本文主要是介绍Delta lake with Java--使用stream同步数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天继续学习Delta lake Up and Running 的第8章,处理流数据,要实现的效果就是在一个delta表(名为:YellowTaxiStreamSource)插入一条数据,然后通过流的方式能同步到另外一个delta表 (名为:YellowTaxiStreamTarget)。接着在YellowTaxiStreamSource更新数据YellowTaxiStreamTarget也能更新。至于删除也尝试过了,发现删除是没有办法同步的。
一、先上代码,今天的代码分3份
第1份:用来启动流
import io.delta.tables.DeltaTable;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.streaming.StreamingQueryException;public class DeltaLakeStream {public static void main(String[] args) {SparkSession spark = SparkSession.builder().master("local[*]").appName("delta_lake").config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension").config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog").getOrCreate();String targetPath="D:\\bigdata\\detla-lake-with-java\\YellowTaxiStreamTarget";spark.sql("CREATE DATABASE IF NOT EXISTS taxidb");//定义源数据表spark.sql("CREATE TABLE IF NOT EXISTS taxidb.YellowTaxiSource(" +"RideID INT," +"PickupTime TIMESTAMP," +"CabNumber STRING)" +"USING DELTA LOCATION 'file:///D:\\\\bigdata\\\\detla-lake-with-java\\\\YellowTaxiStreamSource'");//定义目标数据表spark.sql("CREATE TABLE IF NOT EXISTS taxidb.YellowTaxiTarget(" +"RideID INT," +"PickupTime TIMESTAMP," +"CabNumber STRING)" +"USING DELTA LOCATION 'file:///D:\\\\bigdata\\\\detla-lake-with-java\\\\YellowTaxiStreamTarget'");//通过流的方式读取元数据表,记得要option("ignoreChanges", "true")否则报错var stream_df=spark.readStream().option("ignoreChanges", "true").format("delta").load("file:///D:\\\\bigdata\\\\detla-lake-with-java\\\\YellowTaxiStreamSource");//打开目标表,用于后面同步数据var deltaTable = DeltaTable.forPath(spark, targetPath);// var streamQuery=stream_df.writeStream().format("delta").option("checkpointLocation", targetPath+"\\_checkpoint").start(targetPath);//定义同步流,如果目标表的记录与更新记录的RideID相等则更新,没有找到则插入新记录var streamQuery=stream_df.writeStream().format("delta").foreachBatch((batchDf,batchId)->{deltaTable.as("t").merge(batchDf.as("s"),"t.RideID==s.RideID").whenMatched().updateAll().whenNotMatched().insertAll().execute();}).outputMode("Update").start(targetPath);try {System.out.println("启动stream监听");streamQuery.awaitTermination(); //启动流} catch (StreamingQueryException e) {throw new RuntimeException(e);}}
}
第2份:用来操作源数据表
import org.apache.spark.sql.SparkSession;public class DeltaLakeStreamSource {public static void main(String[] args) {SparkSession spark = SparkSession.builder().master("local[*]").appName("delta_lake").config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension").config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog").getOrCreate();spark.sql("CREATE DATABASE IF NOT EXISTS taxidb");spark.sql("CREATE TABLE IF NOT EXISTS taxidb.YellowTaxiSource(" +"RideID INT," +"PickupTime TIMESTAMP," +"CabNumber STRING)" +"USING DELTA LOCATION 'file:///D:\\\\bigdata\\\\detla-lake-with-java\\\\YellowTaxiStreamSource'");//验证插入spark.sql("INSERT INTO taxidb.YellowTaxiSource (RideID,PickupTime,CabNumber) values (1,'2013-10-13 10:13:15','11-96')").show(false);//验证更新 //spark.sql("UPDATE taxidb.YellowTaxiSource SET CabNumber='199-99' WHERE RideID=1").show(false);//验证删除,不过无效 //spark.sql("DELETE FROM taxidb.YellowTaxiSource WHERE RideID=1").show(false);spark.sql("SELECT RideID,PickupTime,CabNumber FROM taxidb.YellowTaxiSource").show(false);spark.close();}
}第3份:用来验证目标数据表的同步结果
import org.apache.spark.sql.SparkSession;public class DeltaLakeStreamTarget {public static void main(String[] args) {SparkSession spark = SparkSession.builder().master("local[*]").appName("delta_lake").config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension").config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog").getOrCreate();String targetPath="D:\\bigdata\\detla-lake-with-java\\YellowTaxiStreamTarget";spark.read().format("delta").load(targetPath).show();}
}二、运行验证
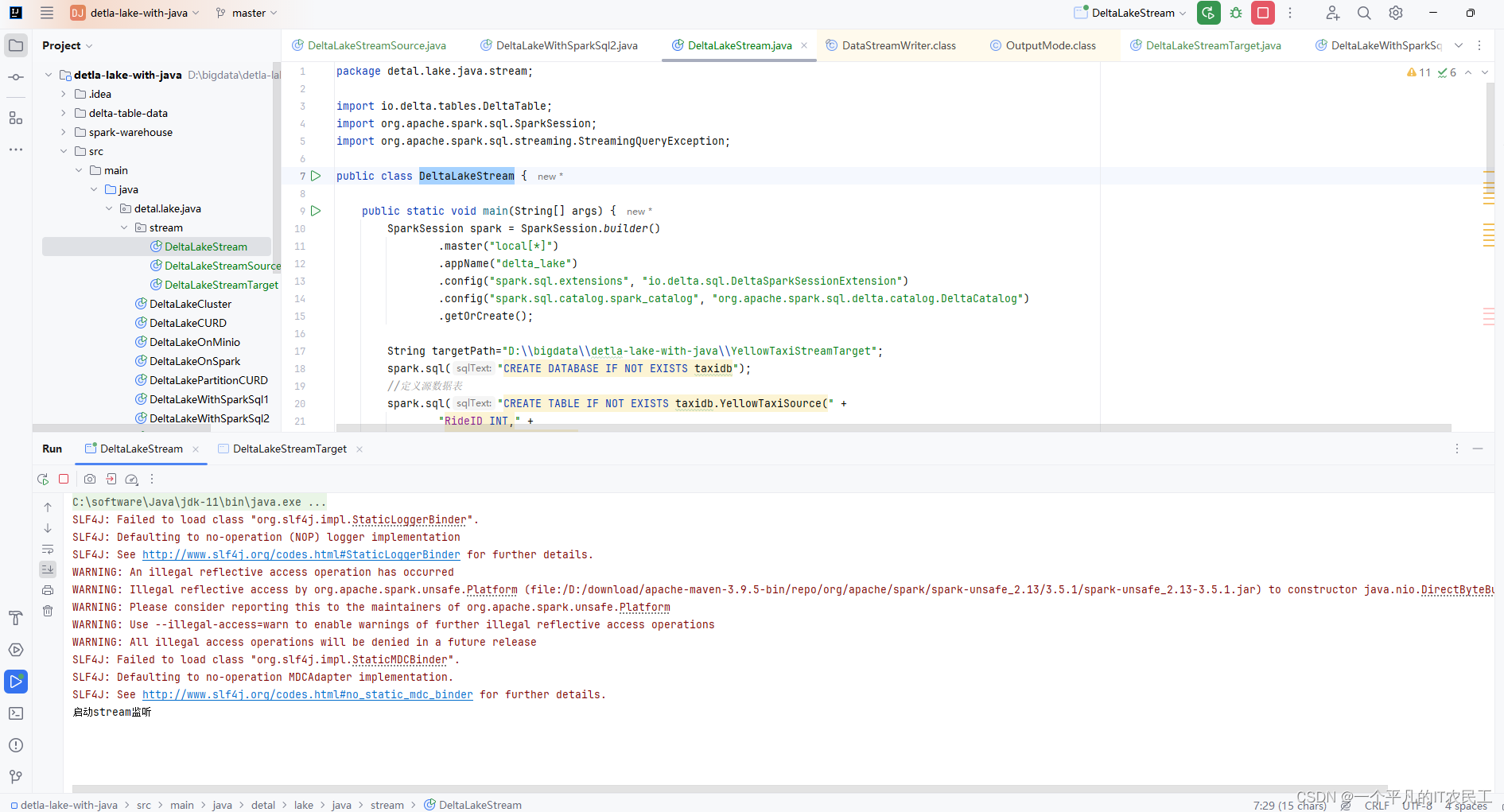
1、先运行DeltaLakeStream,具体运行结果如下图:
2、验证插入数据同步
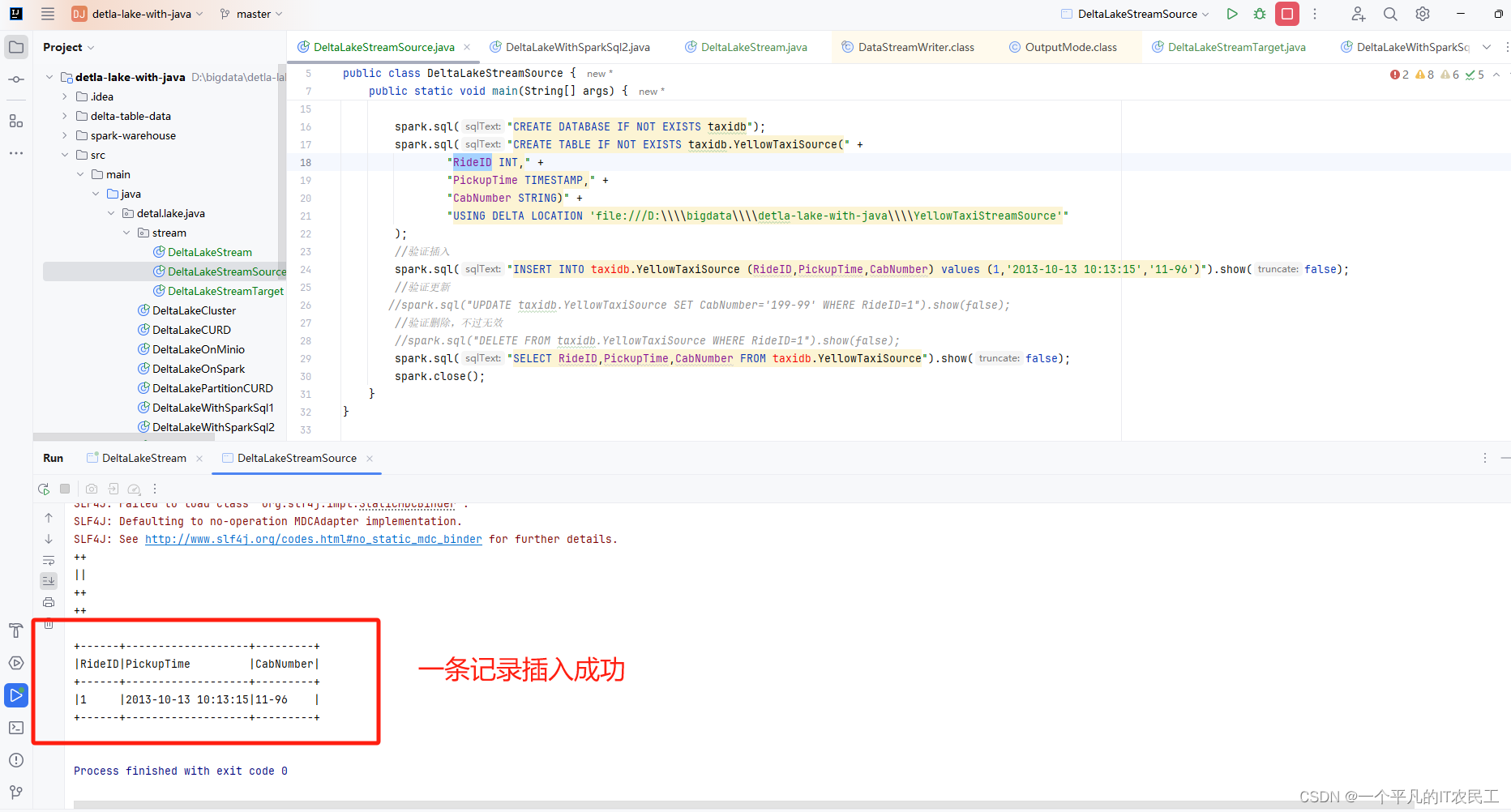
运行DeltaLakeStreamSource,插入一条RideID=1的数据,具体运行结果如下图:
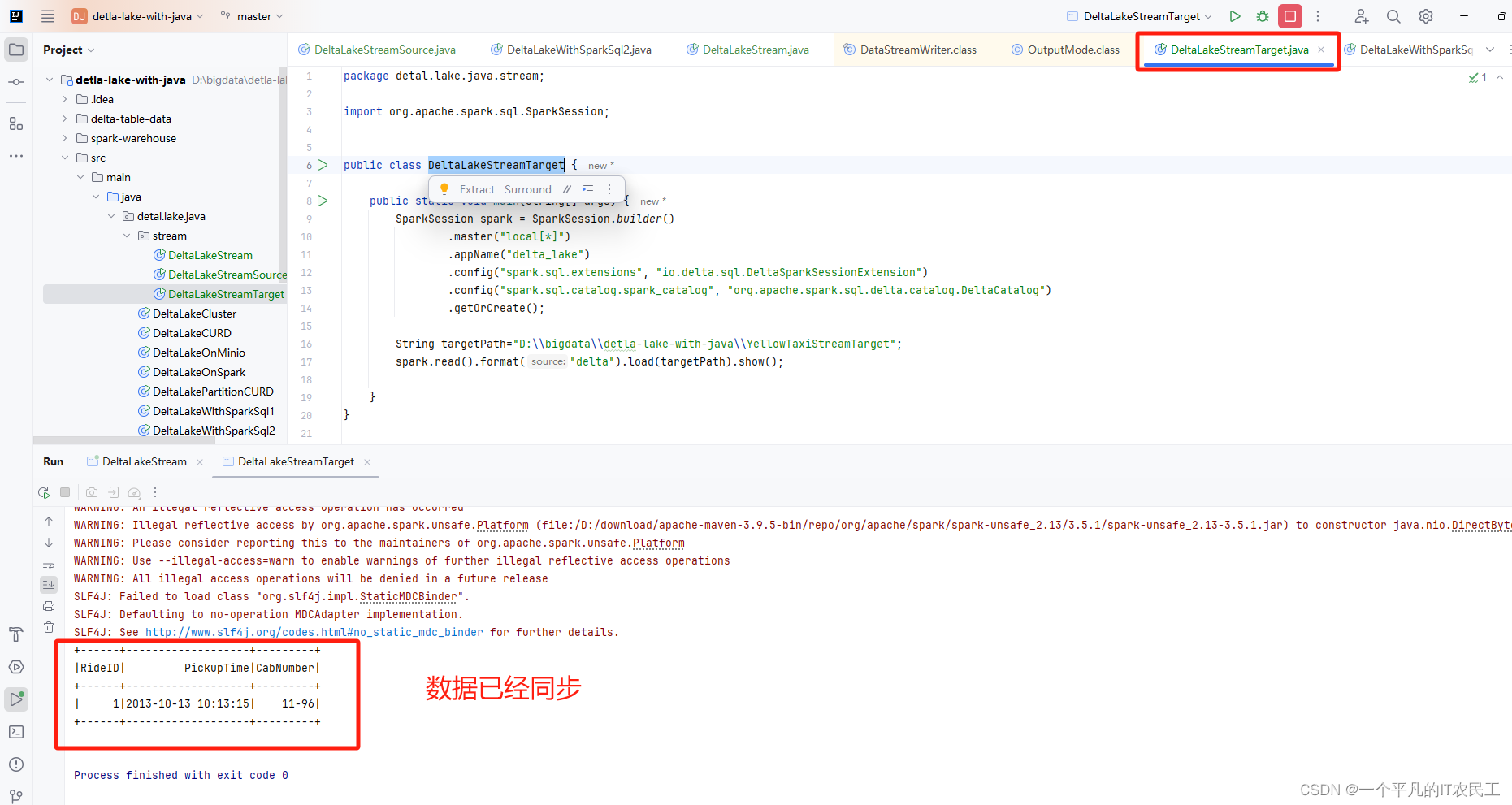
接着运行 DeltaLakeStreamTarget,看一下数据是否已经通过流的方式同步到目标表,具体运行结果如下图:
3、验证更新数据同步
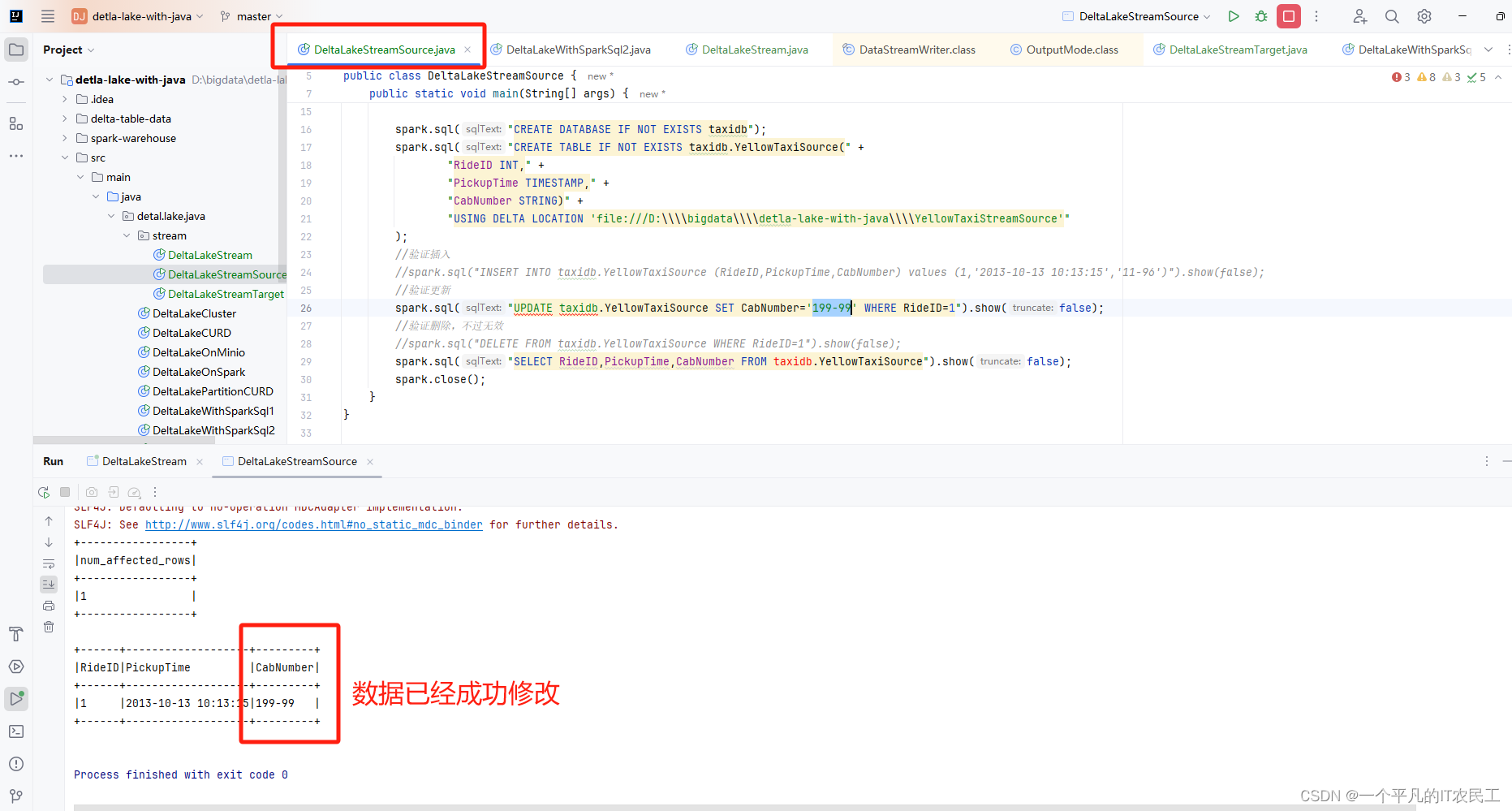
将DeltaLakeStreamSource的插入数据代码注释掉,同时将更新代码打开,然后运行,将RideID=1的记录的CabNumber值得从11-96修改成199-99,具体运行结果如下图:
接着运行 DeltaLakeStreamTarget,看一下数据是否已经通过流的方式同步到目标表,具体运行结果如下图:
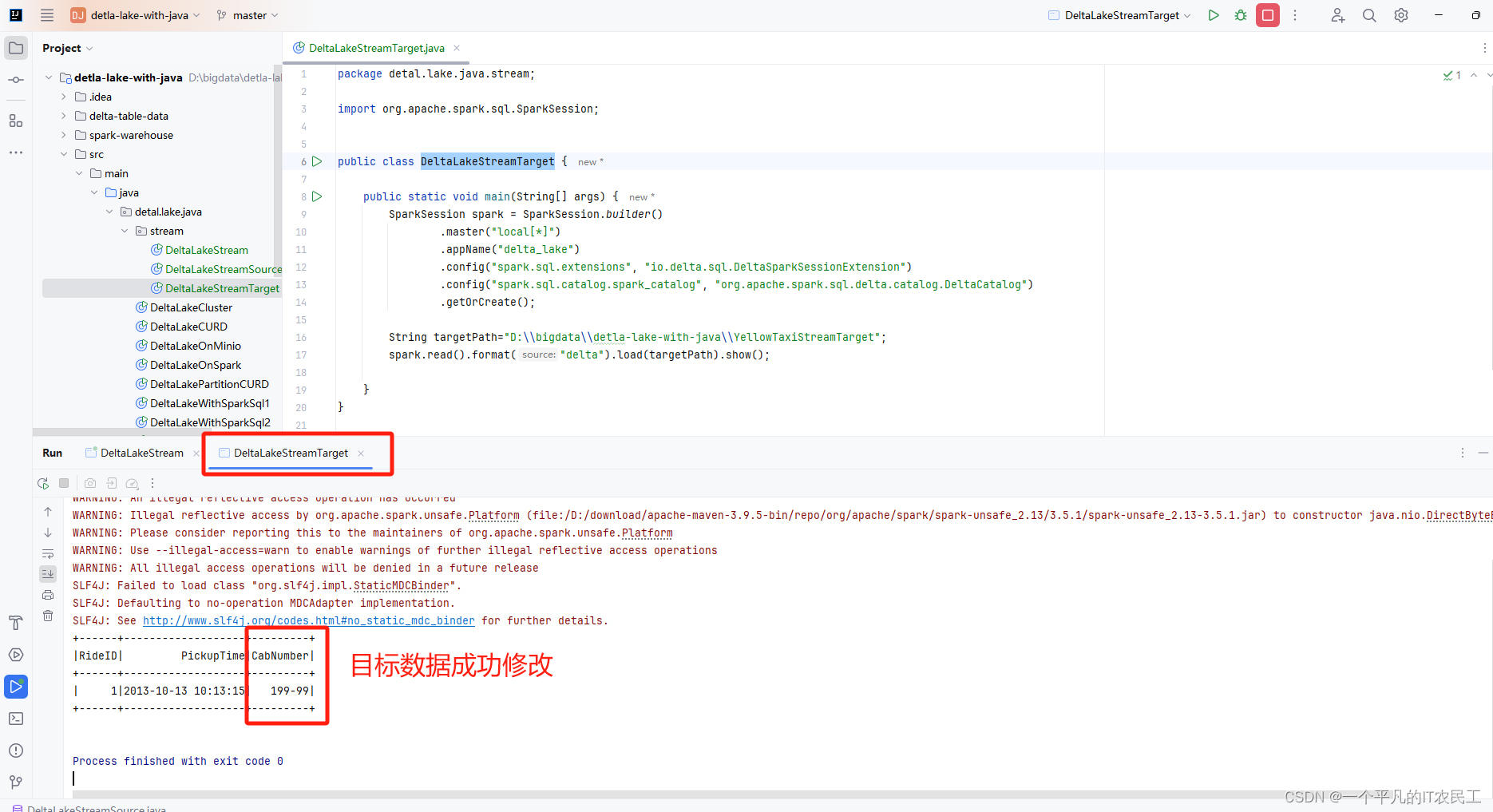
至于删除也尝试过,没有成功,不知道是不是不支持,还望高手指教。
这篇关于Delta lake with Java--使用stream同步数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






