本文主要是介绍R语言实战——中国职工平均工资的变化分析——相关与回归分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
链接:
R语言学习—1—将数据框中某一列数据改成行名
R语言学习—2—安德鲁斯曲线分析时间序列数据
R语言学习—3—基本操作
R语言学习—4—数据矩阵及R表示
R语言的学习—5—多元数据直观表示
R语言学习—6—多元相关与回归分析
1、源数据
各行业平均工资变化
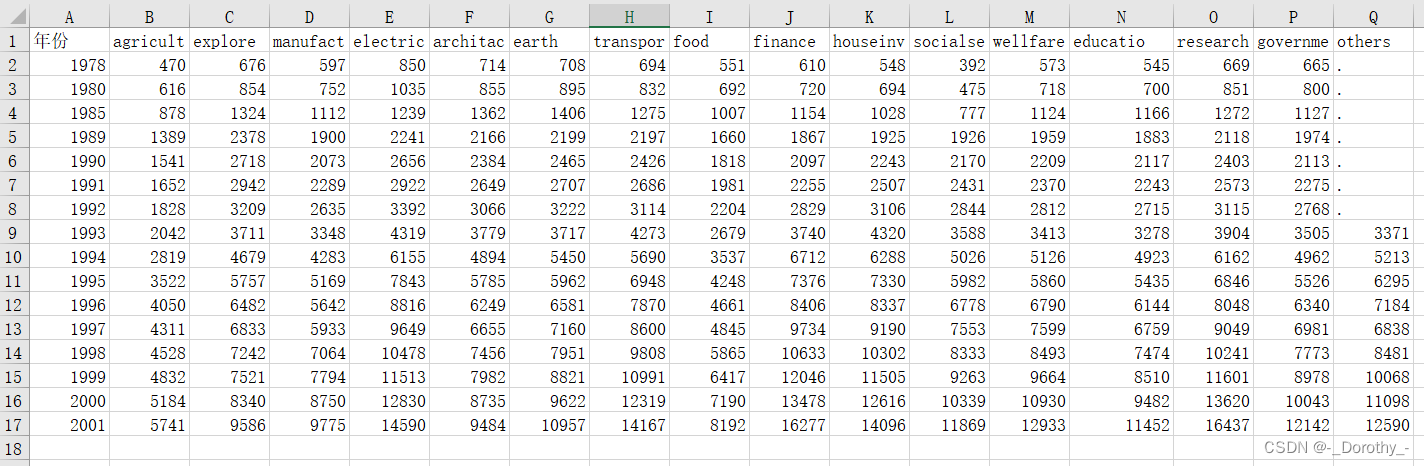
各地区平均工资变化
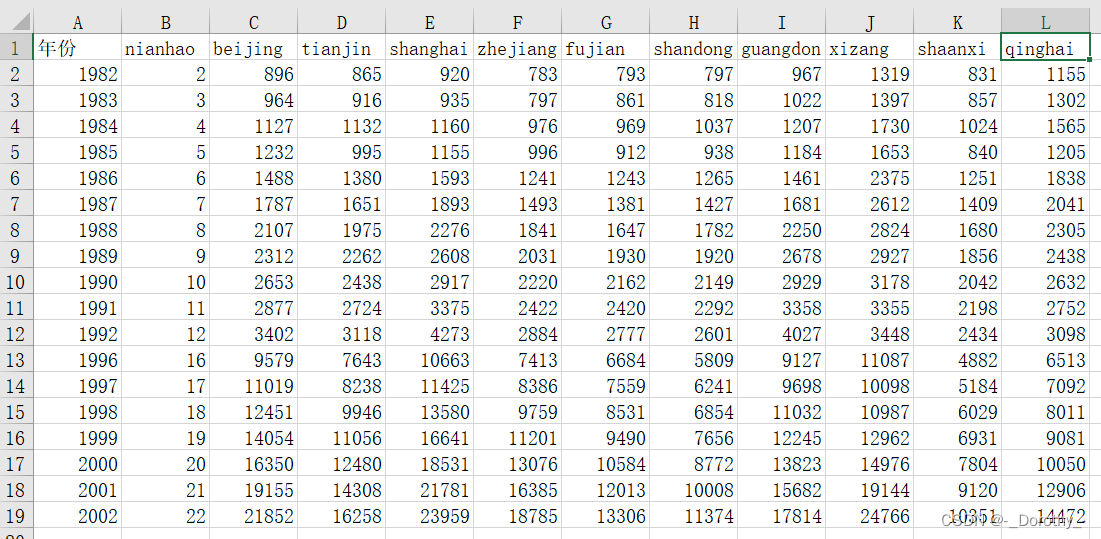
全国平均工资变化
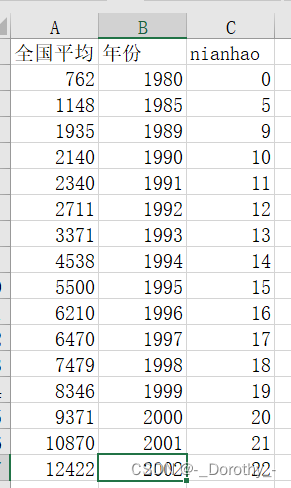
2、数据导入与预处理
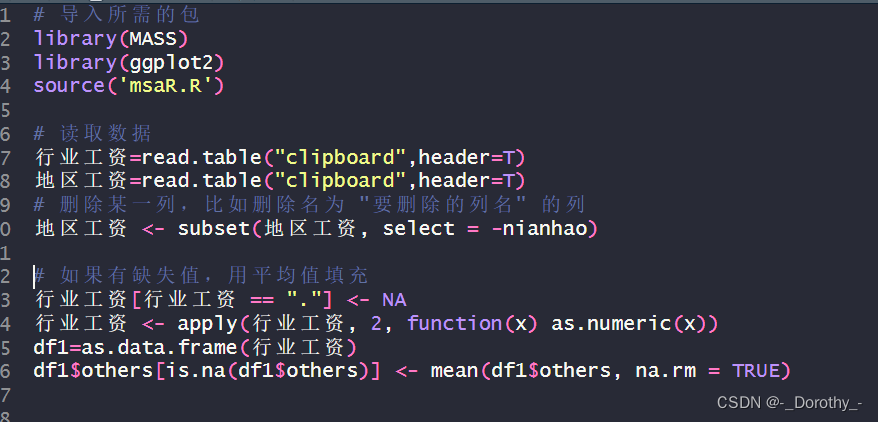
导入数据
行业工资
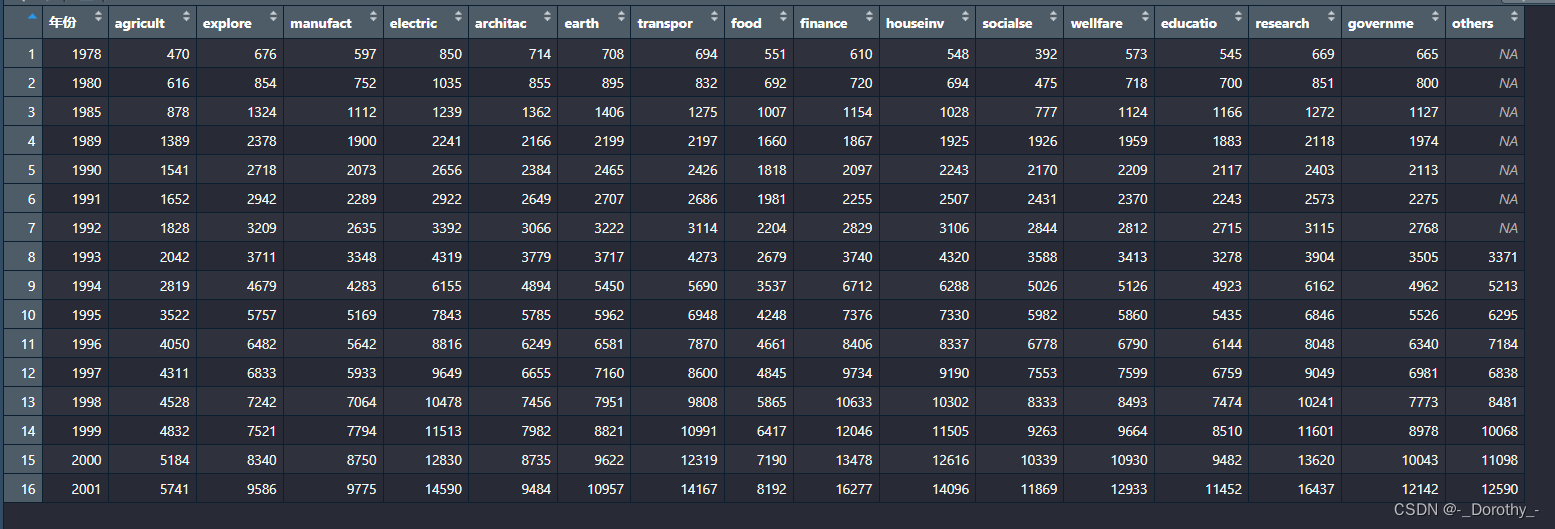
地区工资
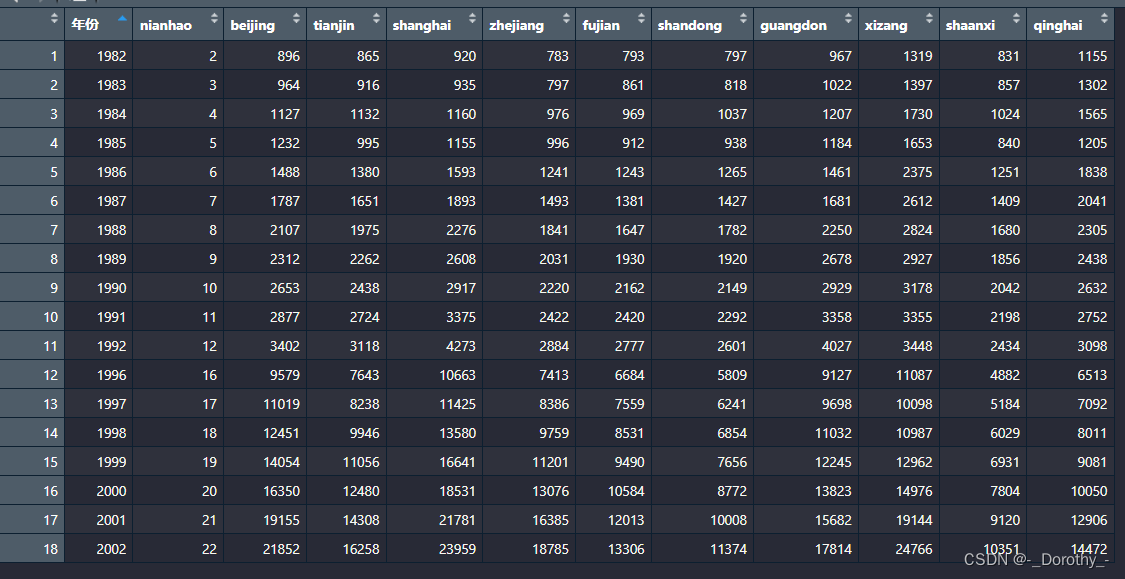
检查发现
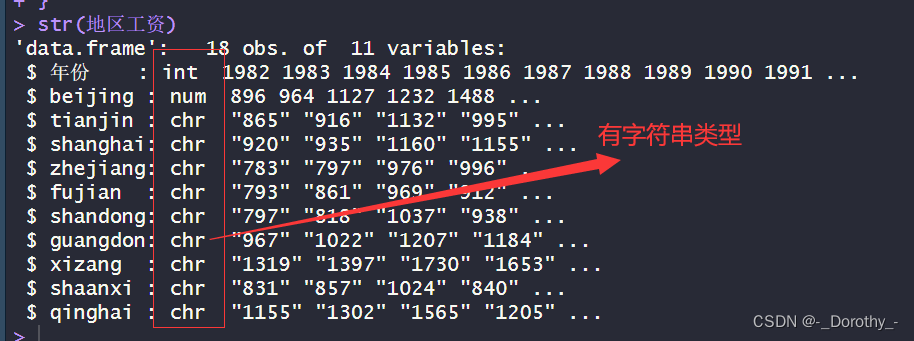

处理结果
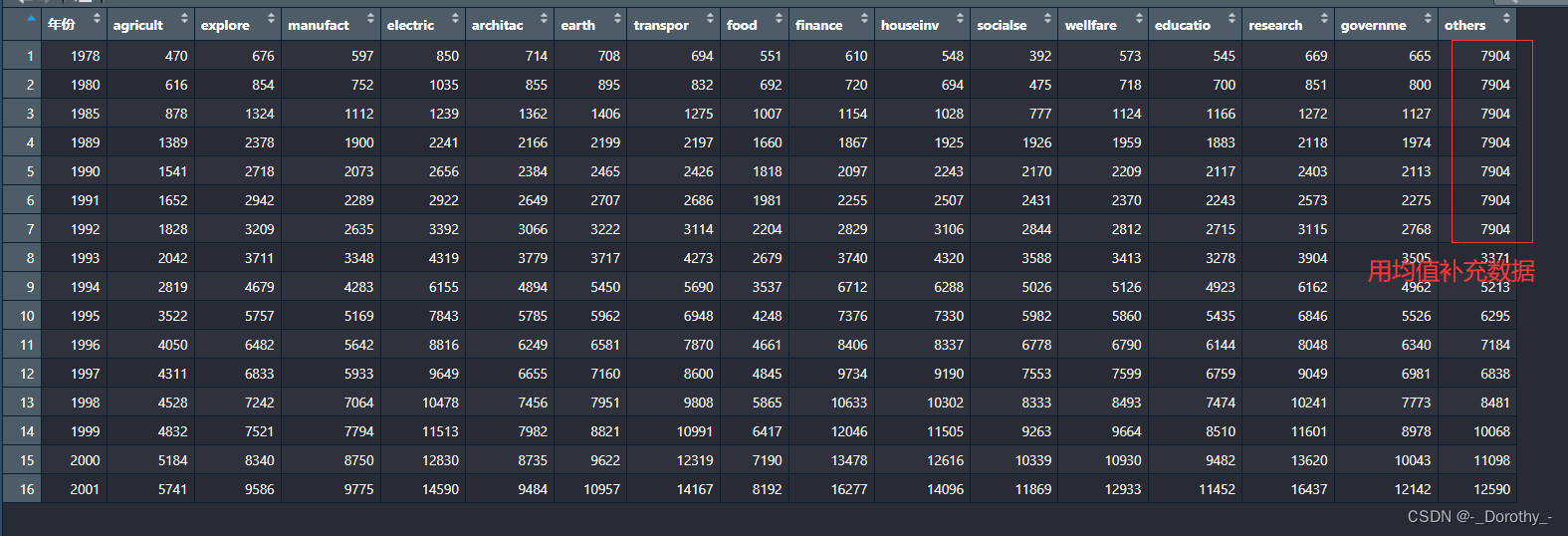
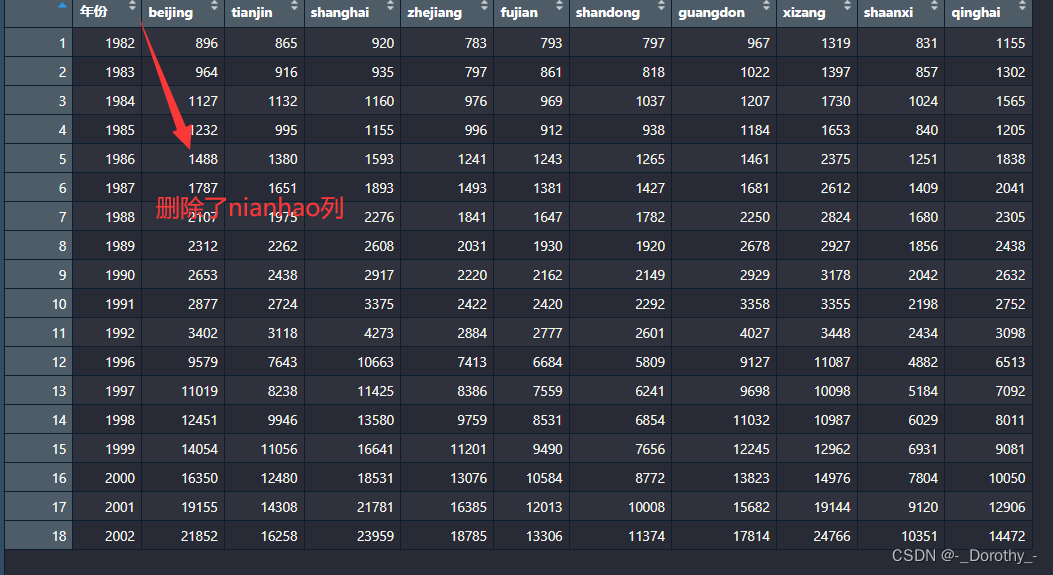
3、汇总统计
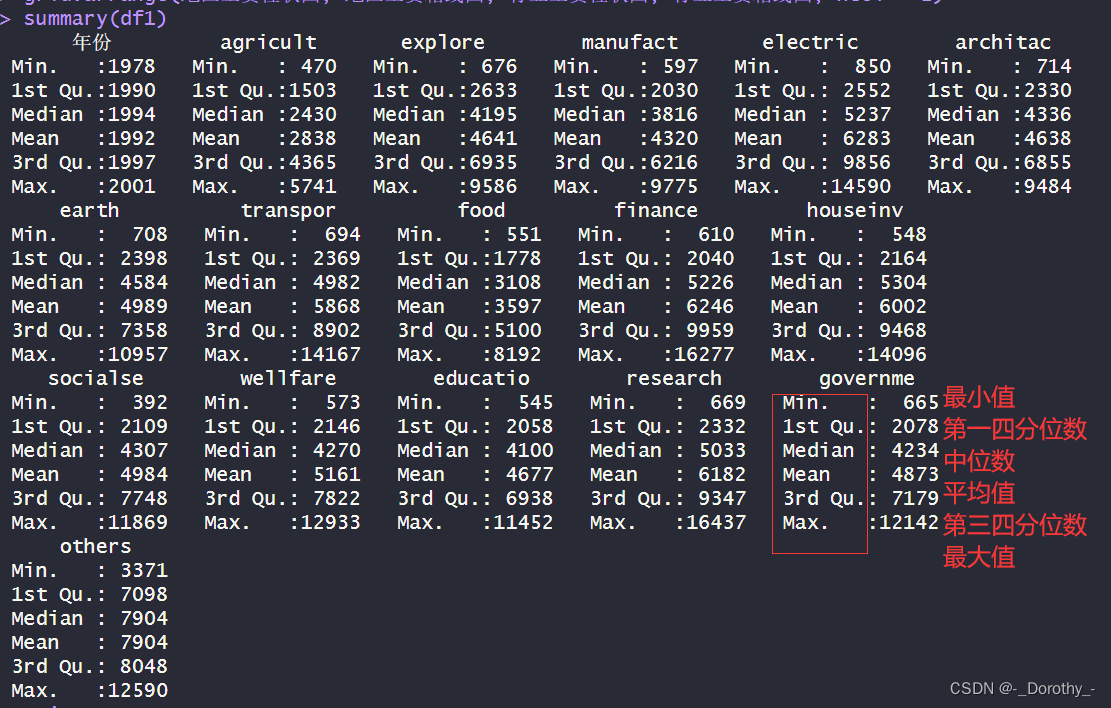
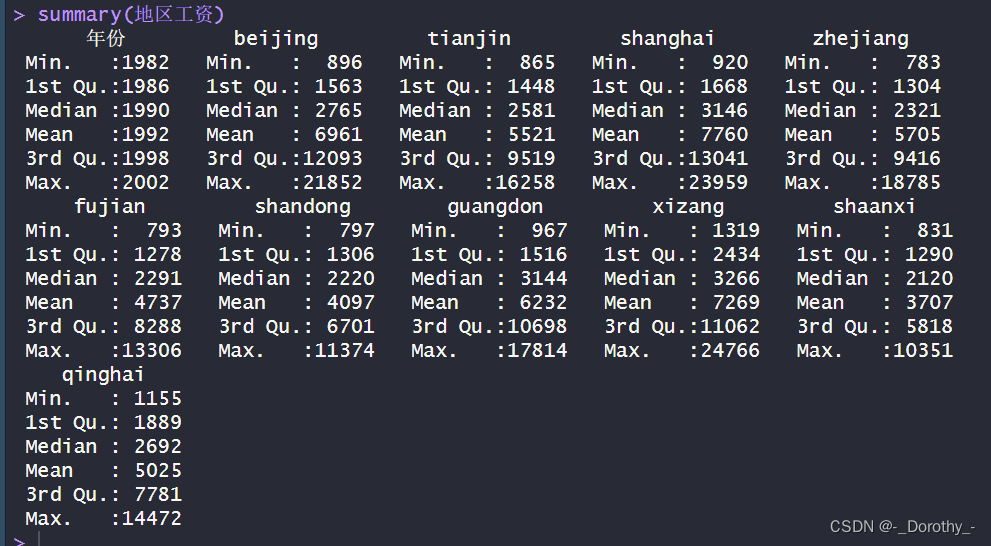
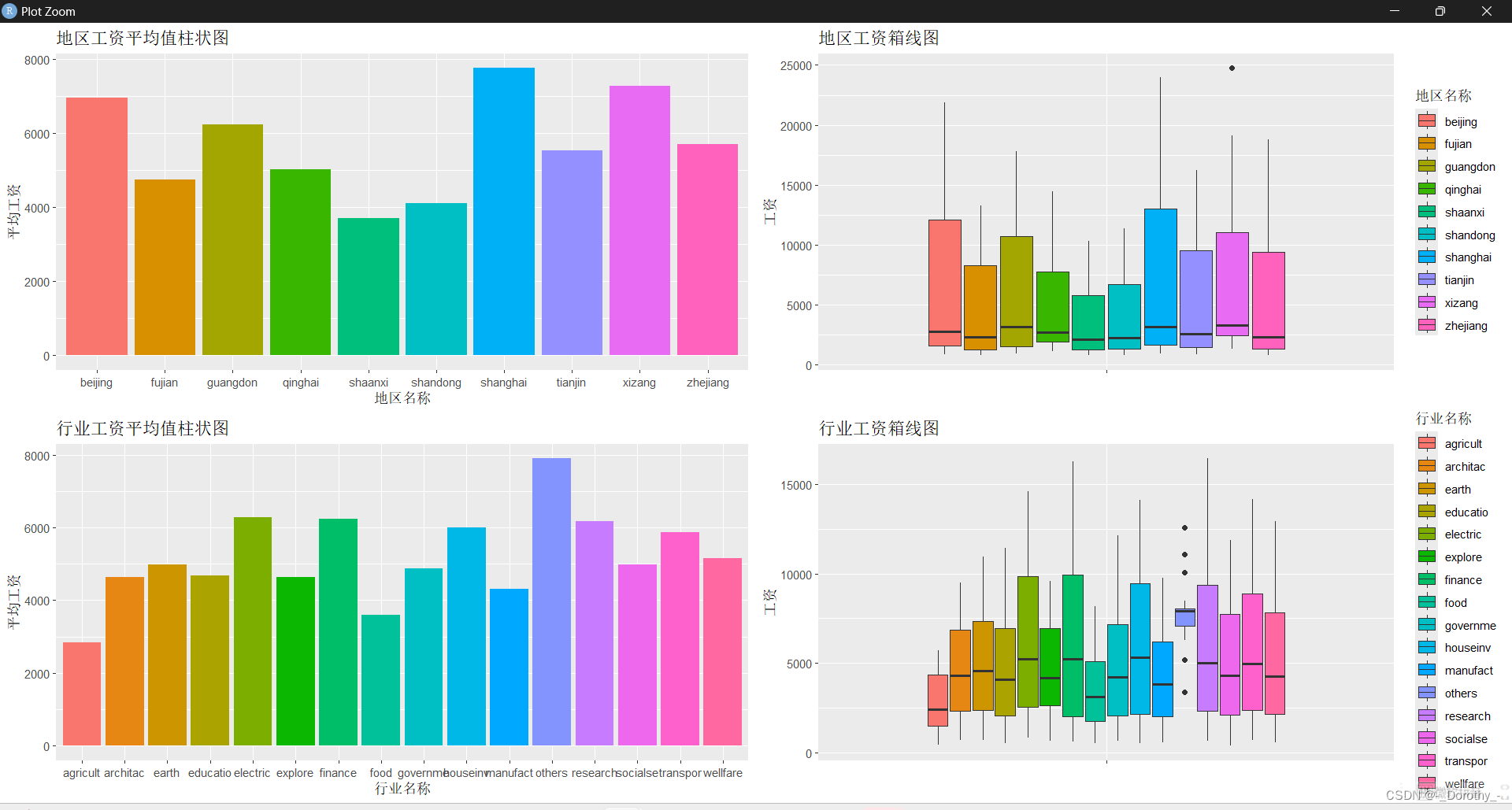
4、真实值可视化
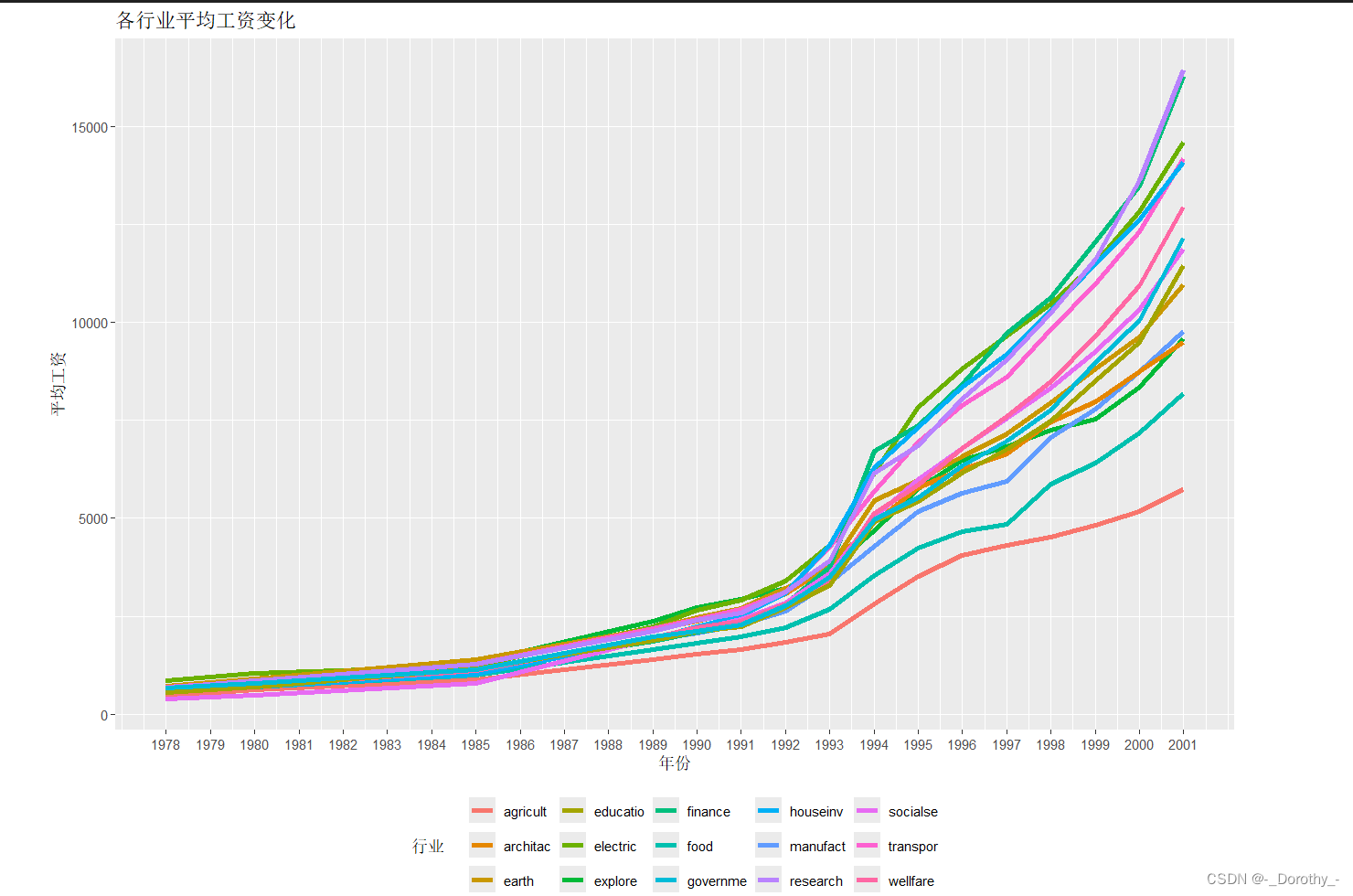
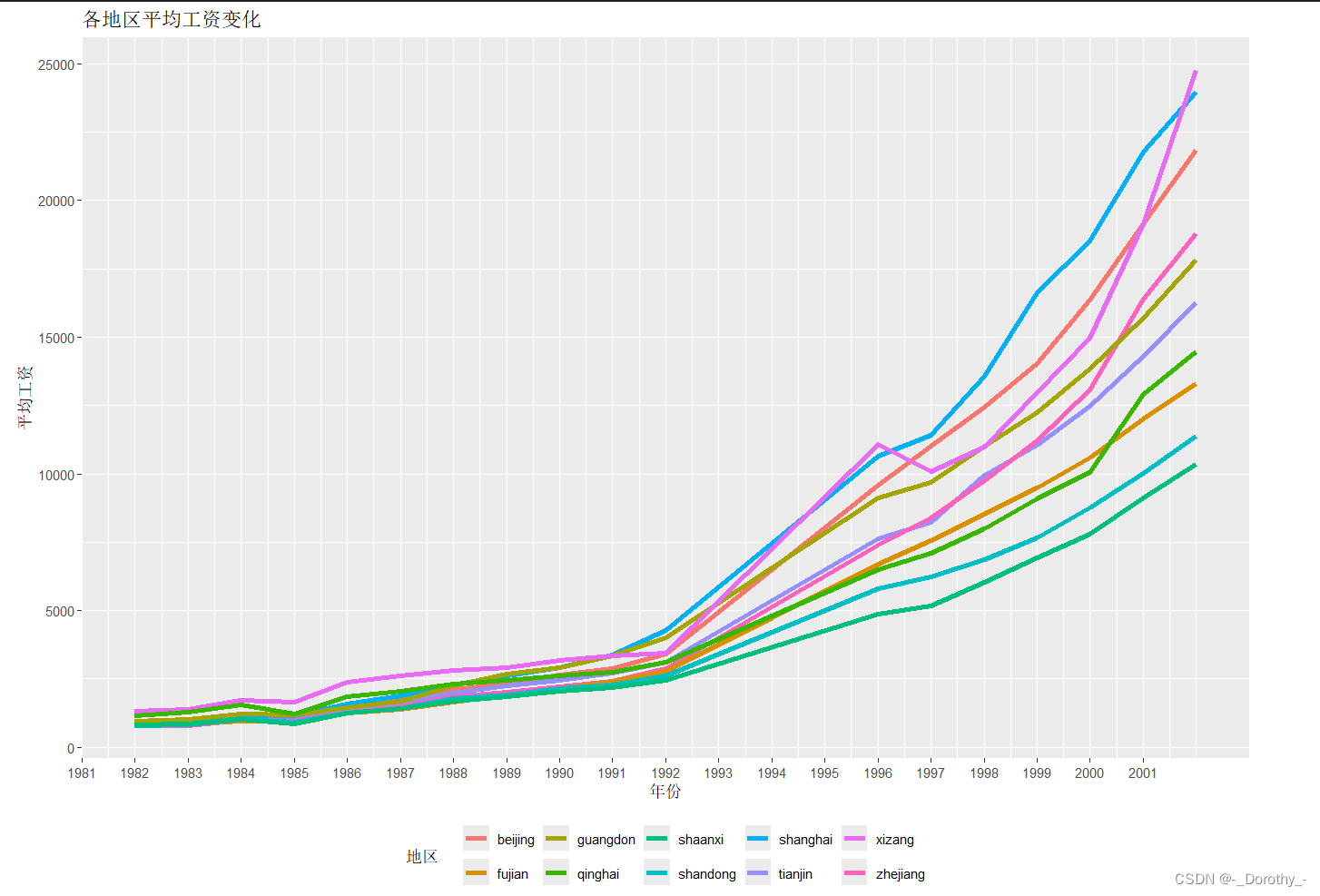
5、相关矩阵
行业工资相关矩阵
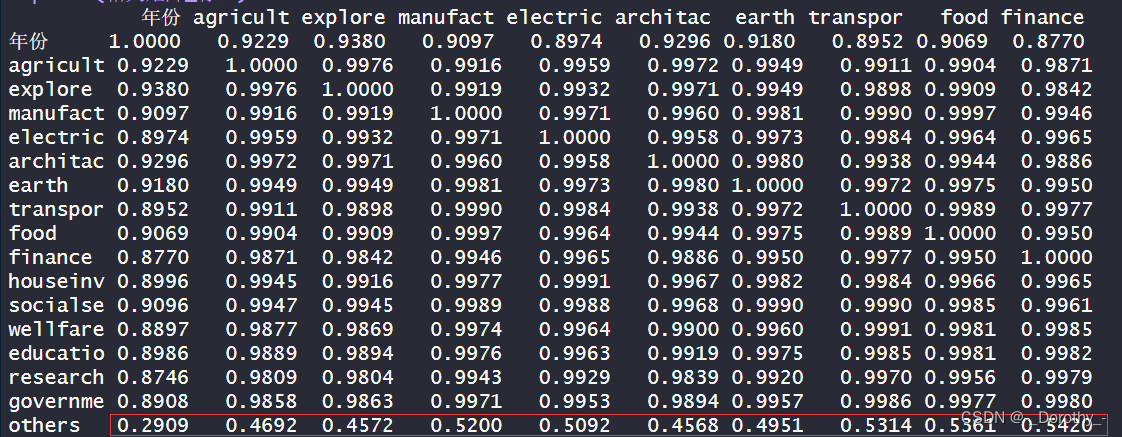
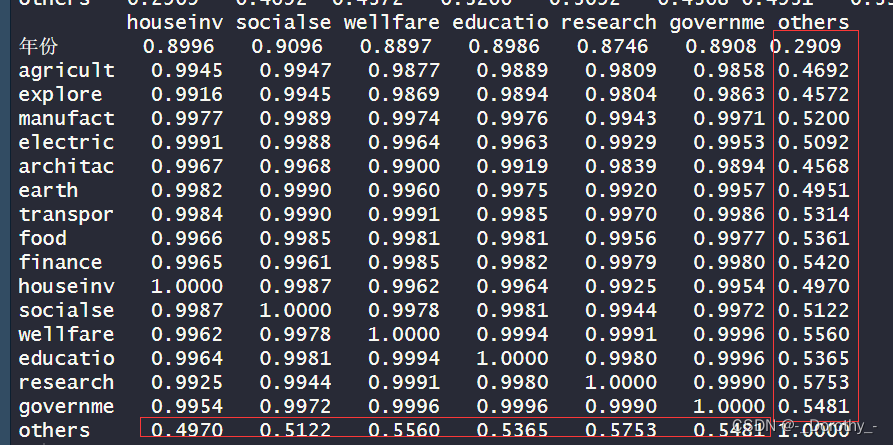
结论
1.大多数行业之间的相关性较高,特别是I业相关的行业,如"agricult"、“explore”、 “manufact”、 “electric” 等,它们之间的相关系数都接近1,这表明它们的工资水
平变化很可能相互关联。
2.与其他行业相比,“others” 与大多数行业的相关性较低,相关系数都在0.5左右。这可能意味着它的工资水平与其他行业的工资水平变化关系较弱。
3. “wellfare"和"educatio”、“research”、 “governme” 之间的相关性相对较高,这可能反映了教育、研究和政府部门之间的相互关联。
地区工资相关矩阵
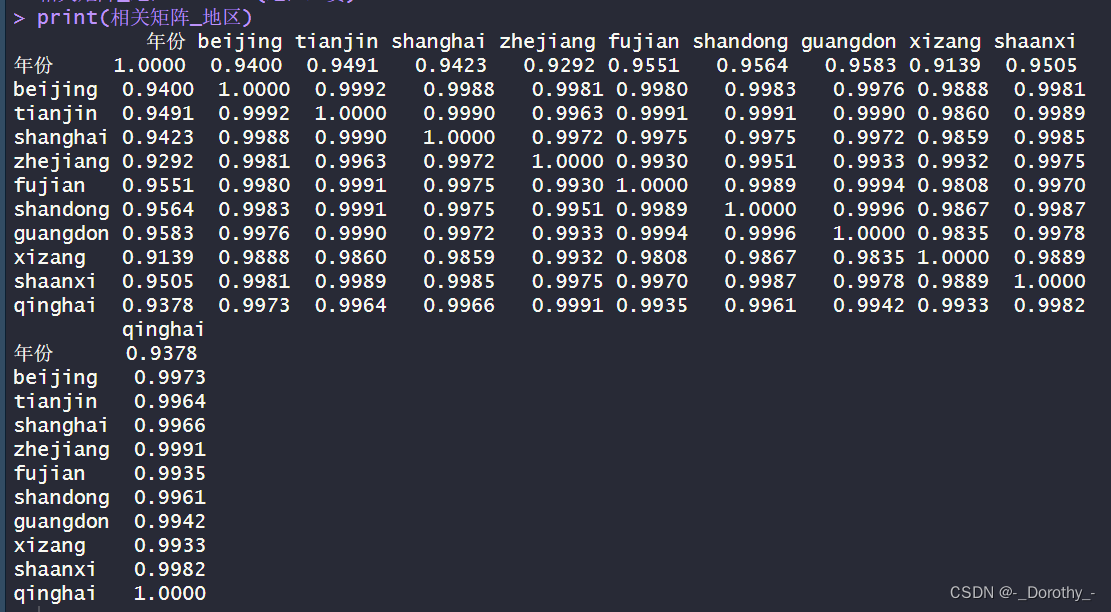
结论
1.大多数地区之间的相关性都比较高,特别是在接近1的值。这表明这些地区的工资水平变化很可能是相互关联的,即当一个地区的工资增加时,其他地区的工资也很可能增加,反之亦然。
2.每个地区与其他地区之间的相关性几乎都接近1,这可能反映了整体经济发展趋势的影响。例如,北京、上海、广东等经济发达地区之间的相关性较高,这符合它们在经济上相互依存的情况。
3.与其他地区相比,西藏的相关性较低,这可能是由于西藏的地理位置和经济结构与其他地区有较大的差异,导致其工资水平与其他地区的工资水平变化关系较弱。
4.青海与其他地区之间的相关性也较低,这可能是由于青海的经济发展水平相对较低,与其他地区相比,工资水平变化受到的影响较小。
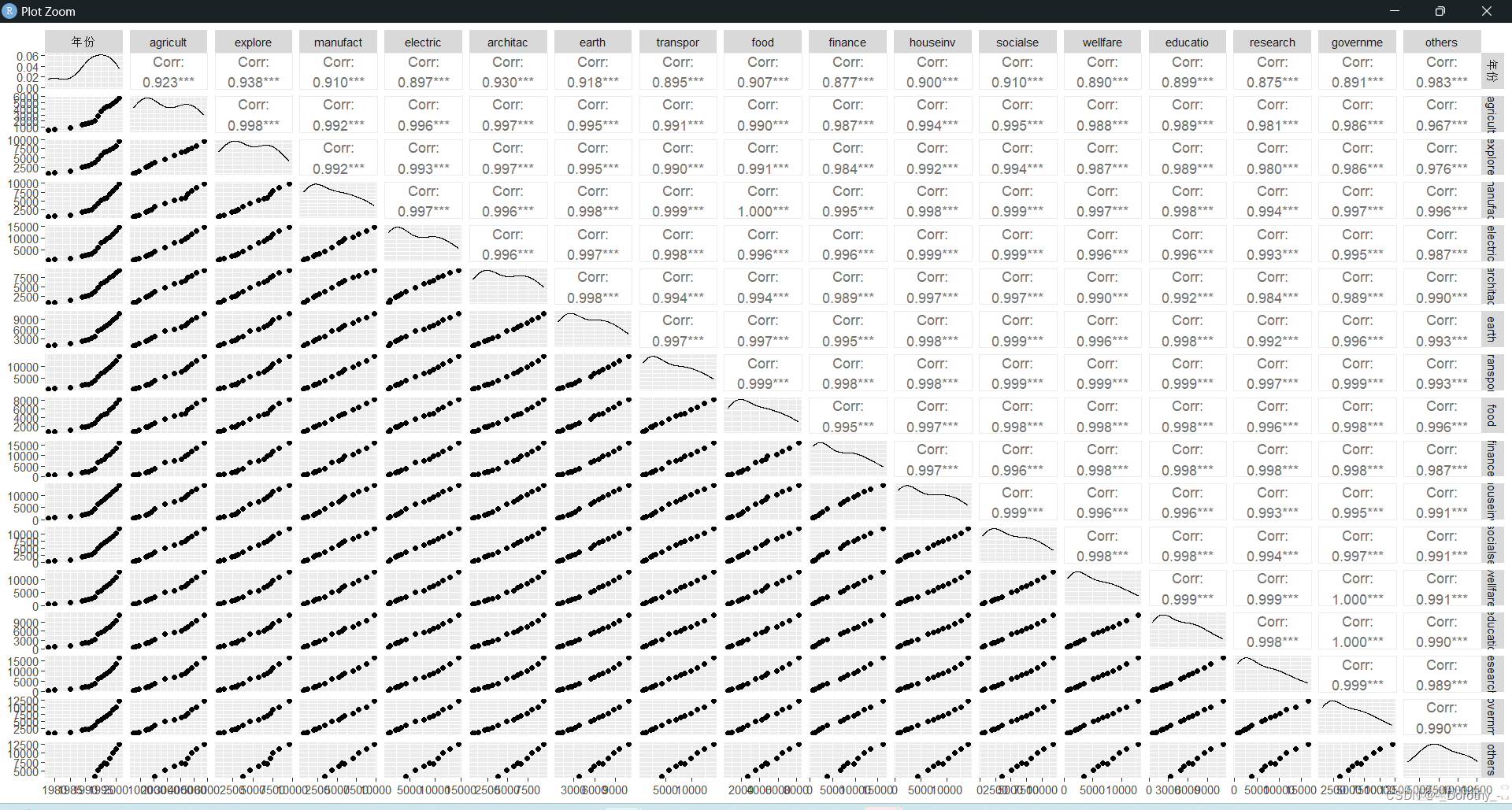
5、相关矩阵散点图
行业工资矩阵散点图
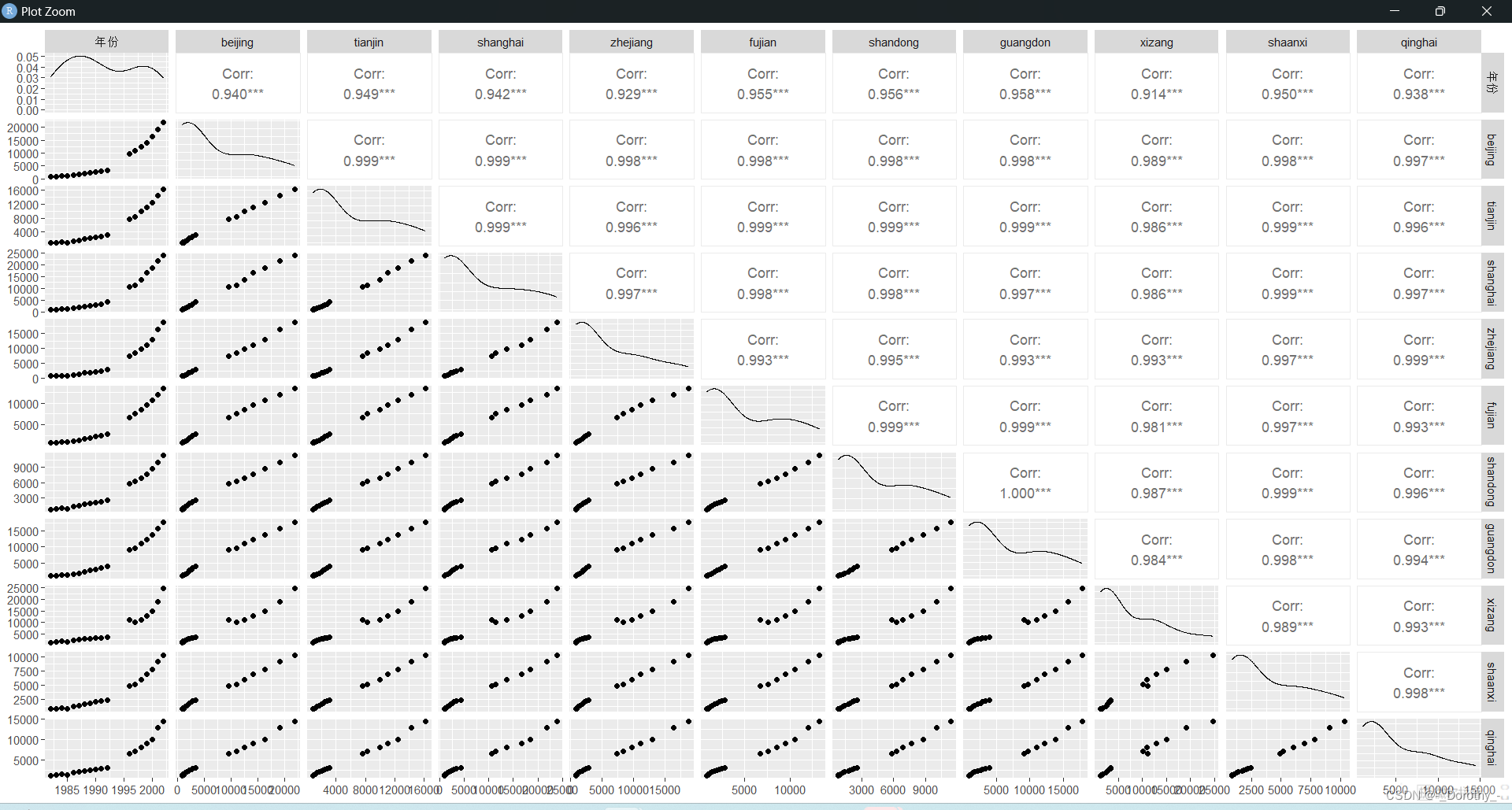
地区工资矩阵散点图
6、相关性检验
1.相关系数和显著性检验(t值和p值) :
●相关系数给出了每对变量之间的相关性强度,范围在-1到1之间。值越接近1或-1,表示变量之间的相关性越强,正值表示正相关,负值表示负相关。
●t值是用于判断相关系数是否显著的统计量,如果t值越大,相关性越显著。通常t值的绝对值超过1.96 (对应p值小于0.05)可以认为相关性是显著的。
●p值用于衡量相关性是否显著,通常取值在0到1之间,p值小于显著性水平(例如0.05)时,相关性被认为是显著的。
2.解释:
●如果相关系数高且显著(t值大,p值小), 那么变量之间存在较强的线性相关性。
●如果相关系数低或者不显著,那么变量之间可能不存在线性相关性。
t值和p值可以帮助判断相关性是否由于随机因素弓|起的。
行业工资
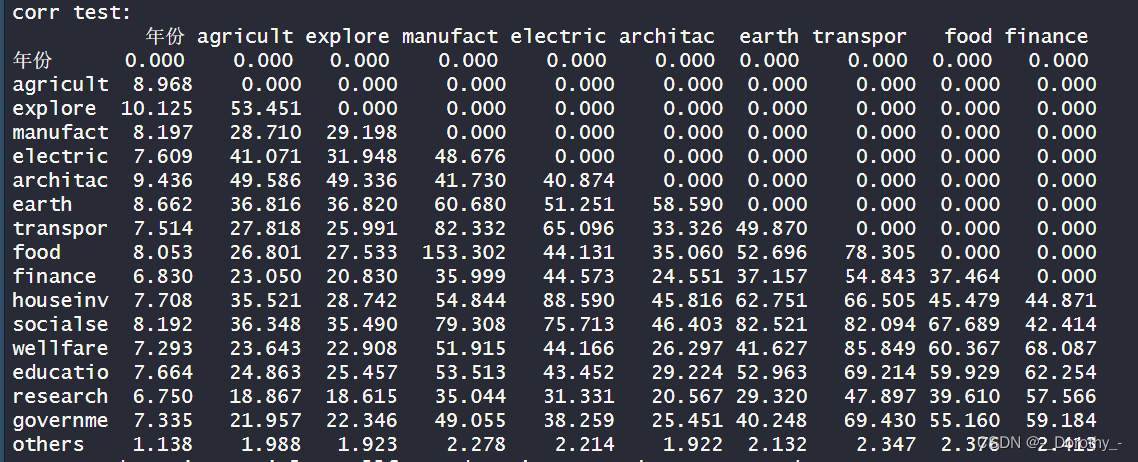
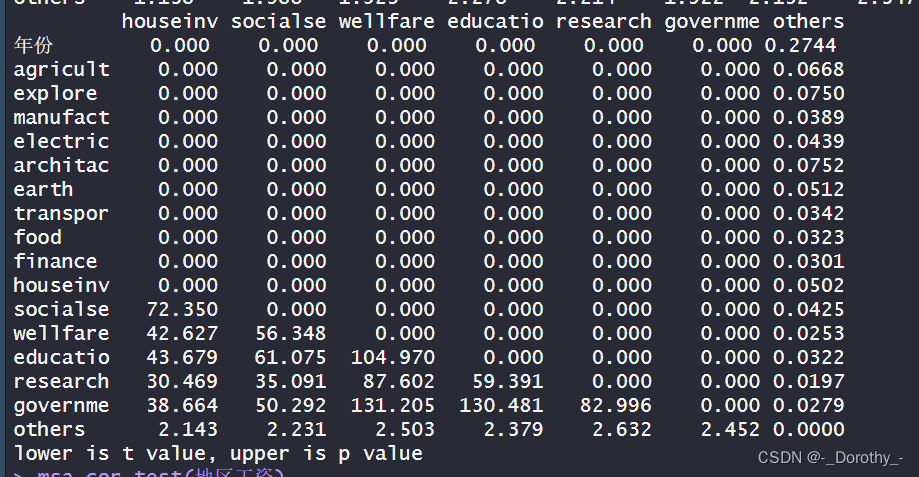
结论
1.相关性强度: .
●各行业之间的平均工资存在较强的正相关性。如,"agricult"和"explore’之间的相关系数为0.9976,“manufact"和"explore"之 间的相关系数0.9919。这表明这些行业之间的平均工资很可能随着时间的推移而同时增加或减少。
2.显著性检验:
●大多数行业之间的平均I资相关性都是显著的,这表明它们之间的关系不太可能是由于随机因素导致的。
●但是,对于一些行业(如"others”) ,相关性可能不太显著,因为值较小,p值较大。
3.相关性方向:
●大多数行业之间的相关性是正向的,即平均工资随着时间的推移而同时增加或减少。这可以通过相关系数为正值来确定。
综上所述,这些结果暗示着各行业之间的平均工资具有较强的正相关性,这可能是由于宏观经济因素市场趋势或政策变化等因素的影响。
地区工资
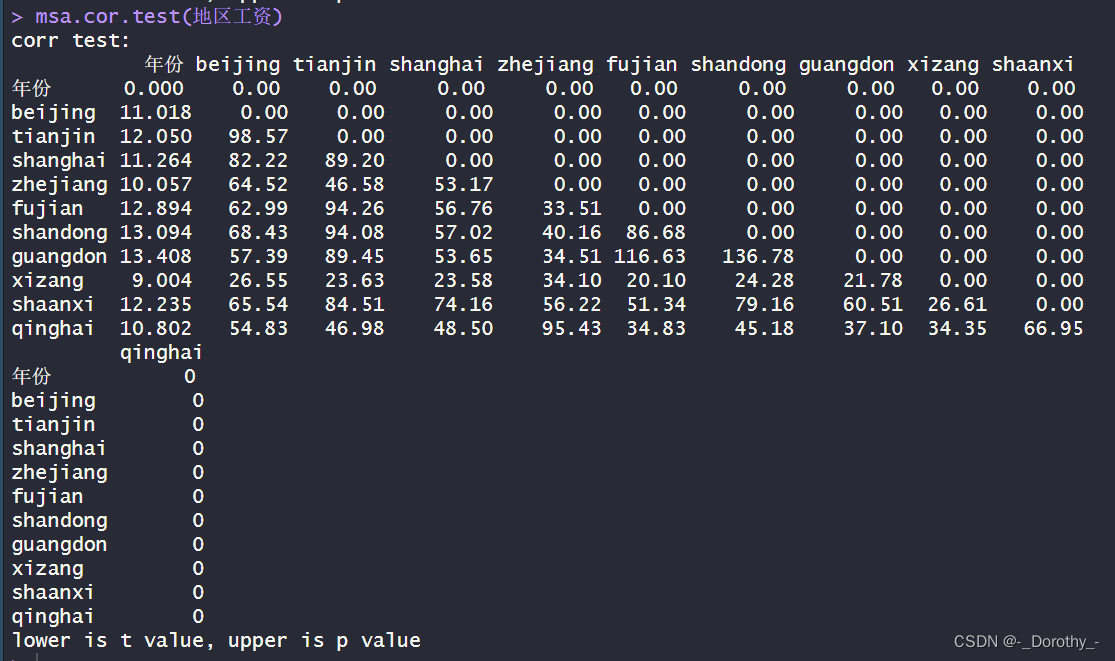
结论
1.相关性强度:
●各地区之间的平均工资存在较强的正相关性。例如,"beijing"和"tianjin"之间的相关系数为0.9992, “zhejang"和"shandong"之间的相关 系数为0.9951。这表明不同地区之间的平均工资很可能随着时间的推移而同时增加或减少。
2.显著性检验:
●大多数地区之间的平均工资相关性都是显著的,这表明它们之间的关系不太可能是由于随机因素导致的。
●但是,对于一些地区(如"xizang"和"qinghai”) ,相关性可能不太显著,因为t值较小,p值较大。
3.相关性方向:
●大多数地区之间的相关性是正向的,即平均工资随着时间的推移而同时增加或减少。这可以通过相关系数为正值来确定。
综上所述,这些结果暗示着各地区之间的平均工资具有较强的正相关性,这可能是由于宏观经济因素、地区发展水平、人口密度等因素的影响。
7、回归分析与检验
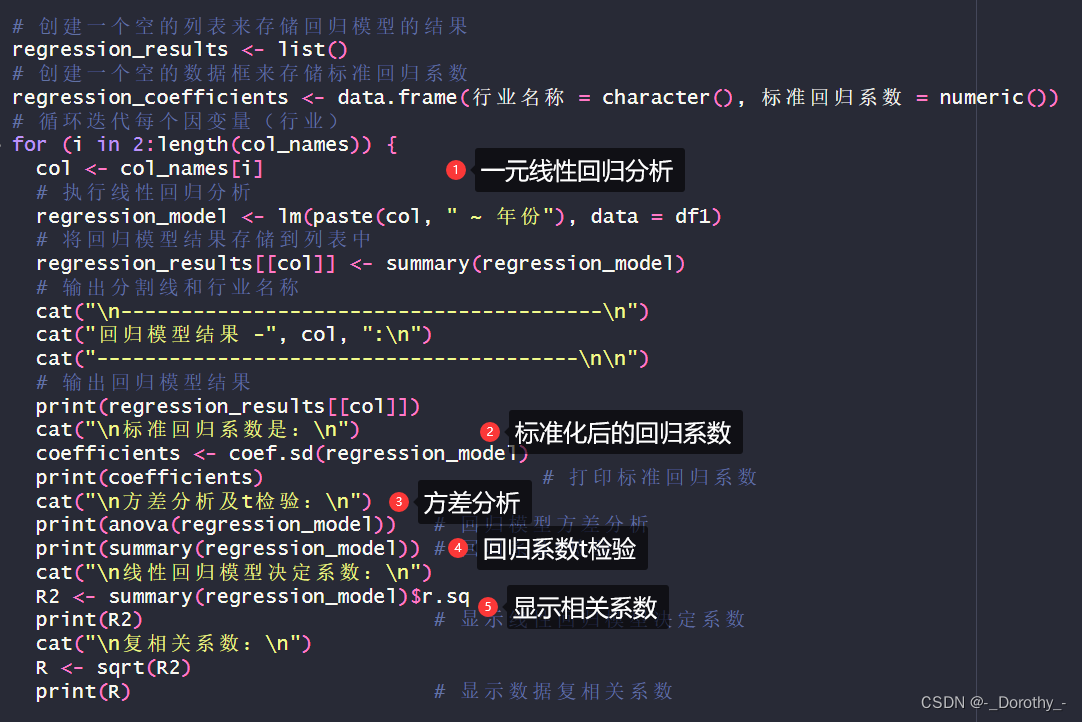
行业工资
(1)一元线性回归及显著性检验
代码分析
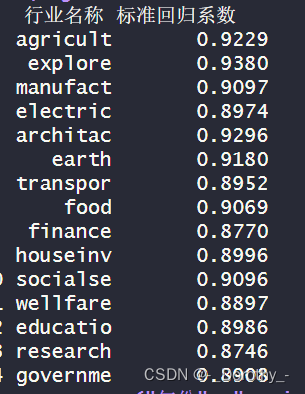
各行业的标准回归系数汇总对比
结果分析与结论——以government为例
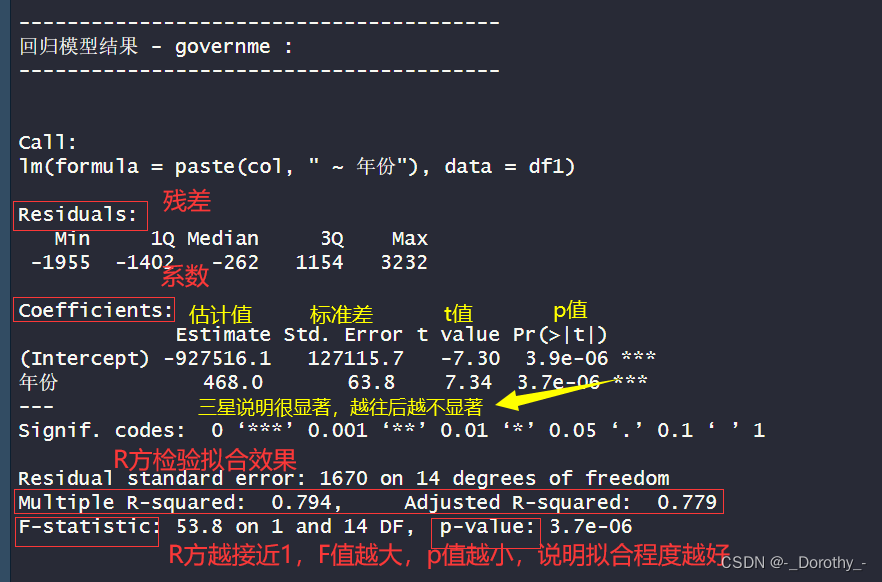
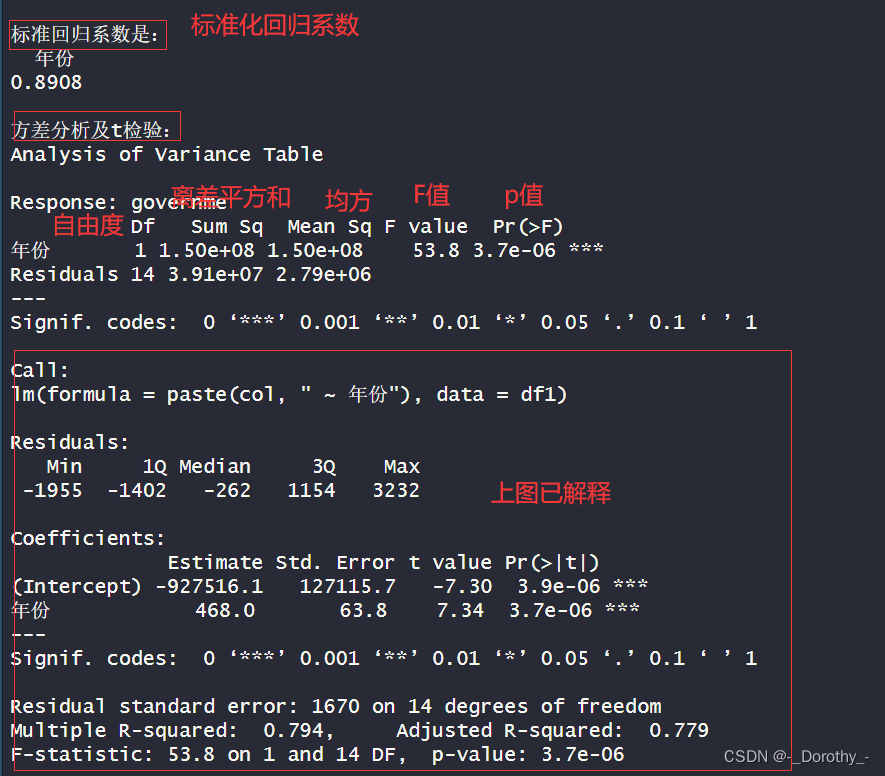

结论
1.方程:
●模型的回归方程是:政府部门]平均工资= -927516.1 + 468.0*年份。
●这意味着政府部门平均工资的截距为-927516.1,每年平均增加468.0。
2.拟合优度:
●模型的多重决定系数为0.7935,表示约79.35%的政府部门平均工资的变异性可以通过年份来解释。
●考虑到模型中的自变数量,调整后的决定系数为0.779,说明模型的拟合效果良好。
3.回归系数:
●年份的回归系数为0.8908,示每年政府部]平均工资的预期增加量。
●对于年份的回归系数进行的t检验显示,这个系数是显著的(p值为3.7e-06) , 表明年份对政府部门平均工资的影响是显著的。
4.方差分析:
●方差分析表明年份对政府部门平均工资的影响是显著的(p值为3.7e-06) 。
综上所述,该模型表明政府部门平均工资随着时间的推移呈上升趋势,且时间对政府部门]平均工资的影响是显著的。
剩余十五个结果结构同上,不再赘述
(2)回归结果可视化
散点图代表真实值,线条表示回归方程
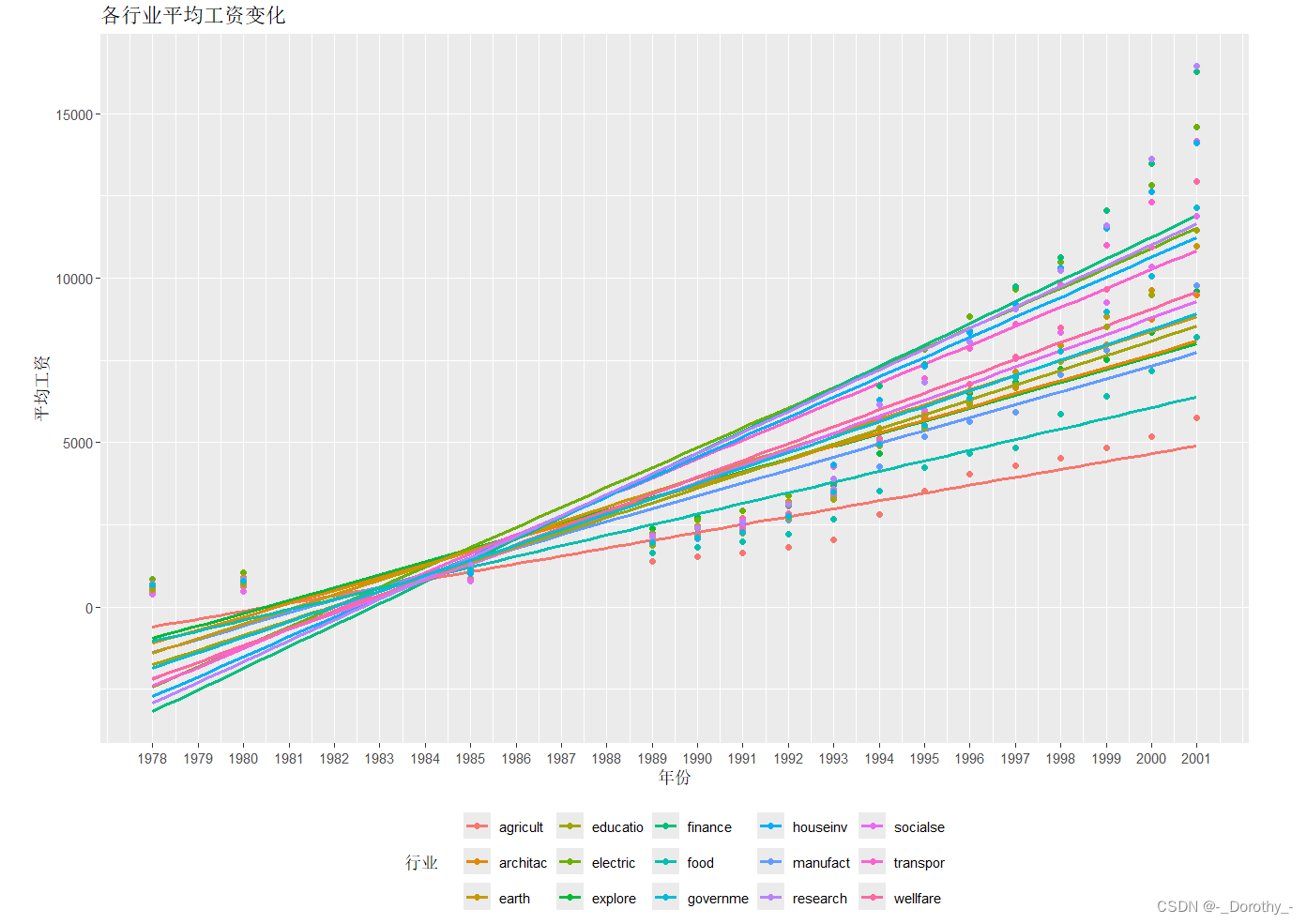
从图中不难发现这并不是一个理想的模型
(3)改进——三次多项式回归及显著性检验
代码结构同上
各行业的标准回归系数汇总对比
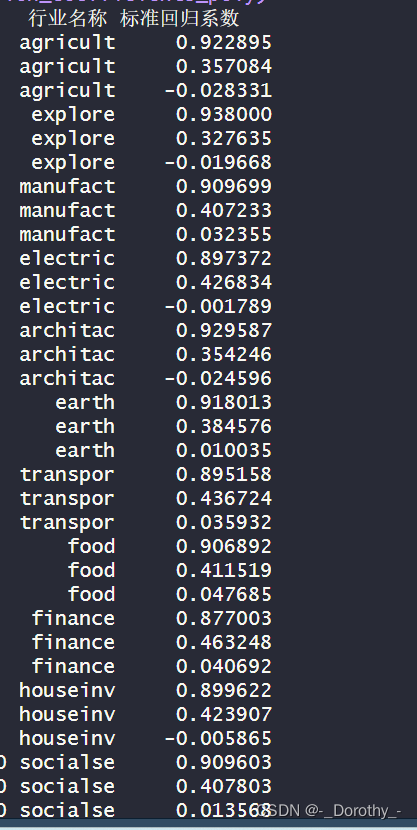
结果分析与结论——以government为例
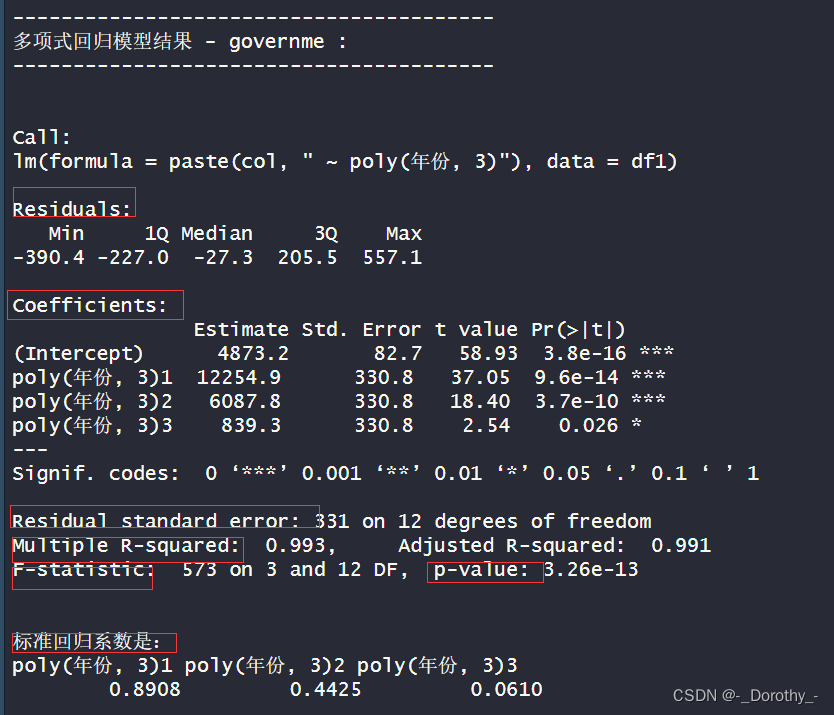
1.回归方程:
●模型的回归方程是:政府部门平均工资= 4873.2 + 12254.9年份- 6087.8年份^2 + 839.3*年份^3。
●这个方程包含了年份的三次多项式,因此可以更灵活地拟合数据。
2.拟合优度:
●模型的多重决定系数为0.993,表示约99.3%的政府部i ]平均工资的变异性可以通过这个多项式模
型来解释。
●调整后的决定系数为0.991,说明模型的拟合效果非常好。
3.回归系数: .
●poly(年份, 3)1对应的回归系数为0.8908,表示政府部门]平均工资随时间的增加量。
●poly(年份, 3)2对应的回归系数为0.4425,表示政府部门]平均工资随时间的增加速度的变化。
●poly(年份, 3)3对应的回归系数为0.0610,表示政府部门]平均工资随时间增加速度的变化率的变化
率。
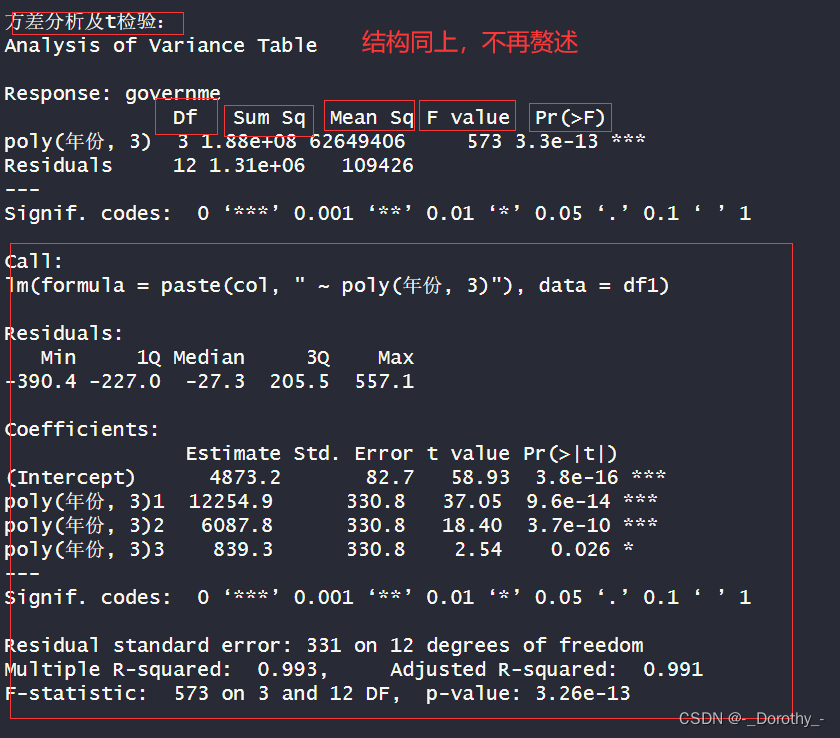
4.方差分析: .
●F-statistic为573, p-value为3.26e-13, 表明模型的回归方程显著。
综上所述,这个多项式回归模型说明政府部门]平均工资随着时间的推移呈现出非线性的变化趋势,且模型的拟合效果非常好,可以很好地解释数据的变化。
(4)改进后的回归结果可视化
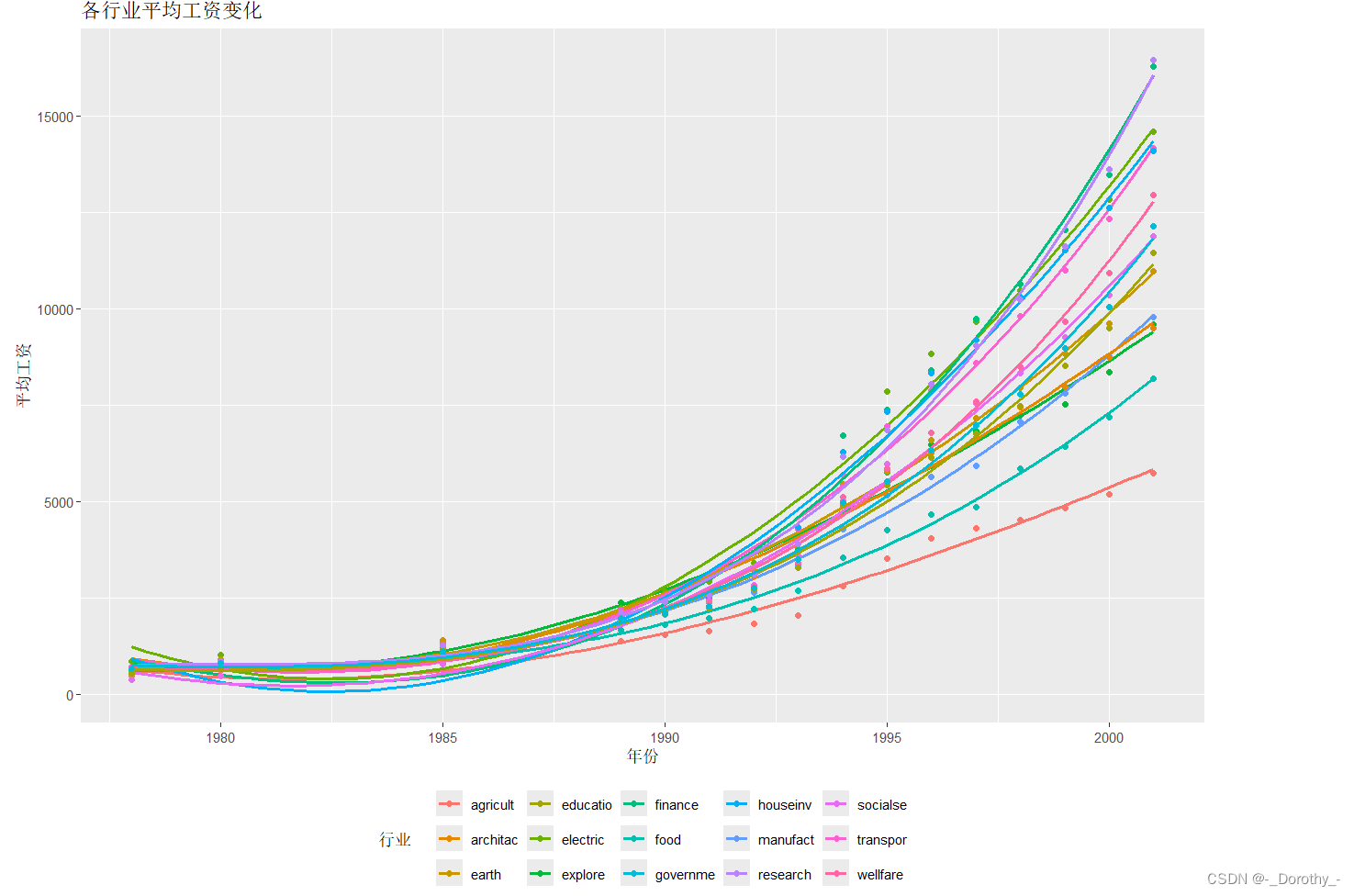
明显拟合效果提高
地区工资
(1)一元线性回归及显著性检验
代码结构同上不再赘述
各地区的标准回归系数汇总对比
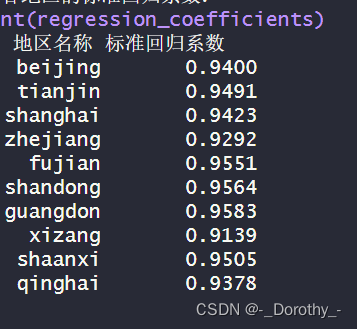
结果分析与结论
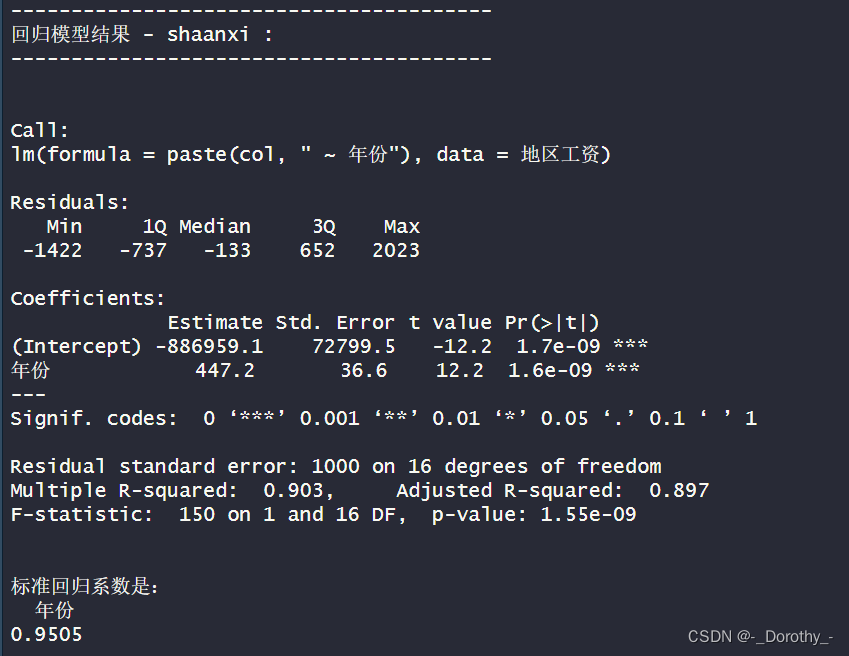
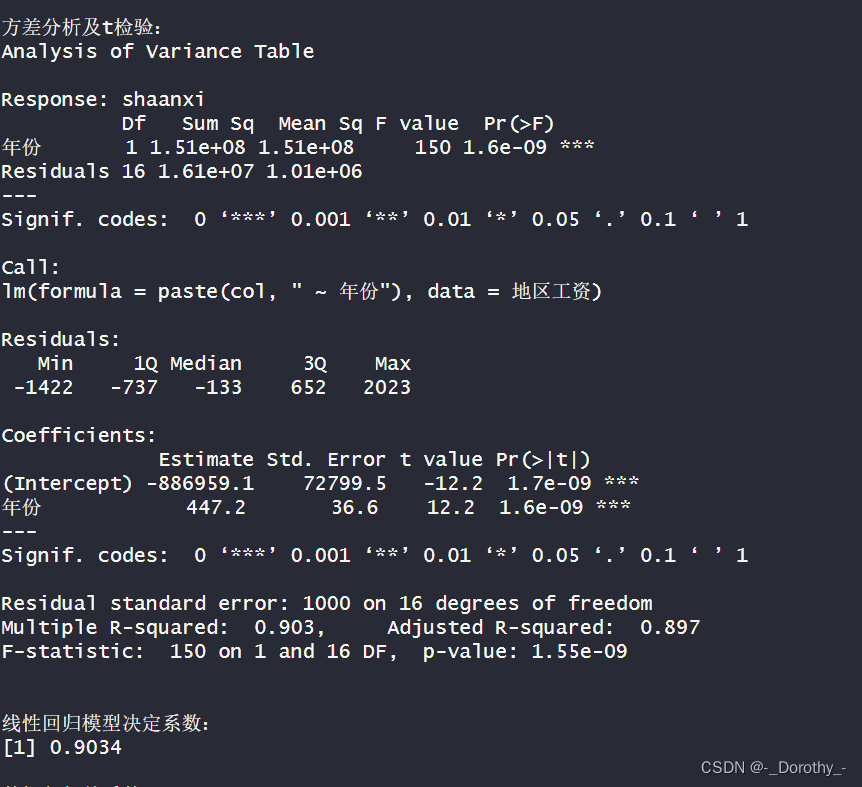
结论
1.回归方程:
●模型的回归方程是:地区平均工资= -886959.1 + 447.2★年份。
●这个方程表示地区平均工资随着年份的增加而增加,斜率为447.2, 表示每年平均工资增加447.2单
位。
2.拟合优度:
●模型的决定系数为0.903,表示约90.3%的地区平均工资的变异性可以通过这个线性模型来解释。
●调整后的决定系数为0.897,说明模型的拟合效果较好。
3.归系数:
●年份的回归系数为0.9505,表示地区平均工资随时间的增加量。
4.差分析:
●F-statistic为150, p-value为1.55e-09, 表明模型的回归方程显著。
5.复相关系数:
●数据的复相关系数为0.9505,表示年份与地区平均工资之间存在着强相关性。
综上所述,这个线性回归模型说明不同地区平均工资随着时间的推移呈现出线性增长的趋势,且模型的
拟合效果良好,可以很好地解释数据的变化。
(2)回归结果可视化
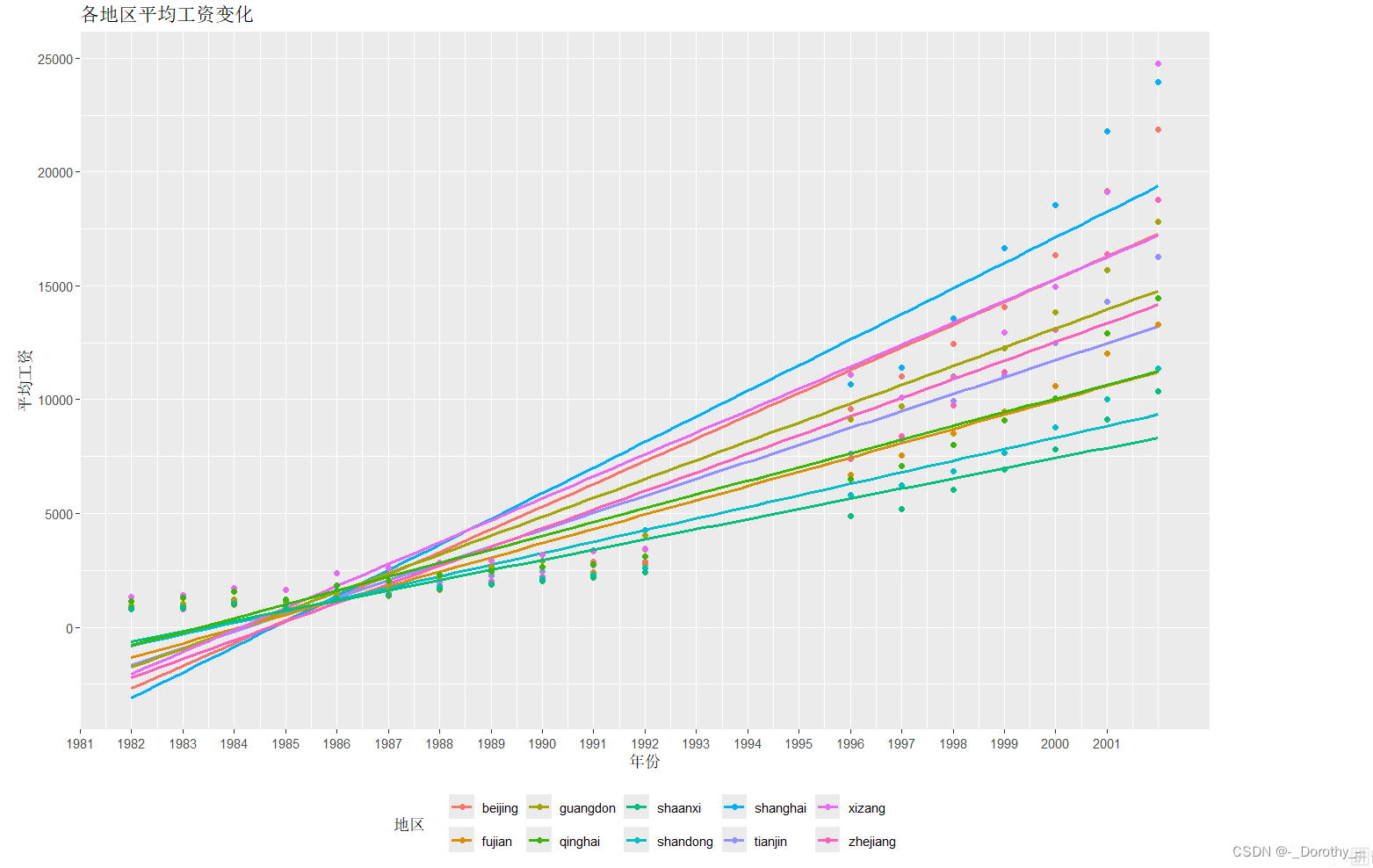
(3)改进——三次多项式回归
各地区的标准回归系数汇总对比
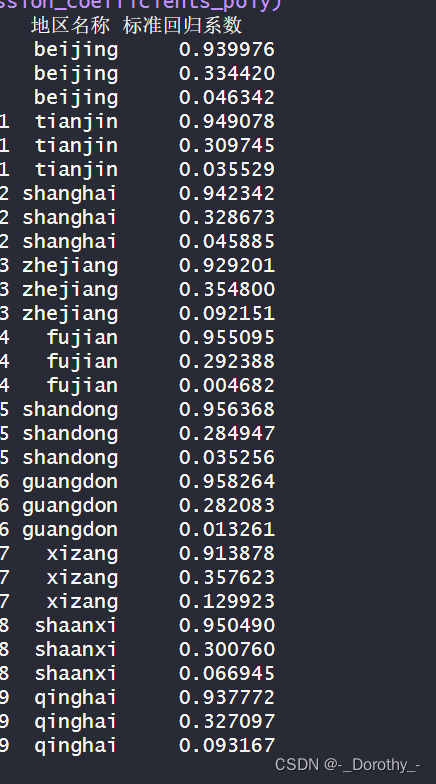
结果分析与结论
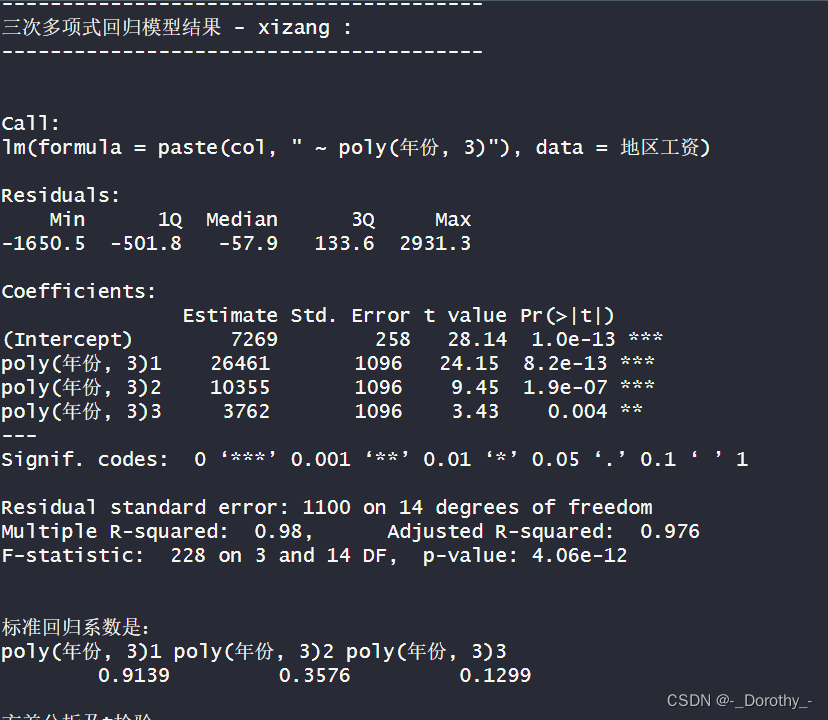
结论
1.回归方程:
●模型的回归方程是:西藏地区平均工资= 7269 + 26461年份+ 10355年份^2 + 3762*年份^3。
●这个方程表示西藏地区平均工资随着年份的增加而增加,且呈现出三次多项式的形式。
2.拟合优度:
●模型的决定系数为0.9799,表示约98.0%的西藏地区平均工资的变异性可以通过这个三次多项式模型来解释。
●调整后的决定系数为0.976,说明模型的拟合效果较好。
3.回归系数:
●模型中年份的各次项的回归系数为:
●年份: 0.9139
●年份^2: 0.3576
●年份^3:0.1299
●这些系数表示了年份与西藏地区平均工资之间的关系,以及年份的各次方对平均工资的影响。
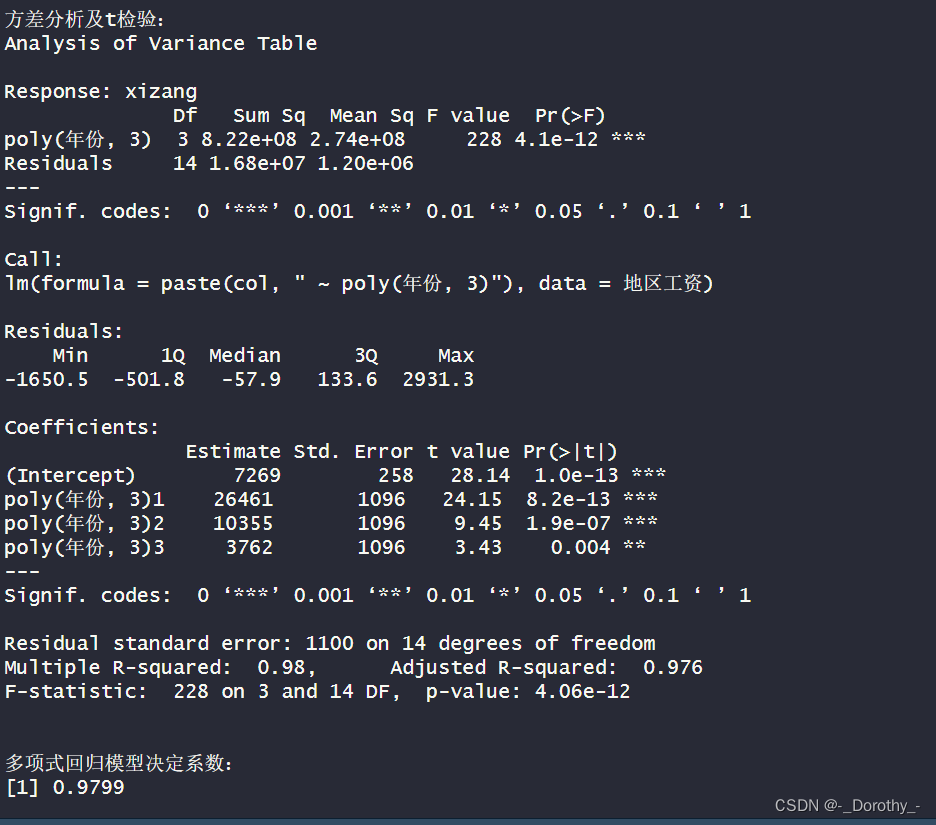
4.方差分析:
●F-statistic为228, p-value为4.06e-12, 表明模型的回归方程显著。
5.复相关系数:
●模型的多项式数据复相关系数为0.9899,表示年份与西藏地区平均工资之间存在着强相关性。
综上所述,这个三次多项式回归模型说明西藏地区平均工资随着时间的推移呈现出一种复杂的非线性变化趋势,并且模型的拟合效果良好,可以很好地解释数据的变化。
(4)改进后的回归结果可视化
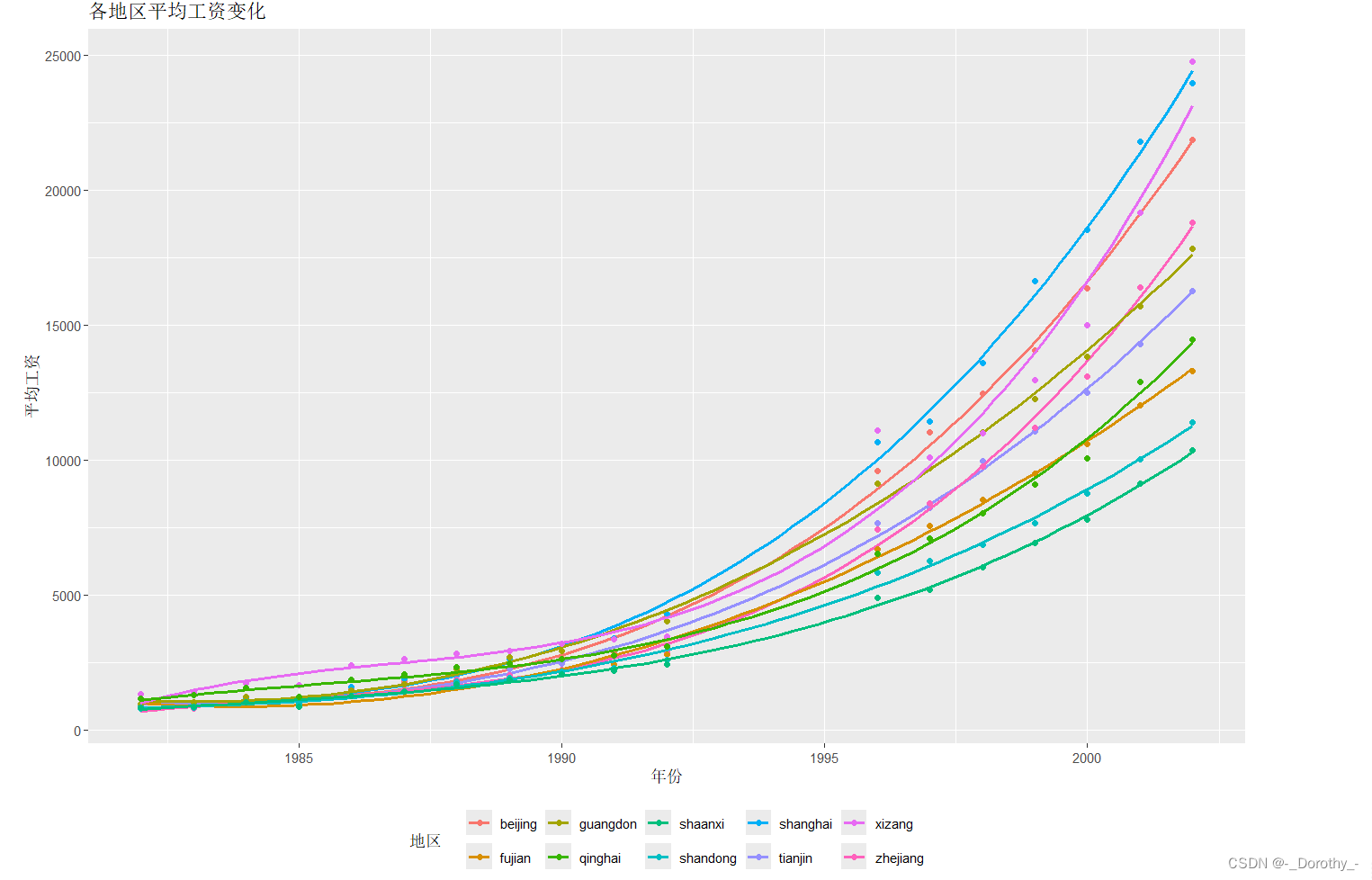
这篇关于R语言实战——中国职工平均工资的变化分析——相关与回归分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





