本文主要是介绍###好好好#####使用GraphFrames进行飞一般的图计算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GraphFrame是将Spark中的Graph算法统一到DataFrame接口的Graph操作接口。支持多种语言,可以通过Python使用。
本博客包括 On-Time Flight Performance with GraphFrames notebook 的完整内容,其中包括一些扩展功能,您可以通过 Databricks Community Edition免费试用(加入 beta waitlist) 。
Graphframes是开源项目,资源如下:
- Graphframes的源码工程:https://github.com/graphframes/graphframes
- Graphframes的文档工程:http://graphframes.github.io/user-guide.html
介绍
图结构是一个解决很多数据问题的直观的方法。无论是遍历社会网络,餐馆推荐,或者是飞行路径,都可以通过图结构的上下文来快速地理解所面临的问题: 顶点(Vertices)、边(edges)和属性(properties)。 例如,飞行数据的分析是一个经典的图论问题,机场用 vertices代表,飞行路线用 edges 来代表。同时,这里有很多属性与飞行路线有关,比如离港延误、飞机的类型和装载能力等等。
在这篇文章中,我们使用 GraphFrames (参见最近的介绍: Introducing GraphFrames) 通过Databricks notebooks 进行快速而简便的飞行数据分析,这个数据以graph的结构进行组织。
因为我们在使用 graph structures, 我们可以简单地提出几个在表格数据结构下不是那么直观看见的问题,比如:structural motifs, airport ranking(使用 PageRank),城市之间的最短路径等等。GraphFrames提升了DataFrame API的分布式计算和表达的能力,简化了Spark SQL engine的查询并且提升了性能。除此之外,GraphFrames所带来的图论分析能力可以用于 Python、Scala和Java等多种语言环境。
安装 GraphFrames Spark软件包
为了使用 GraphFrames, 你需要首先安装 GraphFrames Spark Packages。在Databricks中安装软件包是一个简单的过程( 参见: few simple steps )(join the beta waitlist here to try for yourself).
注意, 为了在spark-shell, pyspark, or spark-submit引用GraphFrames,需按下面的方法启动Spark的环境:
$SPARK_HOME/bin/spark-shell --packages graphframes:graphframes:0.1.0-spark1.6
准备 Flight Datasets
组成airports的图数据集(vertices)的两个部分在这里: OpenFlights Airport, airline 和 route data ,departuredelays dataset (edges) 在 Airline On-Time Performance and Causes of Flight Delays: On_Time Data。
在安装GraphFrames Spark软件包后(参考 GraphFrames Spark Package), 您可以import 创建vertices, edges, 和 GraphFrame (在 PySpark中) 如下所示:
| 1 2 3 4 5 6 7 8 9 |
|
例如, tripEdges包含的飞行数据有出发地的 IATA airport code (src) 和目的地IATA airport code (dst), city (city_dst), state (state_dst) 以及departure delays (delay)。
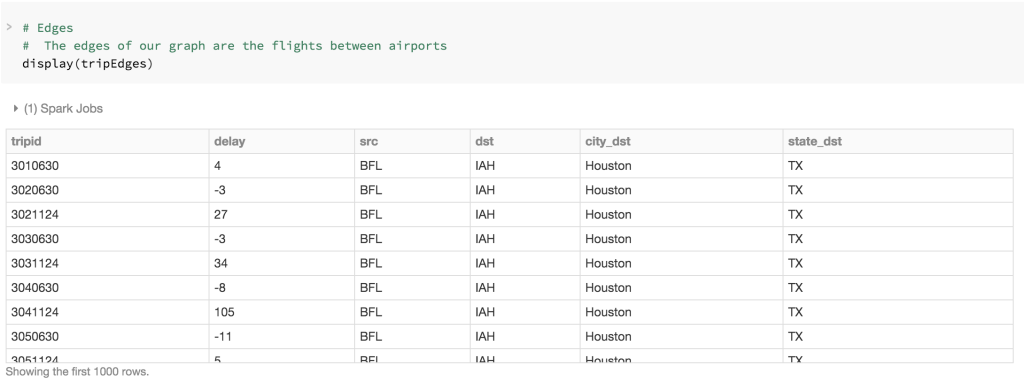
在tripGraph上简单查询
现在你已经创建自己的 tripGraph GraphFrame, 可以执行几个键大的查询,来快速地遍历和理解你的GraphFrame数据。例如, 为了了解GraphFrame中的机场和路线信息, 运行下面的 PySpark代码。
| 1 2 |
|
将返回输出:
Airports: 279
Trips: 1361141因为GraphFrames 是基于Spark中的DataFrame的Graphs数据结构, 您可以编写和使用DataFrame API的高级和复杂的查询表达式。 例如, 下面的查询允许我们在flights (edges)过滤出从 SFO airport出发的 delayed flights (delay > 0)。这里还可以计算和排序平均 delay的时间, 可以回答这些问题:从SFO出发的那些航班有显著的延误?
| 2 3 4 5 |
|
查看输出结果, 您可以快速发现在本数据集中从SFO出发的显著高于平均延误水平的机场: Will Rogers World Airport (OKC), Jackson Hole (JAC), 和 Colorado Springs (COS) 。

通过 Databricks notebooks, 我们可以快速进行地图上的可视化: 从SEA 出发的航班到那些州是有显著的延误的(高于正常值)?

使用Motif finding理解飞行延误
为了更容易地理解城市机场和航线之间的复杂关系, 我们使用Motif进一步挖掘机场airports (i.e. vertices)和航线flights (i.e. edges)之间的关系 . DataFrame的结果中column names通过motif keys给出。
例如, 提出问题 What delays might we blame on SFO?, 您可以创建出简化的motif,如下。
| 1 2 3 |
|
与 SFO 连接的城市 (b), 我们看到所有的航线 [ab] 从origin city (a) 连接到SFO (b) 优先于飞行 [bc] 到其他目的地城市 (c). 我们过滤出航线 ([ab] or [bc]) 超过500分钟并且第二航线(bc)在第一次飞行后大概一天内出现。
下面是一个从查询中节略的子集,列分别是对应的motif keys。
| a | ab | b | bc | c |
| Houston (IAH) | IAH -> SFO (-4) [1011126] | San Francisco (SFO) | SFO -> JFK (536) [1021507] | New York (JFK) |
| Tuscon (TUS) | TUS -> SFO (-5) [1011126] | San Francisco (SFO) | SFO -> JFK (536) [1021507] | New York (JFK) |
通过这个motif finding查询, 我们快速确定了that passengers in this dataset left Houston and Tuscon for San Francisco on time or a little early [1011126]. But for any of those passengers that were flying to New York through this connecting flight in SFO [1021507], they were delayed by 536 minutes.
使用PageRank发现最重要的机场
因为GraphFrames建立在GraphX之上, 这里有几个内置的算法我们可以立即利用这个优势。 PageRank在 Google Search Engine 中广泛使用,由 Larry Page创建。搜索Wikipedia的解释:
PageRank 的工作原理是对到页面的连接的数量和质量进行计数, 从而估计该页面的重要性。 缺省的假定是:越是重要的网站接收到的其它网站的链接就越多。
虽然上面的例子是关于网页的,但这一极好的理念可以用于任何图结构,而不管是来自网页、, 自行车站点, 或机场 airports,并且这一界面非常简单,就像调用一个方法一样。 您可能注意到,GraphFrames将返回 PageRank 结果,作为新的column追加到vertices DataFrame,在运行这个算法后简单地继续我们的分析。
在数据集中,这里有大量的不同机场的飞行和链接数量,我们使用 PageRank 算法在Spark中递归地遍历graph数据结构,计算出机场有多重要的一个估计值。
| 1 2 3 4 |
|
下面的图表显示,通过PageRank算法,Atlanta可以考虑为是最为重要的机场,这是基于不同 vertices (i.e. airports)的connections (i.e. flights)质量作出的推断 ; 与相应的事实是比较符合的(参见 Atlanta is the busiest airport in the world by passenger traffic)。
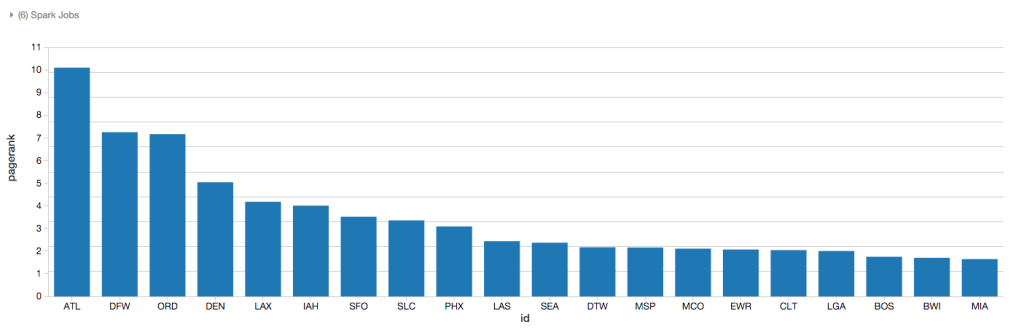
确定flight connections
不同城市之间有多个航班,您可以使用 GraphFrames.bfs (Breadth First Search,广度优先搜索) 方法去找到两个城市间的最短路径。下面的查询尝试发现San Francisco (SFO) 和 Buffalo (BUF) 为1的最大路径长度 (i.e direct flight)。 结果集为空 (i.e. no direct flights between SFO and BUF).
| 1 2 3 4 5 |
|
因此扩展查询为 maxPathLength = 2, 有一个以上链接的 flight(在SFO和BUF)。
| 1 2 3 4 5 |
|
从SFO 到 BUF 的结果集表格简略如下。
| from | v1 | to |
| SFO | MSP (Minneapolis) | BUF |
| SFO | EWR (Newark) | BUF |
| SFO | JFK (New York) | BUF |
| SFO | ORD (Chicago) | BUF |
| SFO | ATL (Atlanta) | BUF |
| SFO | LAS (Las Vegas) | BUF |
| SFO | BOS (Boston) | BUF |
| … | … | … |
使用D3可视化飞行路线
为了实现一个功能强大的航线和链接的可视化效果,我们利用Databricks notebook在 Airports D3 visualization 中的方法。通过链接GraphFrames, DataFrames, 以及 D3 可视化工具, 我们可视化显示所有的飞行链接,如下所示。蓝色圆圈代表vertices (i.e. airports),圆圈的大小代表 边的数量 (i.e. flights) ,即进出港的航线。黑线是边 (i.e. flights) 以及相应到定点 (i.e. airports)的连接. 注意,有一些边到了屏幕外面, 代表是到Hawaii 和 Alaska的顶点 (i.e. airports) 。
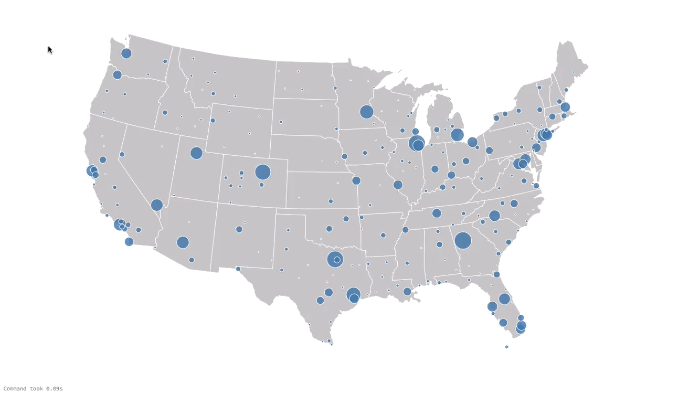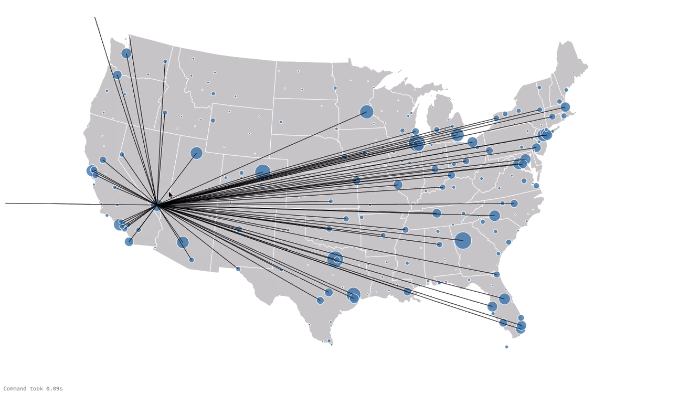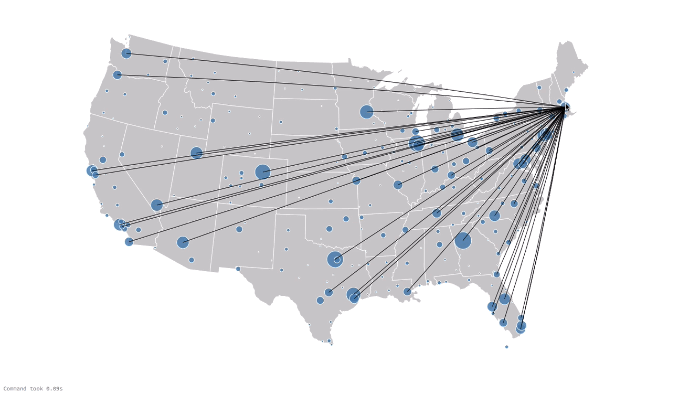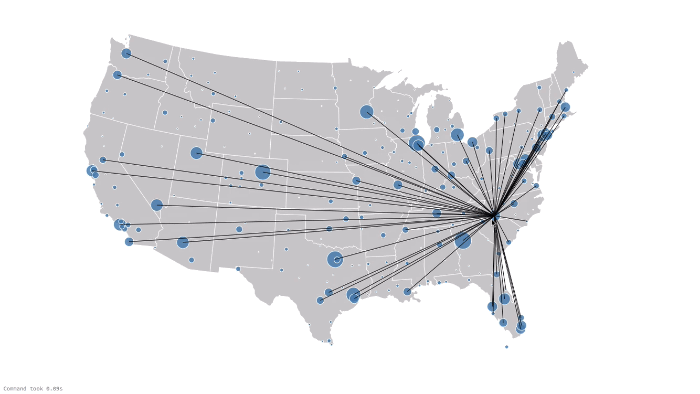
下一步: 自己试一试
你可以看到完整的代码: On-Time Flight Performance with GraphFrames notebook ,其中包括更多的扩展例子。你可以 import 这个 notebook文件到您的 Databricks 账户中。执行 notebook 可以采用这一些步骤: simple few steps。
Graphframes是开源项目,更深入的应用参考如下资源:
Graphframes的源码工程:https://github.com/graphframes/graphframes
Graphframes的文档工程:http://graphframes.github.io/user-guide.html
这篇关于###好好好#####使用GraphFrames进行飞一般的图计算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




