本文主要是介绍【深度学习】第二门课 改善深层神经网络 Week 2 3 优化算法、超参数调试和BN及其框架,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🚀Write In Front🚀
📝个人主页:令夏二十三
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏:深度学习
💬总结:希望你看完之后,能对你有所帮助,不足请指正!共同学习交流 🖊
文章目录
目录
文章目录
2.1 优化算法分类
2.2 超参数调试和BN及框架
2.1 优化算法分类
深度学习中的优化算法主要包括以下几种:
批量梯度下降(Batch Gradient Descent):这种方法涉及对整个训练数据集进行一次完整的遍历来计算梯度。然而,随着数据集的增大,这种方法的计算量也会增加。
小批量梯度下降(Mini-batch Gradient Descent):为了解决批量梯度下降的计算量问题,可以将数据集划分为多个较小的批次(mini-batches),并使用每个批次来计算梯度。这种方法既减少了计算量,又避免了随机梯度下降的噪声。
动量梯度下降(Momentum Gradient Descent):这种方法通过引入动量概念来加速学习过程。它考虑了之前的梯度信息,从而减少了学习过程中的震荡。
RMSprop:这种方法在动量梯度下降的基础上,还考虑了梯度的平方,这有助于确定学习率,特别是在数据分布不均匀的情况下。
Adam优化算法:这是一种自适应学习率的方法,结合了动量梯度下降和RMSprop的特点,能够更有效地处理非平稳目标函数。
这些优化算法在深度学习中起着关键作用,它们帮助模型更快地收敛并提高其性能。选择合适的优化算法取决于具体问题的性质和数据的特点。
除了这些梯度下降算法层面的优化,还有一些其他的优化手段,比如随着 epoch 的增大逐渐衰减学习率:(这里用t代表当前训练的迭代次数下标)
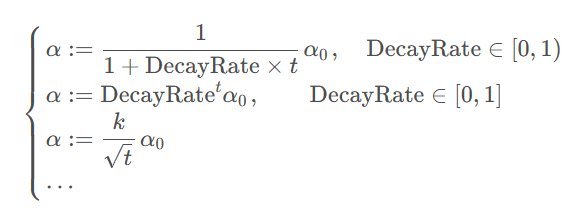
它们主要可以改善 mini-batch 带来的训练末期参数反复震荡的问题,不过就是会导致超参数的增加。
2.2 超参数调试和BN及框架
在深度学习中,超参数调试是指调整模型中的超参数以优化模型性能的过程。这些超参数包括学习率、批量大小、隐藏层神经元数量、网络层数等。通过实验和观察,研究人员可以找到最佳的超参数设置,以提高模型的准确性和泛化能力。
下面按照重要程度对神经网络中的一些超参数进行排序:
- 学习率α
- mini-batch大小
- 隐藏层神经元数量
- 动量梯度下降法滤波系数β
- 隐藏层个数
- 学习率衰减系数
- Adam优化方法参数
批量归一化(Batch Normalization, BN)是一种深度学习技术,用于加速训练过程并减少过拟合的风险。BN通过对每个小批量数据在激活函数之前进行归一化处理,使得每层输入的分布更加稳定,从而有助于解决内部协变量偏移问题,提高模型的泛化能力。
批量归一化(Batch Normalization,简称BN)是深度学习中一种用于提高训练速度和稳定性的技术。它的主要作用是对神经网络的每一层的输入数据进行归一化处理,即使得这些数据的分布保持一致。这样做有几个好处:
加速学习过程:通过归一化,可以允许使用更高的学习率,而不担心数值问题,从而加速模型的收敛速度。
减少过拟合:BN通过减少内部协变量偏移(Internal Covariate Shift)现象,即每层输入分布的变化,有助于模型更好地泛化。
减少对初始化的依赖:在没有BN的情况下,网络中每一层的输入分布会随着前面层参数的更新而变化,这要求对网络进行细致的初始化。BN减轻了这一需求。
批量归一化的具体步骤如下:
计算批均值和批方差:对每个特征在小批量数据上进行平均和方差的计算。
归一化:对每个特征进行归一化处理,使其具有均值为0和方差为1的分布。这通常通过减去均值并除以方差的平方根来实现。
缩放和平移:引入两个可学习的参数——缩放因子(γ)和平移因子(β),对归一化后的数据进行缩放和平移,以恢复网络的表示能力。
应用激活函数:在归一化、缩放和平移之后,对数据进行非线性激活。
批量归一化的关键在于它是在每个小批量(mini-batch)上进行的,而不是在整个数据集上。这使得归一化过程可以随数据的流动而动态调整,而不是固定不变。
BN在深度学习模型中广泛应用,尤其是在卷积神经网络(CNN)和前馈神经网络中,它有助于模型的训练效率和性能提升。然而,值得注意的是,BN在某些情况下可能不是最佳选择,例如在循环神经网络(RNN)中,或者在数据批量非常小的情况下,BN的效果可能不佳。
这篇关于【深度学习】第二门课 改善深层神经网络 Week 2 3 优化算法、超参数调试和BN及其框架的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





