本文主要是介绍《Mask2Former》算法详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章地址:《Masked-attention Mask Transformer for Universal Image Segmentation》
代码地址:https://github.com/facebookresearch/Mask2Former
文章为发表在CVPR2022的一篇文章。从名字可以看出文章像提出一个可以统一处理各种分割任务(全景分割、语义分割、实例分割)的网络。
这里稍微通俗的解释一下上述的几个分割任务:
全景分割:分割的结果有背景概念(天空、大海),有实例概念(person1、person2、person2)。
语义分割:只有类别概念,比如上述的person1、person2、person3都属于people这一类,不区分每个实例。且包含背景类别的识别。
实例分割:只有前景类别的概念,例如只有人、猫、狗等类别,没有天空大海这一类背景类别。且前景类别是有实例概念的。
更详细一点的说,在coco数据集里面定义,背景类称为stuff类别,这一类类别是没有边界的概念,例如一张图只有一片天空。前景类别称为things类别。
本文提出的网络就是可以一次性处理上述几个分割任务,而不用向之前的网络,一个任务去处理特定的一种任务。如下图所示
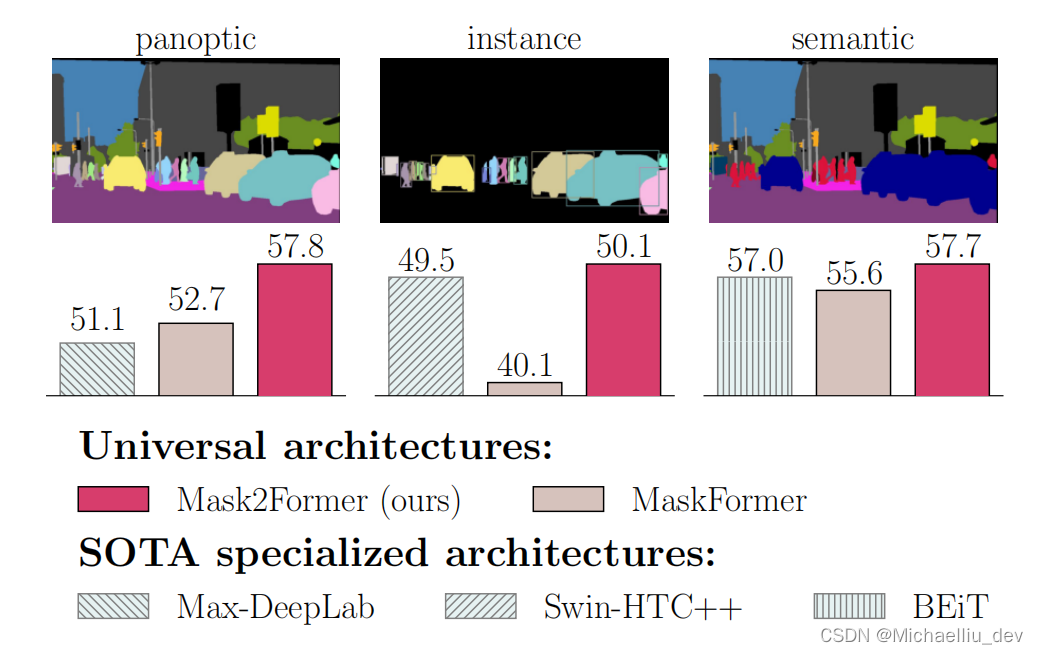
上图不仅可以看出不同任务的示意,还可以看出文章的网络在各个任务上表现都是SOTA的。
一、网络结构
文章采用的网络架构与MaskFormer 一致的。该类架构由三部分组成,一个backbone用于提取图片的特征,一个pixel decoder用于将主干网络提前的特征进行上采样生成高分辨率的图像特征,一个transformer decoder用于根据图像特征来处理object queries。最终网络根据pixel decoder输出的高分辨率的图像特征和transformer decoder输出的object queries生成最终的预测mask。
该结构能够很好的处理各种分割任务,原因就是输出对每个mask预测一个类别,这样不同的任务只是定义的不同类别而已。
具体的Mask2Former的示意图如下图所示,左边为整体的框架,右边为Transformer decoder with masked attention结构:
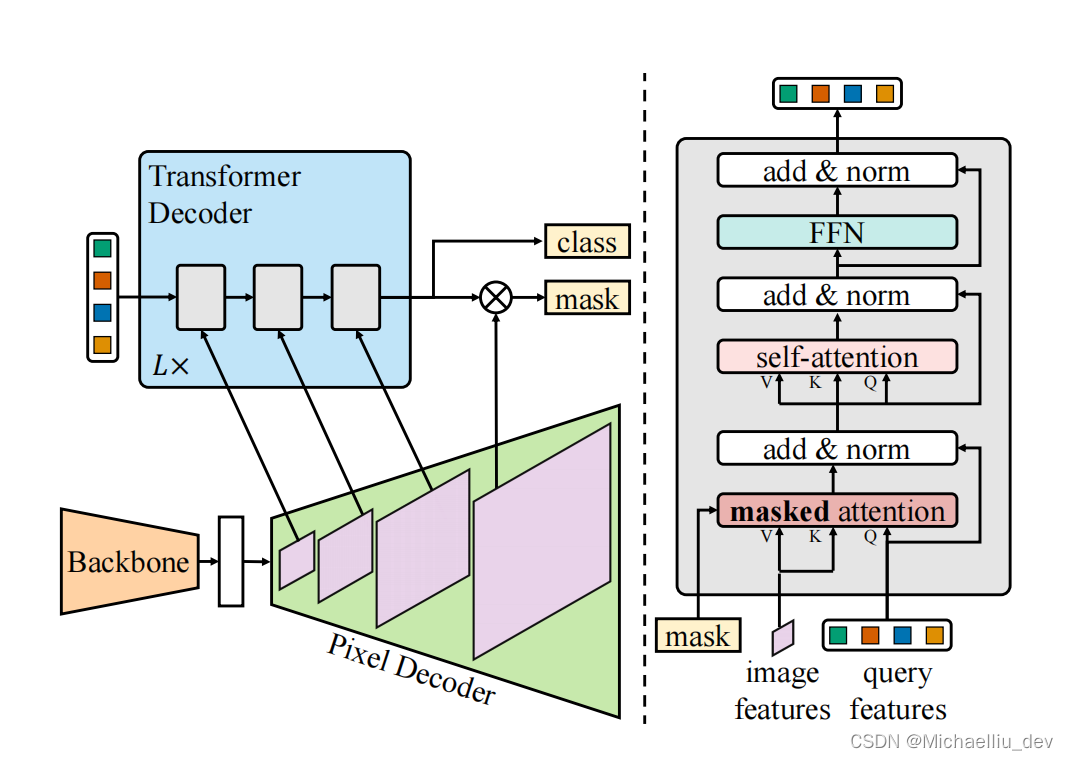
1.1 Transformer decoder with masked attention
有文章研究全局的特征信息对图像分割任务是非常重要的,但是也有文章证明对于transformer-based的结构来说,全局的特征信息会导致cross-attention收敛变慢,因为cross-attention需要很多轮的训练才能关注到需要关注的对应的物体区域上。
文章假设局部特征已经可以很好的去更新query feature了,而全局特征可以通过self-attention结构来学习。基于这假设,文章提出了masked attetion结构。
标准的cross-attetion结构用公式表示如下所示:
X l = s o f t m a x ( Q l K l T ) V l + X l − 1 X_l = softmax(Q_lK^T_l)V_l + X_{l-1} Xl=softmax(QlKlT)Vl+Xl−1
其中,l表示当前层的索引, X l ∈ R N × C X_l\in R^{N\times C} Xl∈RN×C表示l层的N个C维的query features,而 Q l = f Q ( X l − 1 ) ∈ R N × C Q_l=f_{Q}(X_{l-1})\in R^{N\times C} Ql=fQ(Xl−1)∈RN×C. X 0 X_0 X0表示Transformer decoder的输入。 K l , V l ∈ R H l W l × C K_l,V_l\in R^{H_l W_l \times C} Kl,Vl∈RHlWl×C为图像特征经过 f K ( ⋅ ) f_K({\cdot}) fK(⋅)和 f V ( ⋅ ) f_V({\cdot}) fV(⋅)变化后的结果,其中 H l H_l Hl和 W l W_l Wl是图像特征的分辨率。上述的 f Q f_Q fQ、 f K f_K fK和 f V f_V fV都是线性变换层。
本文提出的masked attetion模块,用公式表示如下:
X l = s o f t m a x ( M l − 1 + Q l K l T ) V l + X l − 1 X_l = softmax(M_{l-1}+Q_lK^T_l)V_l + X_{l-1} Xl=softmax(Ml−1+QlKlT)Vl+Xl−1
其中attetion mask M_{l-1}中位置(x,y)的值用如下公式计算得到:
M l − 1 ( x , y ) = { 0 i f M l − 1 ( x , y ) = 1 − ∞ o t h e r w i s e M_{l-1}(x, y)=\left\{ \begin{aligned} 0 \quad if M_{l-1}(x,y) = 1\\ -\infty \quad otherwise \end{aligned} \right. Ml−1(x,y)={0ifMl−1(x,y)=1−∞otherwise
这里 M l − 1 ∈ 0 , 1 N × H l W l M_{l-1}\in {0, 1}^{N\times H_l W_l} Ml−1∈0,1N×HlWl是根据阈值为0.5对Transformer decoder l-1层的输出进行resize后的二值化的结果。 resize后的分辨率大小和 K l K_l Kl一样。 M 0 M_0 M0是通过 X 0 X_0 X0二值化得到的。
1.2 High-resolution features
高分辨率的特征能够改善模型的效果,但是也每次都采用高分辨率的特征对于计算量要求也非常大。为了提升效率,文章输入给Transformer decoder层的特征采用不同分辨率的图片特征。
更详细说明,pixel decoder输出的图像特征大小分别为原图的1/32, 1/16, 1/8。对于每个分辨率的图片,在给到Transformer decoder之前,会加入sinusoidal positional embedding e p o s ∈ R H l W l × C e_{pos}\in R^{H_l W_l \times C} epos∈RHlWl×C和一个可学习的scale-level embedding e l v l ∈ R 1 × C e_{lvl}\in R^{1\times C} elvl∈R1×C。Transformer decoder对这种三层Transformer decoder结构重复L次。
1.3 Optimization improvements
这里针对普通的Transformer decoder layer进行改进。普通的Transformer decoder layer处理query features的顺序为self-attention module, cross-attention module,feed-forward network。query feature( X 0 X_0 X0)是初始化为0的特征。dropout用在residual connections和attention maps结构中。
文章对上述三点进行改进,文章认为self-attention只有图片特征的输入,没啥信息可以学习,为了提高计算效率,将self-attention、cross-attention调换了顺序。query feature( X 0 X_0 X0)变成可学习的特征。去除dropout。
二、提升训练效率
因为对高分辨率的mask进行预测,对显存的消耗很大,例如上一版的MaskFormer一个图片训练需要32G的显存。
受到PoinRend和Implicit PointRend文章的启发,训练分割任务的网络时,不需要计算整个mask的loss,只需要计算K个随机采样点的loss即可。
在训练时,有matching-loss(Transformer结构预测类别时特有的匹配loss)和final loss(匹配好后,计算预测结果和gt的loss)。
在计算matching-loss时,采用均匀采样采相同的K个点计算loss。
在计算final loss时,采用importance sampling,给每个不同的预测结果采不同的K个点进行计算loss。
这样的loss计算方式可以减少三倍的显存占用量,从而提高网络训练效率。
三、网络具体实现
- Pixel decoder. 采用multi-scale deformable attention(MSDeformAttn)做为pixel decoder结构,采用6层MSDeformAttn处理1/8,1/16,1/32大小的图片feature,并用一个上采样生成1/4的图片feature。
- Transformer decoder. L=3(共9层),100个queries(N=100), 在Transformer decoder layer的每个中间层度有一个辅助loss(9层的输出都有一个辅助loss来指导学习1.1中的M)
- Loss weights. 对于mask loss,文中采用binary cross-entropy loss和 dice loss一起,即 L m a s k = λ c e L c e + λ d i c e L d i c e L_{mask}=\lambda_{ce}L_{ce}+\lambda_{dice}L_{dice} Lmask=λceLce+λdiceLdice,其中 λ c e = 5.0 , λ d i c e = 5.0 \lambda_{ce}=5.0, \lambda_{dice}=5.0 λce=5.0,λdice=5.0. final loss是mask loss和classfication loss一起计算,即 L m a s k + λ c l s L c l s L_{mask}+\lambda_{cls}L_{cls} Lmask+λclsLcls,其中当有匹配的gt时 λ c l s = 2.0 \lambda_{cls}=2.0 λcls=2.0,当匹配的为no object时, λ c l s = 0.1 \lambda_{cls}=0.1 λcls=0.1
- post-processing. 对于全景和语义分割来说,后处理方式同MaskFormer,输出对应的mask以及其对应的类别。对于实例分割,为了输出对应实例的分割,采用类别的分数和mask的平均分数相乘得到每个实例的分数。
到这里该算法的基本内容都介绍完了,具体的训练参数还有训练数据以及数据结果可以查看文章找到更详细的信息。
这篇关于《Mask2Former》算法详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






