本文主要是介绍4.2、从RDBMS向Neo4j导数据【专题四:数据处理】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、目标
介绍将从PostgreSQL(RDBMS)导出的数据导入Neo4j(GraphDB),即将关系数据库模式建模,使之形成图。
预备知识:熟悉图模型并安装neo4j服务
2、导RDBMS数据到Neo4j
2.1、RDBMS数据集
用到的数据集是NorthWind dataset(点击下载),该数据库的E-R图如下:
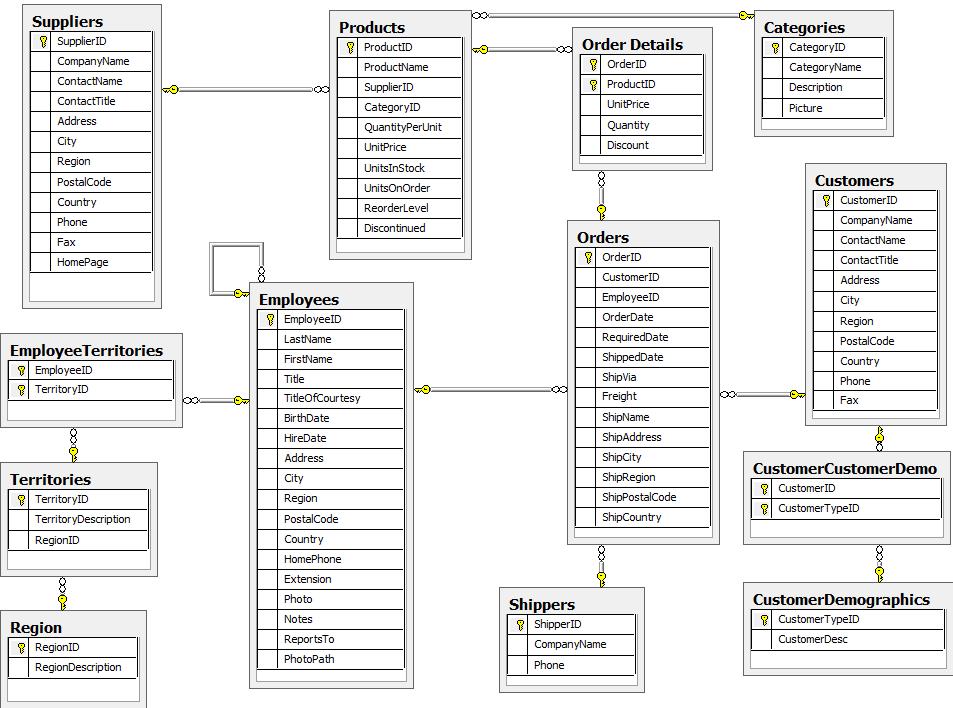
2.2、构建图模型
当将E-R模型转换成图模型时,需要遵守如下规则:
(1)一行仅表示一个节点(node)
(2)一个表名对应一个Label名
NorthWind dataset表示成图模型的一个局部示意图如下:

#图模型和E-R模型的区别:
(1)前者的节点和边没有空值,而后者的字段存在空值;(2)前者描述“关系”(通过边)更加详尽,而且边可以添加元数据;(3)前者对于描述网络关系更加标准化。
2.3、将数据导出成CSV
通过copy和export将PostgreSQL中的部分表导出:
COPY (SELECT * FROM customers) TO '/tmp/customers.csv' WITH CSV header;COPY (SELECT * FROM suppliers) TO '/tmp/suppliers.csv' WITH CSV header;COPY (SELECT * FROM products) TO '/tmp/products.csv' WITH CSV header;COPY (SELECT * FROM employees) TO '/tmp/employees.csv' WITH CSV header;COPY (SELECT * FROM categories) TO '/tmp/categories.csv' WITH CSV header;COPY (SELECT * FROM ordersLEFT OUTER JOIN order_details ON order_details.OrderID = orders.OrderID) TO '/tmp/orders.csv' WITH CSV header;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2.4、基于Cypher导入数据
通过Cypher的LOAD CSV实现数据导入
(1)创建节点
import_csv.cypher如下:
// Create customers
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:customers.csv" AS row
CREATE (:Customer {companyName: row.CompanyName, customerID: row.CustomerID, fax: row.Fax, phone: row.Phone});// Create products
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:products.csv" AS row
CREATE (:Product {productName: row.ProductName, productID: row.ProductID, unitPrice: toFloat(row.UnitPrice)});// Create suppliers
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:suppliers.csv" AS row
CREATE (:Supplier {companyName: row.CompanyName, supplierID: row.SupplierID});// Create employees
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:employees.csv" AS row
CREATE (:Employee {employeeID:row.EmployeeID, firstName: row.FirstName, lastName: row.LastName, title: row.Title});// Create categories
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:categories.csv" AS row
CREATE (:Category {categoryID: row.CategoryID, categoryName: row.CategoryName, description: row.Description});USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:orders.csv" AS row
MERGE (order:Order {orderID: row.OrderID}) ON CREATE SET order.shipName = row.ShipName;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
(2)创建索引
对刚创建的节点建立索引,以便在下一步创建边关系的时候能快速检索到各点。
CREATE INDEX ON :Product(productID);CREATE INDEX ON :Product(productName);CREATE INDEX ON :Category(categoryID);CREATE INDEX ON :Employee(employeeID);CREATE INDEX ON :Supplier(supplierID);CREATE INDEX ON :Customer(customerID);CREATE INDEX ON :Customer(customerName);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(3)创建边关系
首先创建products和employees的边关系。
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:orders.csv" AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (product:Product {productID: row.ProductID})
MERGE (order)-[pu:PRODUCT]->(product)
ON CREATE SET pu.unitPrice = toFloat(row.UnitPrice), pu.quantity = toFloat(row.Quantity);USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:orders.csv" AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (employee:Employee {employeeID: row.EmployeeID})
MERGE (employee)-[:SOLD]->(order);USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:orders.csv" AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (customer:Customer {customerID: row.CustomerID})
MERGE (customer)-[:PURCHASED]->(order);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
其次,创建products, suppliers, and categories的边关系.
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:products.csv" AS row
MATCH (product:Product {productID: row.ProductID})
MATCH (supplier:Supplier {supplierID: row.SupplierID})
MERGE (supplier)-[:SUPPLIES]->(product);USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:products.csv" AS row
MATCH (product:Product {productID: row.ProductID})
MATCH (category:Category {categoryID: row.CategoryID})
MERGE (product)-[:PART_OF]->(category);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
然后,创建employees之间的“REPORTS_TO”关系。
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:employees.csv" AS row
MATCH (employee:Employee {employeeID: row.EmployeeID})
MATCH (manager:Employee {employeeID: row.ReportsTo})
MERGE (employee)-[:REPORTS_TO]->(manager);- 1
- 2
- 3
- 4
- 5
最后,为优化查询速度,在orders上创建唯一性约束:
CREATE CONSTRAINT ON (o:Order) ASSERT o.orderID IS UNIQUE;- 1
此外,也可以通过运行整个脚本一次性完成所上述工作:
bin/neo4j-shell -path northwind.db -file import_csv.cypher.- 1
(4)最终成果

附:(1)Northwind SQL, CSV and Cypher data files (zip)
(2)Tool:SQL to Neo4j Import
这篇关于4.2、从RDBMS向Neo4j导数据【专题四:数据处理】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





