速启动,即使只有少量的标注信息。
3. 零样本学习(Zero-Shot Learning)
零样本学习是LLMs最具挑战性的应用之一,它要求模型在没有任何标注样本的情况下执行任务。LLMs的零样本学习能力主要来自于其在预训练阶段积累的大量知识和语言理解能力。在IE任务中,这意味着模型可以识别和生成从未见过的结构化信息,这对于开放IE(Open IE)尤其有价值。
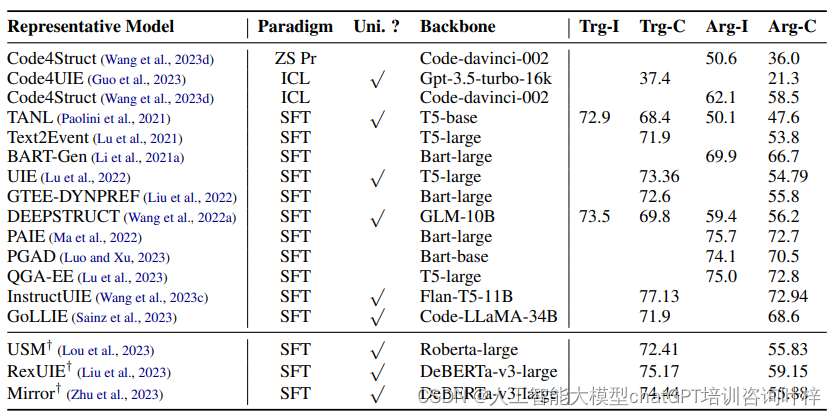
4. 开放IE环境中的泛化能力
开放IE任务要求模型能够识别文本中所有可能的关系,而不是仅限于预定义的关系集。这需要模型具有高度的泛化能力。LLMs在开放IE中的研究显示,它们可以通过生成式方法来识别和构建新的关系,而不是仅仅识别已知的关系类型。
5. 提升性能的策略
为了提高LLMs在IE任务中的表现,研究人员采取了多种策略,包括:
- 指令提示(Instruction Prompting):通过给模型提供明确的指令来引导其完成特定的IE任务。
- 上下文学习(In-Context Learning):利用模型从上下文中学习的能力,通过提供与任务相关的示例来增强学习。
- 结构化输出(Structured Output):引导模型生成结构化的数据格式,如JSON或表格,以便于后续处理。
特定领域的信息提取面临着独特的挑战,如专业术语的识别、领域特定语境的理解等。大型语言模型(LLMs)在这些领域的应用,因其强大的语言处理能力和泛化能力,已经取得了显著的进展:
1. 多模态信息提取
多模态数据包含文本、图像、声音等多种类型的信息。LLMs结合视觉语言模型(如VL-BERT)或其他多模态架构,能够处理和关联来自不同模态的信息。例如,在社交媒体帖子中,模型可以识别文本内容中的情感,同时分析相关联的图像内容,以提取更全面的信息。
2. 医疗领域的信息提取
医疗文本通常包含复杂的医学术语和临床表达,对非专业人员来说难以理解。LLMs通过预训练和微调,能够识别和解释医疗领域的专业术语,从而在临床文本挖掘中识别重要的医疗信息,如症状、诊断、治疗方案等。此外,合成数据的生成可以帮助模型在保护患者隐私的同时进行训练和增强性能。
3. 科学文本的信息提取
科学文献包含丰富的专业信息和复杂的逻辑关系。LLMs能够理解和抽取科学文献中的关键概念、实验结果和引用关系。通过生成式方法,LLMs还能够自动生成科学摘要或解释复杂的科学理论,这对于科学研究和教育领域非常有价值。
4. 法律和金融文档的信息提取
法律和金融文档具有严格的格式和专业术语。LLMs可以被训练来识别合同、法规和财务报表中的关键条款和实体,从而自动化合规性检查、风险评估和信息披露等任务。
5. 数据增强和隐私保护
在医疗和金融等对隐私敏感的领域,数据增强技术可以帮助生成合成的训练数据,以提高模型性能,同时避免使用真实患者的敏感信息。LLMs在生成合成数据方面展现出了巨大的潜力,这对于训练强大的模型同时遵守隐私法规至关重要。
6. 模型微调和领域适应
为了在特定领域中实现最佳性能,LLMs通常需要进行额外的微调。这可以通过在领域特定的数据集上进一步训练模型来完成,从而使模型更好地适应该领域的语言风格和术语。
尽管LLMs在命名实体识别(NER)、关系抽取(RE)和事件抽取(EE)等子任务上取得了显著进展,但对这些模型的全面评估仍面临挑战。研究人员通过设计细致的评估策略和识别错误类型,对LLMs的能力进行了深入分析。
评估LLMs的准确性通常涉及使用标准的IE评估指标,如F1分数、精确度和召回率。这些指标能够量化模型在特定数据集上的性能。然而,仅仅依赖这些指标可能无法全面反映模型的能力,因为它们可能掩盖了模型在特定类型的错误上的倾向。
为了更深入地理解LLMs的性能,研究人员采用了多种评估策略。例如,软匹配(soft-matching)策略允许评估时在一定的编辑距离内考虑实体边界的微小变化,这有助于更精确地衡量模型的实体识别能力。研究人员还关注模型在未见过的实体类型或关系类型上的表现,以评估其泛化能力。
错误分析是评估过程中的另一个关键部分。通过识别和分类模型犯下的错误,研究人员可以洞察模型的弱点。常见的错误类型包括误识别(将非实体识别为实体)、漏识别(未能识别真实实体)、错误分类(将实体或关系错误分类)和错误边界(实体边界划分不准确)。这些错误的分析有助于揭示模型在理解语言现象、处理歧义或泛化到新领域时的不足。
评估LLMs时还需考虑其在不同领域的适用性。不同领域的文本可能包含特有的术语和表达方式,模型在这些领域的性能可能会有所不同。因此,研究人员在多个领域的数据集上评估LLMs,以确保其具有广泛的适用性。
评估LLMs的鲁棒性也是一个重要方面。这包括测试模型对输入噪声、异常值和对抗性样本的敏感性。鲁棒性分析有助于确保模型在面对现实世界中的不确定性和变化时能够保持稳定的性能。 综上所述,对LLMs在IE任务中的评估与分析是一个全面且复杂的过程。它不仅包括传统的性能指标,还涉及对模型错误的深入分析、跨领域的适用性测试和鲁棒性考量。通过这种全面的评估框架,研究人员可以更好地理解LLMs的潜力和局限性,为未来的研究和模型改进提供指导。
论文链接:https://arxiv.org/pdf/2312.17617.pdf
这篇关于探索大语言模型在信息提取中的应用与前景的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





