本文主要是介绍1.pytorch加载收数据(B站小土堆),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据的加载主要有两个函数:
1.dataset整体收集数据:提供一种方法去获取数据及其label,告诉我们一共有多少数据(就是自开始把要的数据和标签都收进来)
2.dataloader,后面传入模型时候,每次录入数据的方法
※想使用这两个函数,要引入pytorch库,并且从torch“工具箱”utils的data模块中拿出函数
import pytorch
from torch.utils.data import Dataset,DataLoader#其他下面要用的
from PIL import Image
import os #os.path.join(A,B); os.listdir(转换成列表的文件夹)Dataset
1.官网解释:
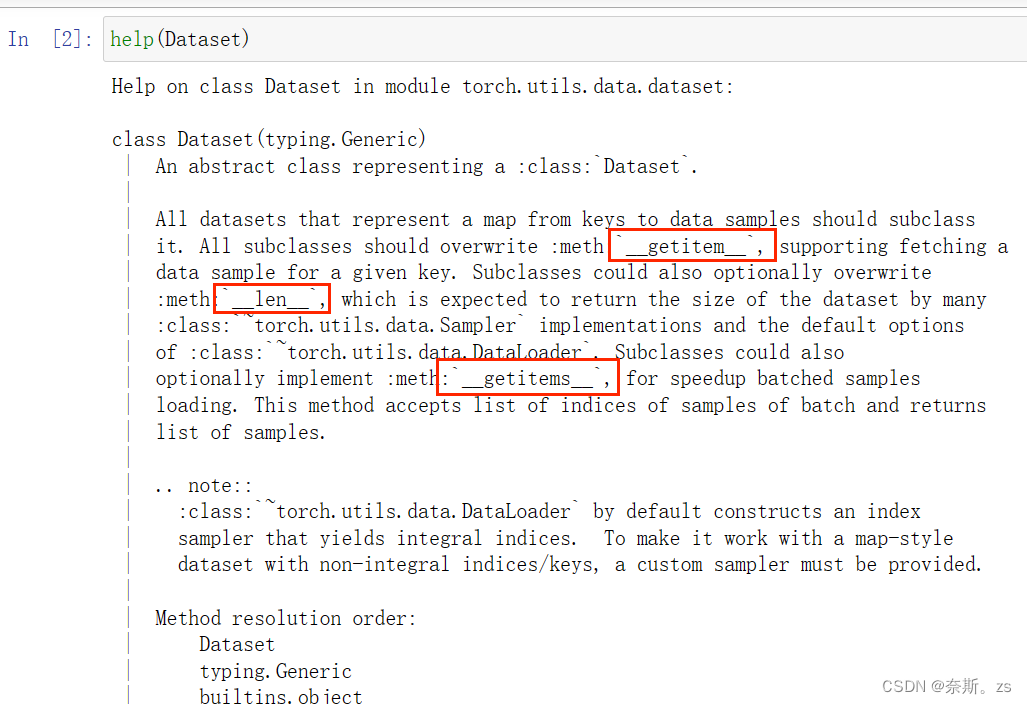
2.准备工作/相关工作解释:
1.安装opencv
(注意要安装opencv,怎么安装?)
无论是opencv还是tensorflow啥的,都要先进入虚拟化环境
(anconda创建虚拟环境:conda create --name ×× python=3.8)
(激活、进入环境:conda activate ××)
安装opencv:conda install ××(这里是opencv-python)
注:什么是opencv,opencv和pillow(PIL):
OpenCV(Open Source Computer Vision Library)和 PIL(Python Imaging Library)都是用于图像处理和计算机视觉任务的库(本质上是同级的关系,但是opencv适用于更复杂的图像处理),但它们有一些区别和各自的优势:
-
功能特点:
- PIL 主要专注于基本的图像处理任务,如图像加载、保存、调整大小、旋转、裁剪等,以及一些简单的滤波和颜色空间转换。
- OpenCV 不仅提供了图像处理功能,还提供了更多复杂的计算机视觉算法,如特征检测、目标识别、摄像头捕获、视频处理等。
-
性能:
- OpenCV 通常在处理大型图像和实时视频时表现更优,因为它经过了高度优化,采用了底层优化的C/C++代码实现,并且支持多线程处理。
- PIL 在一些简单的图像处理任务上可能更轻量级和简单,但对于复杂的任务和大规模数据处理,性能可能不如 OpenCV。
-
语法和接口:
- PIL 的语法相对简单易懂,适合初学者和快速开发。
- OpenCV 的 API 更庞大和复杂,但也更灵活,可以进行更多种类的图像处理和计算机视觉任务。
-
应用场景:
- 如果只需要进行简单的图像处理,如调整大小、转换格式等,而且希望代码简单易懂,可以选择使用 PIL。
- 如果需要进行复杂的计算机视觉任务,如目标检测、特征提取、实时视频处理等,或者需要高性能和灵活性,可以选择使用 OpenCV。
2.对图片的操作——PIL库的image模块(控制台写代码就是一步一步的看运行的效果,在总面板上就是写完整个完整代码,然后看运行结果)
1.为方便,将图片文件引入改代码文件夹(文件夹 直接操作即可)
2.在控制台中引入pillow库(PIL)中的Image模块 。“from PIL import Image”
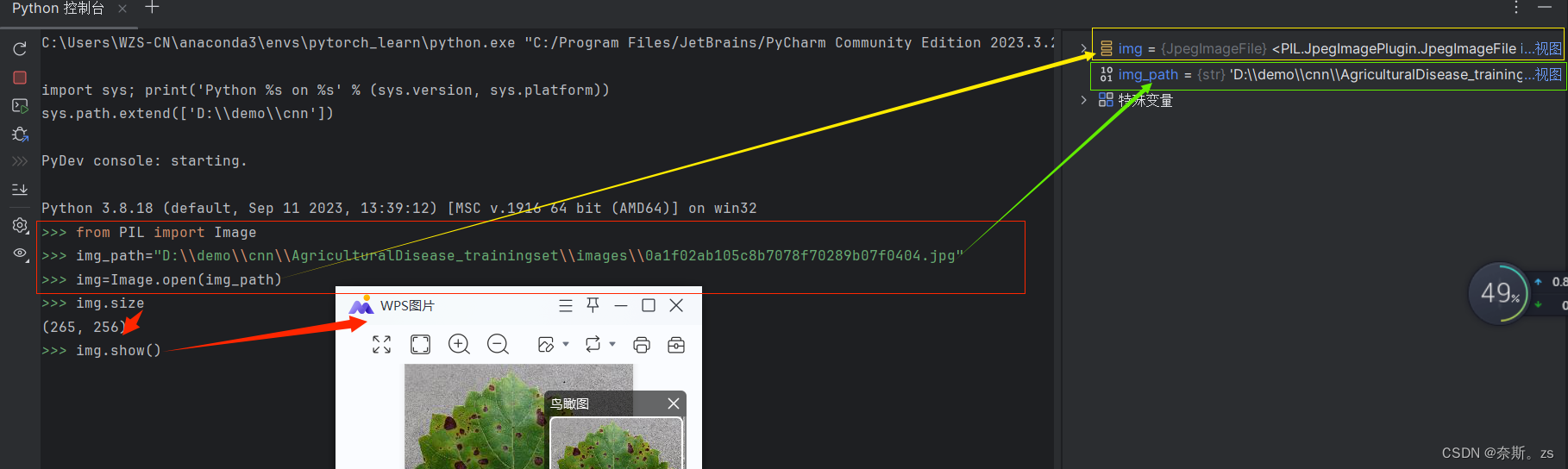
3.写入图片路径,用变量"img_path"接收,注意路径的写法: 如:“ img_path="D:\\demo\\images\\0.jpg" ”
复制后写入控制台,然后将单斜杠“\”都写成“\\”
4.打开此路径 “img=Image.open(img_path)”
5.对图片进行相应的操作,如img.size ;img.show()等


▨这个PIL库很常用到,基本上涉及图片就会引入
并且,这个库中的open函数与是常用的
from PIL import Image`````` path=“xx/xx/xx.jpg”img=Image.open(path)`````▨绝对地址要改双杠,相对地址直接单杠
3.将图片名称写成列表(总体获取图片名称)
1.引入os库:import os
2.写入图片文件夹地址
(这里不用变双斜杠)root="D:\demo..."
3.用os中的listdir将该文件夹下的路径都变为列表形式 img_list=os.listdir(root)
4.直接用用列表名查看对应的名称即可 img_list[0]

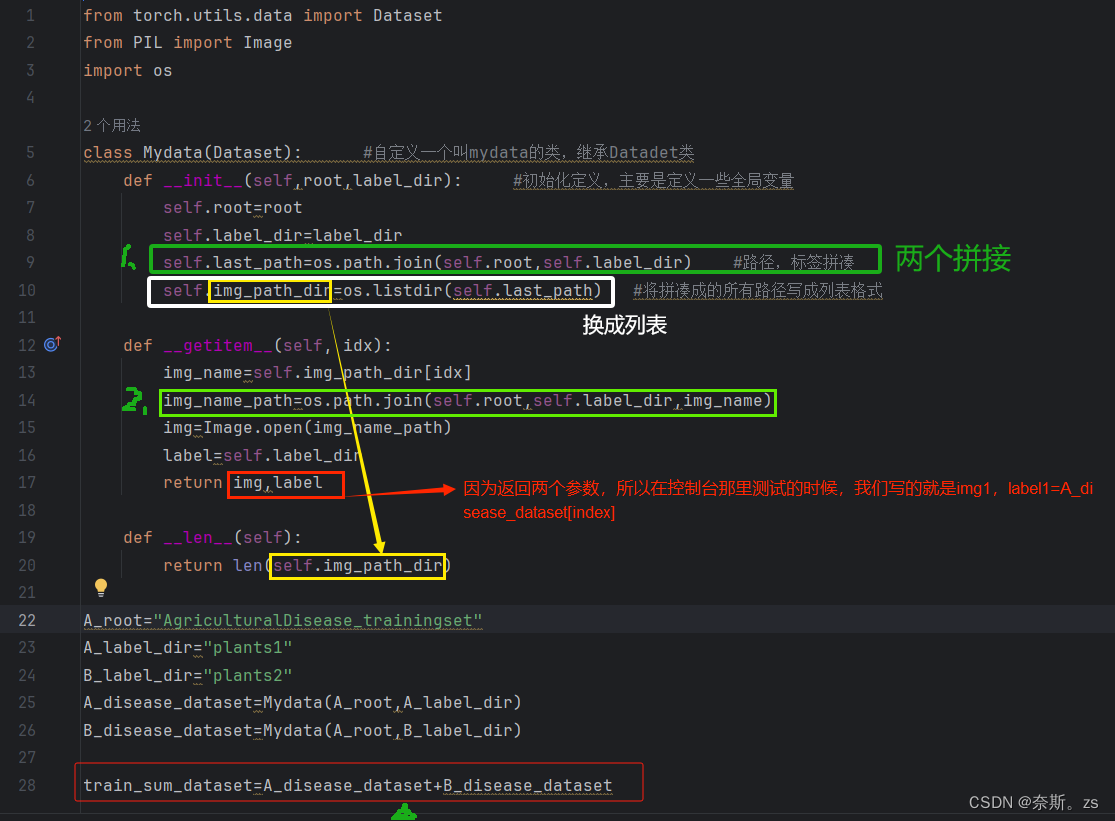
4.将路径和“标签”进行拼接 ——os.path.join(A,B)
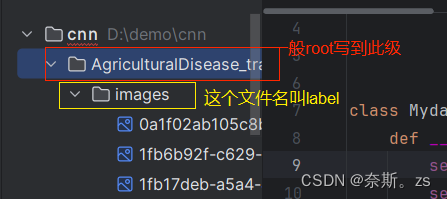
1.写入标签 img_label="plant diseases"(不过一般这里是所存在的文件夹名称,因为后序很可能用到相应的操作,如果单纯随意出来的一个名称,后序可能无法执行)
2.拼接(注意,拼接的是标签和文件夹,不是上面图片路径的列表) lastpath=os.path.join(root,img_label)
常见的写法是:root=“D:\demo\cnn\AgriculturalDisease_trainingset”或者用
label_dir=“image”
例2:拼接出具体图片地址用列表w)


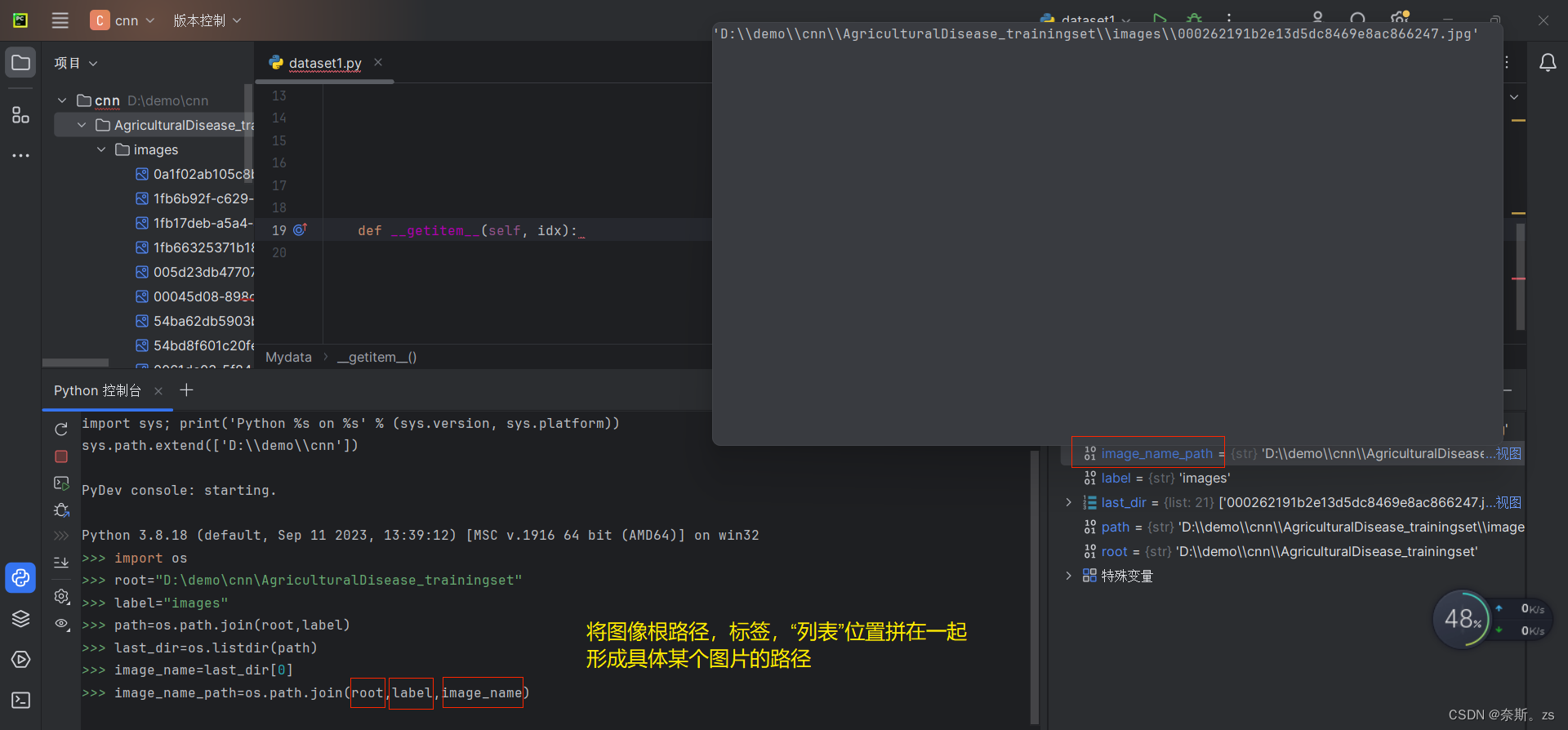
3.整个dataset函数:
总训练集可以直接用+来拼接,但是使用加号的的前提是,在mydataset函数中正确写入——len——函数,注意这个len函数是图像列表的长度,不是某一图像名称的长度
控制台看效果:
具体实例化:





其他:
1.打开jupyter notebook的方法:
(base) PS C:\Users\WZS-CN> conda activate pytorch_learn
(pytorch_learn) PS C:\Users\WZS-CN> jupyter notebook
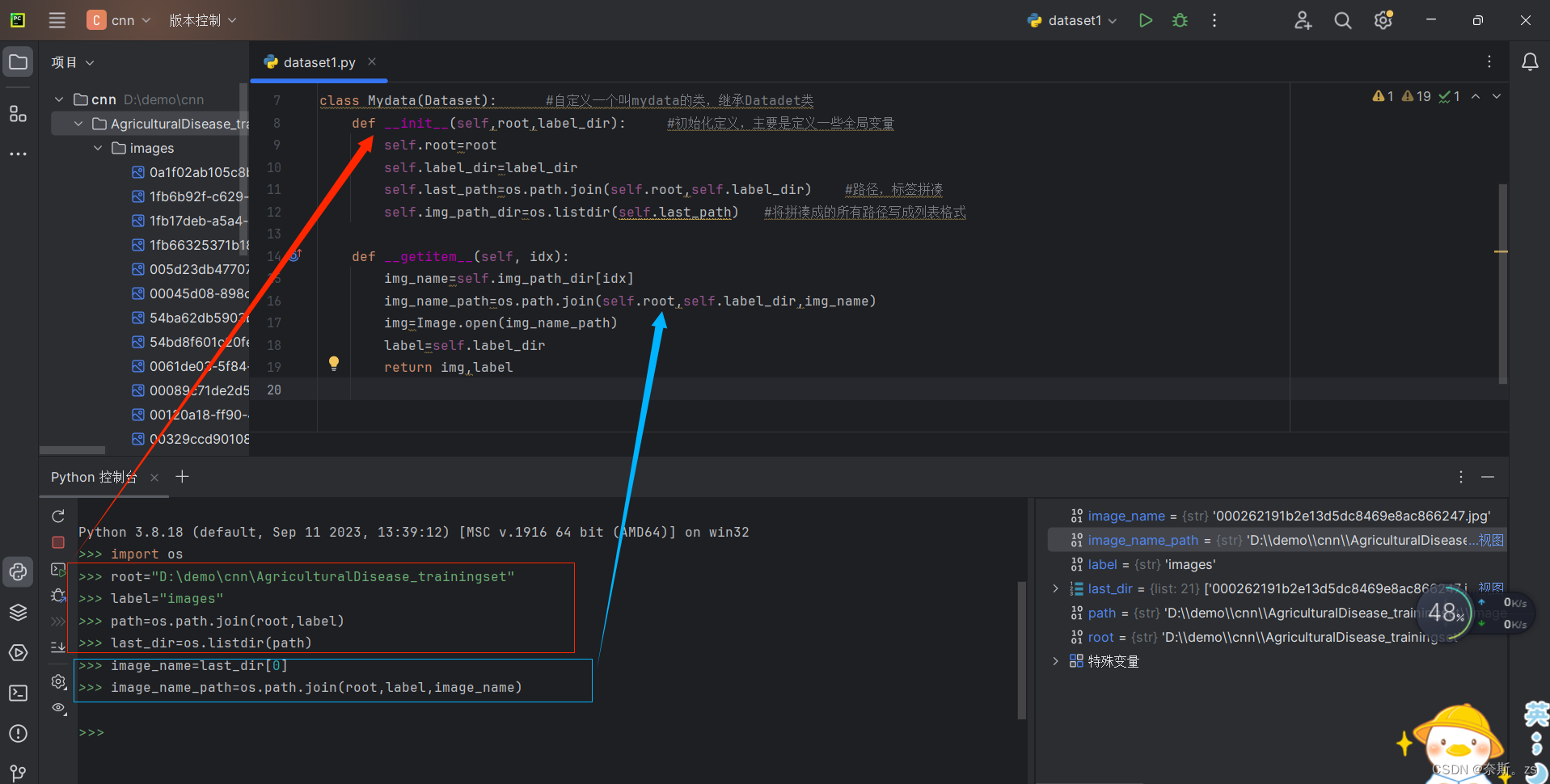
2.函数中变量写法——“self.××”是啥意思
就是本质上函数里面定义的变量是局部变量,不可以跨函数使用,但是我需要库函数使用,让她类似于一个函数内部定义的全局变量,那么就用“self.××”
在总面板上写的代码,可以在控制台一步一步写出然后运行,但是相应的变量名中不会有self出现,这种在控制台进行验证会方便我们观察,相当于就是在def中写函数,在控制台写相应的具体实现来验证函数
这篇关于1.pytorch加载收数据(B站小土堆)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





