本文主要是介绍Python基础详解二,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一,函数
函数是组织好的,可重复使用的,用来实现某个功能的代码段
def myMethod(data):print("数据长度为",len(data))myMethod("dsdsdsds")![]()
函数的定义:
def 函数名(传入参数):函数体return 返回值def myMethod(data):print("数据长度为",len(data))return len(data)len =myMethod("dsdsdsds")
print(len)
如果函数没有返回值,则默认返回None
None是空的,无实际意义的意思
None值等同于 False
二,局部变量和全局变量
局部变量是定义在函数体内部的变量,即只在函数体内部生效
def test():numa =100print(numa)
test()print(numa) 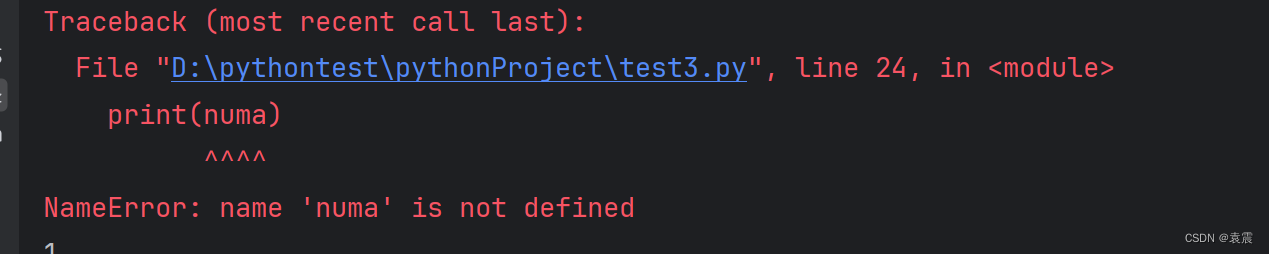
全局变量是在函数体内和体外都能生效的变量
numa =100
def test():print(numa)
test()print(numa)使用global关键字,可以在函数内部声明变量为全局变量
numa = 100
def test():global numanuma = 200print(numa)
test()print(numa)
三,数据容器
3.1 列表
list1 =["袁震1",2,"袁震3",4,"袁震5",6]for i in list1:print(i)
列表中可以存储不同类型的数据
列表的嵌套:
list1 =["袁震1",2,"袁震3",4,"袁震5",6]
list2 =[list1,"2"]
print(list2[0][4])
列表的倒序取出
list1 =["袁震1",2,"袁震3",4,"袁震5",6]
list2 =[list1,"2"]
print(list2[0][4])print(list1[-2])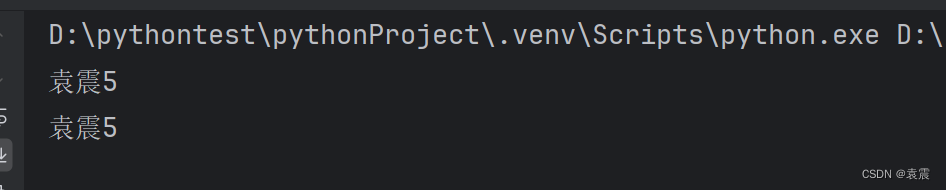
方法和函数的区别:方法是定义在class内部的
查找某元素下标:
list1 =["袁震1",2,"袁震3",4,"袁震5",6]print(list1.index("袁震1"))0
修改特定位置的元素值
list1 =["袁震1",2,"袁震3",4,"袁震5",6]
list1[0] ="袁震"
print(list1)['袁震', 2, '袁震3', 4, '袁震5', 6]
插入元素:
list1 =["袁震1",2,"袁震3",4,"袁震5",6]
list1[0] ="袁震"
list1.insert(1,"袁震2")
print(list1)['袁震', '袁震2', 2, '袁震3', 4, '袁震5', 6]
追加元素:
list1 =["袁震1",2,"袁震3",4,"袁震5",6]
list1.append("袁震6")
print(list1)['袁震1', 2, '袁震3', 4, '袁震5', 6, '袁震6']
追加一批元素:
list1 =["袁震1",2,"袁震3",4,"袁震5",6]
list2 =[1,2,3,4,5,6]
list1.extend(list2)
print(list1)['袁震1', 2, '袁震3', 4, '袁震5', 6, 1, 2, 3, 4, 5, 6]
删除:
list1 =["袁震1",2,"袁震3",4,"袁震5",6]
del list1[0]
print(list1)
[2, '袁震3', 4, '袁震5', 6]
删除2:
list1 =["袁震1",2,"袁震3",4,"袁震5",6]
list1.pop(0)
print(list1)[2, '袁震3', 4, '袁震5', 6]
删除指定内容元素:
list1 =["袁震1",2,"袁震3",4,"袁震5",6]
list1.remove("袁震1")
print(list1)[2, '袁震3', 4, '袁震5', 6]
清空列表:
list1 =["袁震1",2,"袁震3",4,"袁震5",6]
list1.clear()
print(list1)[]
统计某元素在列表内的数量
list1 =["袁震1",2,"袁震1",4,"袁震1",6]
count =list1.count("袁震1")
print(count)3
统计列表内有多少元素
list1 =["袁震1",2,"袁震1",4,"袁震1",6]
count = len(list1)
print(count)6
列表的遍历while:
def method1(myList:list):index =0while index<len(myList):element =myList[index]print(element)index +=1list1 =["袁震1",2,"袁震1",4,"袁震1",6]
method1(list1)袁震1
2
袁震1
4
袁震1
6
列表的遍历for:
def method2(myList:list):for element in myList:print(element)list1 =["袁震1",2,"袁震1",4,"袁震1",6]
method2(list1)袁震1
2
袁震1
4
袁震1
6
3.2 元组
元组同列表一样,都i是可以封装多个,不同类型的元素在内,但是,元组一旦定义完成,就不可修改。
元组的定义:
(元素,元素,元素)t1=(1,2,3,4,"5",6)
t2=()
t3=tuple()
print(f"t1:{t1} t2:{t2} t3:{t3}")t1:(1, 2, 3, 4, '5', 6) t2:() t3:()
如果定义的元组只有一个元素时,后面需要添加,
查找某个元素:
t1=(1,2,3,4,"5",6)
print(t1.index(2))1
统计元组元素数量:
t1=(1,2,3,4,"5",6)
print(len(t1))
6
统计某个 元素的数量:
t1=(1,1,1,1,"5",6)
print(t1.count(1))4
不可修改元组内容,但是可以修改元组内部list的内容
3.3 字符串
取字符串某个元素
myStr ="yuan zhen"
print(myStr[2])a
字符串不支持修改
index:
myStr ="yuan zhen"
print(myStr.index("u"))1
replace:
myStr ="yuan zhen"
print(myStr.replace(" "," and "))yuan and zhen
split:
myStr ="yuan zhen"
print(myStr.split(" "))['yuan', 'zhen']
strip: 去除前后空格
myStr =" yuan zhen "
print(myStr.strip())yuan zhen
myStr ="12yuan zhen21"
print(myStr.strip("12"))yuan zhen
count:
myStr ="12yuan zhen21"
print(myStr.count("1"))2
len:
myStr ="12yuan zhen21"
print(len(myStr))13
3.4 序列
序列是指内容连续,有序,可使用下标索引的一类数据容器
列表,元组,字符串均可视为序列
序列的切片
list=[1,2,3,4,5,6]
print(list[1:4:1])
print(list[:])
print(list[::2])
print(list[::-1])
print(list[3:1:-1])[2, 3, 4]
[1, 2, 3, 4, 5, 6]
[1, 3, 5]
[6, 5, 4, 3, 2, 1]
[4, 3]
3.5 集合
集合不支持元素重复,无序
集合的定义:
{元素,元素,元素,元素}变量名称=set()mySet ={1,2,3,2,3,4,6,443,313,1,3}
print(mySet){1, 2, 3, 4, 6, 313, 443}
添加元素:
mySet ={1,2,3,2,3,4,6,443,313,1,3}
mySet.add("袁震")
print(mySet){1, 2, 3, 4, 6, 313, 443, '袁震'}
移除元素:
mySet ={1,2,3,2,3,4,6,443,313,1,3}
mySet.remove(1)
print(mySet)随机取出元素:
mySet ={1,2,3,2,3,4,6,443,313,1,3}print(mySet.pop())
1
清空集合
mySet ={1,2,3,2,3,4,6,443,313,1,3}print(mySet.clear())None
取两个集合的差集:
mySet ={1,2,3}
mySet2={1,5,6}print(mySet.difference(mySet2)){2, 3}
合并:
mySet ={1,2,3}
mySet2={1,2,5,6}
result =mySet.union(mySet2)
print(result){1, 2, 3, 5, 6}
3.6 字典
字典的定义:
{key:value,key:value,key:value,key:value}mydict=dict()myDict ={"袁震":100,"张三":0}
print(myDict){'袁震': 100, '张三': 0}
通过key获取value:
myDict ={"袁震":100,"张三":0}
print(myDict["袁震"])100
新增元素:
myDict ={"袁震":100,"张三":0}
myDict["李四"]=90
print(myDict){'袁震': 100, '张三': 0, '李四': 90}
删除元素:
myDict ={"袁震":100,"张三":0}
myDict.pop("张三")
print(myDict)
{'袁震': 100}
清空元素:
myDict ={"袁震":100,"张三":0}
myDict.clear()
print(myDict){}
获取全部key:
myDict ={"袁震":100,"张三":0}
print(myDict.keys())dict_keys(['袁震', '张三'])
遍历:
myDict ={"袁震":100,"张三":0}
keys=myDict.keys()
print(myDict.keys())
for key in keys:print(myDict[key])获取最大元素:
print(max(myDict))获取最小元素:
print(min(myDict))转列表:
print(list(myDict))['袁震', '张三']
转元组:
print(tuple(myDict))转字符串:
print(str(myDict))转集合:
print(set(myDict))排序:排序结果都变为了列表
mySet ={1,2,3}
mySet2={1,2,5,6}result =mySet.union(mySet2)
print(sorted(result))[1, 2, 3, 5, 6]
反向排序:
mySet ={1,2,3}
mySet2={1,2,5,6}result =mySet.union(mySet2)
print(sorted(result,reverse=True))[6, 5, 3, 2, 1]
这篇关于Python基础详解二的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





