本文主要是介绍看Diffusion模型如何提升端到端自动驾驶的能力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章链接:https://openreview.net/pdf?id=yaXYQinjOA
自动驾驶领域在分割和规划模型性能方面取得了显著进展,这得益于大量数据集和创新的架构。然而,这些模型在遇到罕见子群,比如雨天条件时,往往表现不佳。获取必要的大规模和多样化数据集以改善在这些子群中的泛化能力,进一步受到手动标注的高成本和工作量的阻碍。
为了解决这个问题,本文引入了SynDiff-AD,这是一个独特的数据生成pipeline,旨在为被低估的子组群合成逼真的图像。该系统利用潜在扩散模型(LDMs)和细致的文本提示来生成基于现有数据集标注的图像,忠实地保留它们的语义结构。这关键地消除了手动标注的需求。通过用该系统生成的图像增强原始数据集,展示了高级分割模型(如Mask2Former和SegFormer)性能提升了+1.4个mIoU。除此之外,还观察到,端到端自动驾驶规划模型(如AIM-2D和AIM-BEV)在各种条件下的驾驶能力提高了20%以上。彻底分析突显了本文的方法也对整体模型改进做出了贡献。
介绍
自动驾驶(AD)领域近年来取得了显著进展,得益于车队收集的大规模数据集。这一数据爆炸提供了宝贵的训练资源。然而,一个关键问题出现了:收集到的数据往往存在对有利天气条件的偏向,比如晴朗和晴空万里。Waymo Open Dataset 和 BDD100K等数据集都表明了这一点,其中相当大一部分样本属于这一类别。这种不平衡影响了模型在分割和规划任务中的性能,尤其是在遇到像雨天或多云这样不太常见的场景时。此外,相关的手动标注成本对于额外收集的数据来说是相当大的。
为了解决这些挑战,本文提出了SynDiff-AD,这是一个新颖的pipeline,用于为低估的子组群生成逼真的数据,以增强现有的AD数据集。SynDiff-AD利用了文本到图像受控生成领域的巨大进步,例如[28, 30]等工作,以生成现有数据集样本的变体,同时保留其语义结构。
下图1中概述的方法消除了语义分割和端到端自动驾驶任务中手动标注的需求。首先,确定数据集中的低估子组群。然后,使用ControlNet,一种潜在扩散模型(LDM),将过度代表的子组群的样本转换为所需的低估条件,同时保护其语义内容。生成的图像用于增强现有的AD数据集,从而对分割和端到端驾驶模型进行微调。关键是,本方法不需要人工标注。
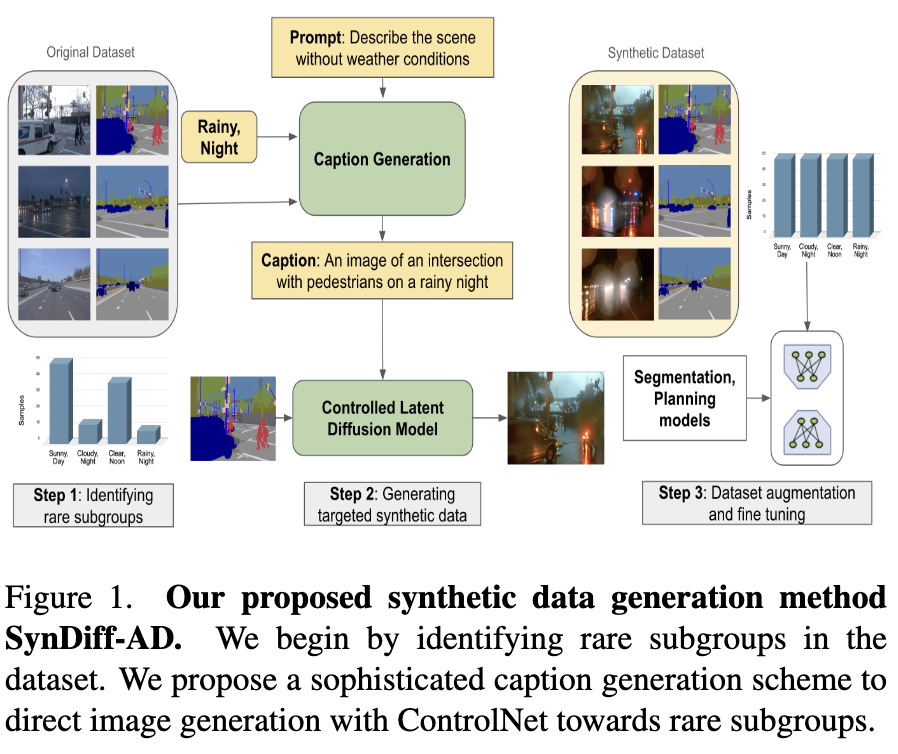
本文的主要贡献总结如下:
-
提出了SynDiff-AD,这是一种基于条件LDM的方法,灵感来自ControlNet,用于合成非代表性数据集子组群的样本。该系统修改来自代表性的子组群的图像,细致地保留了语义结构。
-
从文本反转概念中汲取灵感,为数据增强设计了一种新颖的提示方案。利用LLaVA,一种视觉语言字幕模型,来描述代表性的子组群中的图像。这些描述被小心地修改以反映非代表性情景,指导我们系统中的生成过程。
-
广泛实验表明,利用增强后的数据集对最先进的语义分割和自动驾驶模型进行微调,可以在所有子组群中获得改进的平均性能。
相关工作
语义分割和端到端(E2E)自动驾驶
先前在语义分割和端到端自动驾驶方面的研究主要侧重于架构修改。最先进的语义分割模型现在大量使用Transformer架构。在端到端自动驾驶中,重点是设计模型架构来预测车辆跟踪的未来路径点,通常利用多模态数据,如摄像头图像和LiDAR深度信息。相比之下,本文探索了一个不同的方向:通过使用合成数据增强来改善最先进的语义分割和端到端自动驾驶模型的性能。
生成模型改进感知和规划任务的合成数据
建立在扩散概率模型(DPMs)上的文本到图像生成模型,如Stable Diffusion和Glide,擅长从文本生成高质量的合成数据。然而,它们在对图像中的对象进行精确修改方面存在困难。已经出现了解决方案,包括用于定向调整的Pivotal Tuning,用于使图像适应新概念的Textual Inversion ,以及用于在诸如语义图之类的元素上进行生成条件的ControlNet。FreestyleNet通过注意力图进一步细化了控制,而Edit-Anything结合了ControlNet、Segment Anything(SAM)和BLIP2等工具进行多功能编辑。这些方法已被改编用于改进感知模型,这与GAN生成的合成数据相辅相成,以改进感知模型。
扩散模型已将合成数据应用扩展到目标分类、检测和分割。像DatasetDM方法生成图像和标注,而DGInStyle侧重于样式转换。然而,没有一个特别针对低估子组群的分割性能。对于自动规划,合成数据传统上来自昂贵的3D游戏引擎(Unity,UE4),便于程序生成和专家数据收集。相比之下,本文的方法利用现有的语义数据进行图像生成,消除了对额外人工专家输入的需求。
方法
在本节中,概述了提出的方法SynDiff-AD。详细说明用于生成条件于语义mask的合成数据的方法。使用ControlNet对生成的数据进行改进,使用文本字幕和样式提示进行微调。最后,概述了用于合成针对低估子组群的数据的过程,用于语义分割和自动驾驶任务。
初步
本文的目标是增强由参数θ参数化的模型f在每个子组群z上的性能,其中表示与子组群z相对应的数据分布。在本文中,指的是一个参数化的分割或自动驾驶模型,用于为输入图像产生输出y。对于分割,y是一个分割图,而对于E2E驾驶,y表示位置偏移。此外,是一个度量,分别是Mean Intersection over Union (mIoU) 和规范化的驾驶得分,用于分割和E2E驾驶。
假设一个预定义的子组群集合,它包含了一个操作设计域。中的每个子组群都是一个语义属性,例如天气或照明条件。该域是组合的 [24],即,其中每个表示一个不同的语义维度。在这里,表示语义维度的总数。使用CLIP根据这些语义属性对现有的测试数据集进行分区,因为它们缺乏显式的子组群标签。如果一个子组群在测试集中表示不足,则评估使用相应的训练图像。
标签条件的图像生成
SynDiff-AD利用语义mask和文本到图像生成模型,为非代表性子组群合成像素对齐的图像-mask对。利用ControlNet,它通过在潜在扩散模型(LDM)的去噪过程中提供额外的控制,如语义mask,来扩展Stable Diffusion。这通过一个镜像U-Net编码器实现,该编码器在指导图像生成的同时保持语义mask的布局。当为分割或自动驾驶对ControlNet进行微调时,冻结LDM参数。训练集中重点放在ControlNet的镜像U-Net上,该网络接收语义mask。文本提示用于描述图像,将期望的子组群作为风格进行融合。分别为每个领域(分割,驾驶)对ControlNet进行微调。
通过VLMs改进文本提示和子组群作为ControlNet的风格提示
为了提高合成数据的质量,使用高质量的描述作为合成提示。这些描述已被证明可以增强图像的真实感,是使用LLaVA生成的。LLaVA利用一个VLM(Vicuna)和从CLIP提取的图像特征来生成描述。
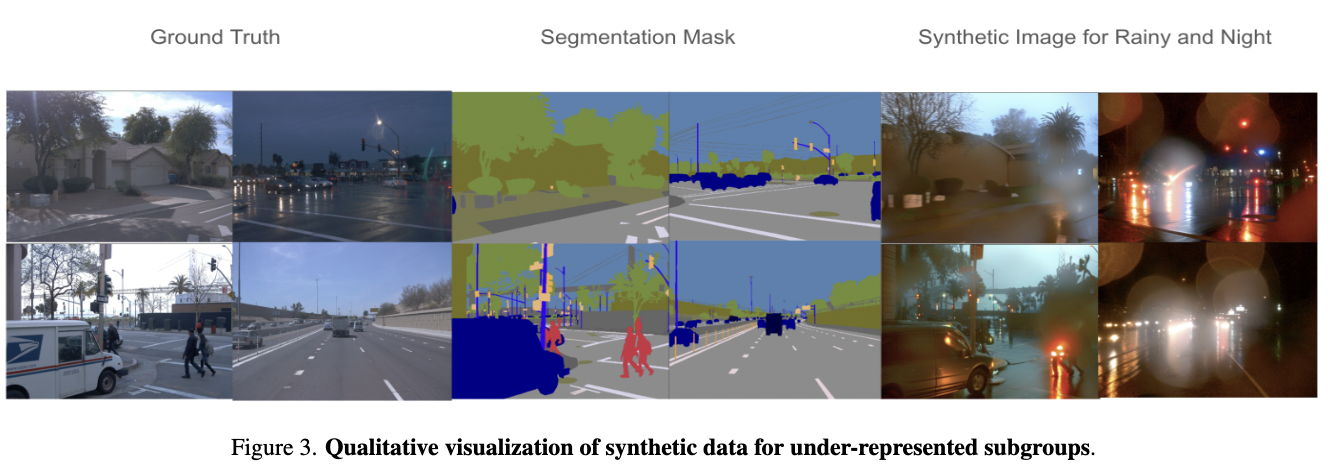
在SynDiff-AD中,使用LLaVA以视觉问题的形式为分割和驾驶数据集生成描述。查询基于语义mask类别,指示LLaVA排除与目标子组群 相关的关键词。此过程如下图2所示。

实验表明,LLaVA的描述提高了ControlNet合成图像在分割任务中的真实感。此外,使用风格提示来确保ControlNet捕获每个子组群的独特特征。具体来说,将文本提示(按照描述的方式生成)与子组群 z(由CLIP识别)及其语义维度进行融合。例如,如果数据集按天气划分,将“在多云天气下拍摄的图像”附加到LLaVA生成的描述中。这种风格提示指导ControlNet合成针对特定非代表性子组群的数据。
生成合成数据集
使用ControlNet进行分割和自动驾驶的图像合成
使用算法1生成语义分割的合成图像。对于自动驾驶,进行了关键修改。由于驾驶标注(例如路径点)不描述视觉场景,需要语义表示来确保真实的合成。可以从预训练的分割模型或者当可用时(例如在CARLA仿真器中)直接从提供的语义图中获取这个布局。一旦有了语义布局,图像合成就像在分割情况下进行。

结果
本文的实验旨在分析在合成数据上训练模型是否能提高整体的分割和自动驾驶(AD)性能。子组群特定性能改进的结果在补充材料中提及。使用了两个分割数据集:Waymo Open Dataset(37618张带标注的图像)和BDD100K(7000张带标注的图像)。操作设计域包括天气(雨天、晴天、多云)和时间段(黎明/黄昏、早晨、夜晚),共计9个子组群(详见附录)。对于自动驾驶,使用基于CARLA仿真器的数据集,并使用专家驾驶策略。数据收集涵盖了3个城镇、15条路线,每条路线的天气固定以保证真实性。测试涵盖了27条路线,考虑了所有天气条件,使用与分割相同的操作设计域。
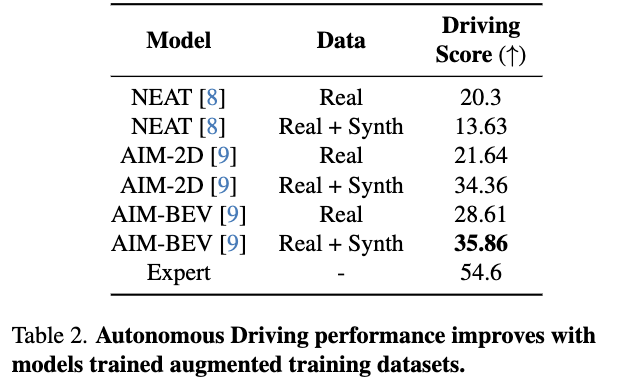
实现细节
在Waymo、BDD(分割)和CARLA(自动驾驶)数据集上对ControlNet进行微调。图像和mask都调整为512x512大小。使用5轮训练制度,学习率为,并使用8个A-5000 GPU。在推断过程中,如前所述,算法1引导了样式交换,以便生成针对非代表性子组群的合成图像。对于语义分割实验,使用Mask2Former(Swin-T和ResNet-50骨干网络 )和SegFormer(MIT-B3骨干网络])。对于端到端自动驾驶实验,在单个A-5000 GPU上对NEAT、AIM-2D和AIM-BEV进行微调,用于模型的训练/评估。
微调对最终性能的影响
使用标准指标(mIoU、平均准确率、平均DICE、平均F1)分析Waymo和BDD100K数据集中类别的分割模型。对于自动驾驶(AD),我们采用路线完成、违规得分和驾驶得分。合成数据增强提高了分割性能(下表1)。
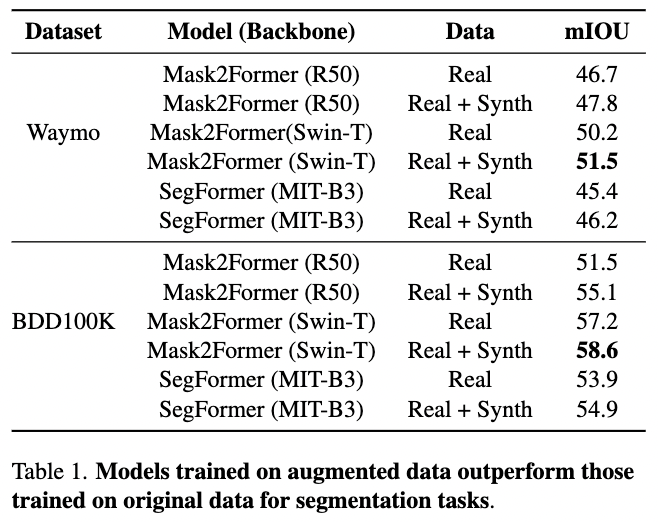
显著的增益包括Mask2Former(Swin-T)在Waymo上的+1.3 mIoU,以及Mask2Former(ResNet50)在BDD100K上的+3.6 mIoU。在AD(CARLA仿真器)中,AIM-2D和AIM-BEV受益于合成数据,主要是由于改进的违规得分(更少的碰撞)。然而,NEAT性能下降,可能是由于合成多摄像头视图中空间几何不一致性引起的。假设合成图像提供了上下文敏感的增强,有助于在子组群内跨视觉和结构元素的泛化。
结论与局限性
本文解决了偏倚数据集的挑战,这些数据集阻碍了在非代表性条件下的自动驾驶性能。SynDiff-AD通过利用先进的文本到图像生成技术与ControlNet,以实际增强数据集并保留语义细节,从而提供了解决方案,消除了手动标注的需求。展示了SynDiff-AD改进分割和自动驾驶任务的能力。
SynDiff-AD方法的一个主要局限性是需要用自然语言指定的子组群。未来的研究可以通过图像描述来发现基于图像的数据集中的测试子组群。未来的研究可以探索将我们的生成方法与其他数据增强和任务对抗性增强技术相结合,并改进ControlNet以在自动驾驶中保持多摄像头视图的空间几何关系。这些进步将提高自动驾驶系统的稳健性。
参考文献
[1] Improving End-To-End Autonomous Driving with Synthetic Data from Latent Diffusion Models
更多精彩内容,请关注公众号:AI生成未来

欢迎加群交流AIGC技术,添加小助手

这篇关于看Diffusion模型如何提升端到端自动驾驶的能力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




