本文主要是介绍Flink checkpoint 源码分析- Checkpoint barrier 传递源码分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
在上一篇的博客里,大致介绍了flink checkpoint中的触发的大体流程,现在介绍一下触发之后下游的算子是如何做snapshot。
上一篇的文章: Flink checkpoint 源码分析- Flink Checkpoint 触发流程分析-CSDN博客
代码分析
1. 在SubtaskCheckpointCoordinatorImpl中的checkpointState 主要进行了这个操作, source首先构造barrier,然后广播给下游。我们现在跟踪一下barrier的流动。
org.apache.flink.streaming.runtime.tasks.SubtaskCheckpointCoordinatorImpl#checkpointState
CheckpointBarrier checkpointBarrier =new CheckpointBarrier(metadata.getCheckpointId(), metadata.getTimestamp(), options);operatorChain.broadcastEvent(checkpointBarrier, options.isUnalignedCheckpoint());这个广播实际上是将数据写入到了下游。写的方法实际上就是netty写。
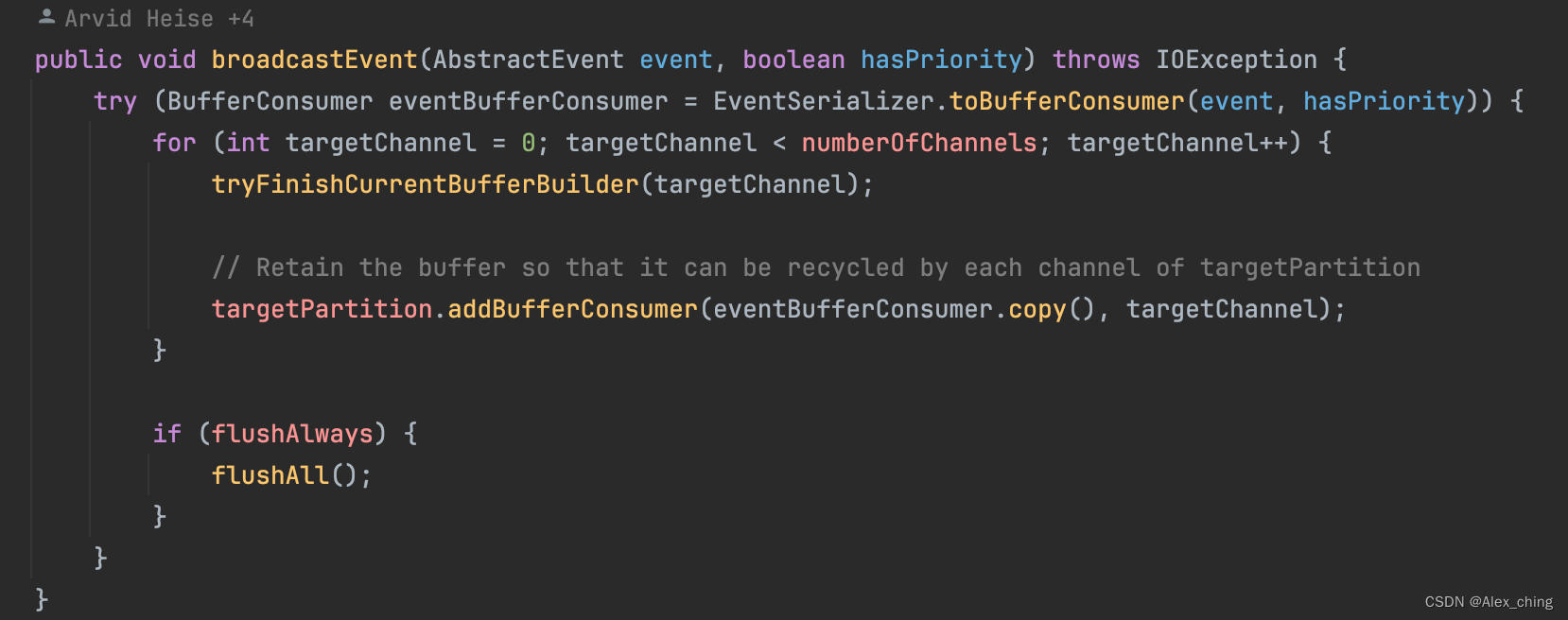
从flush的方法进去可以看到实际上是通知下游数据可用,下游看到数据可用就可以拉数据。因此可以看到这里的数据传递是通过pull的方式。
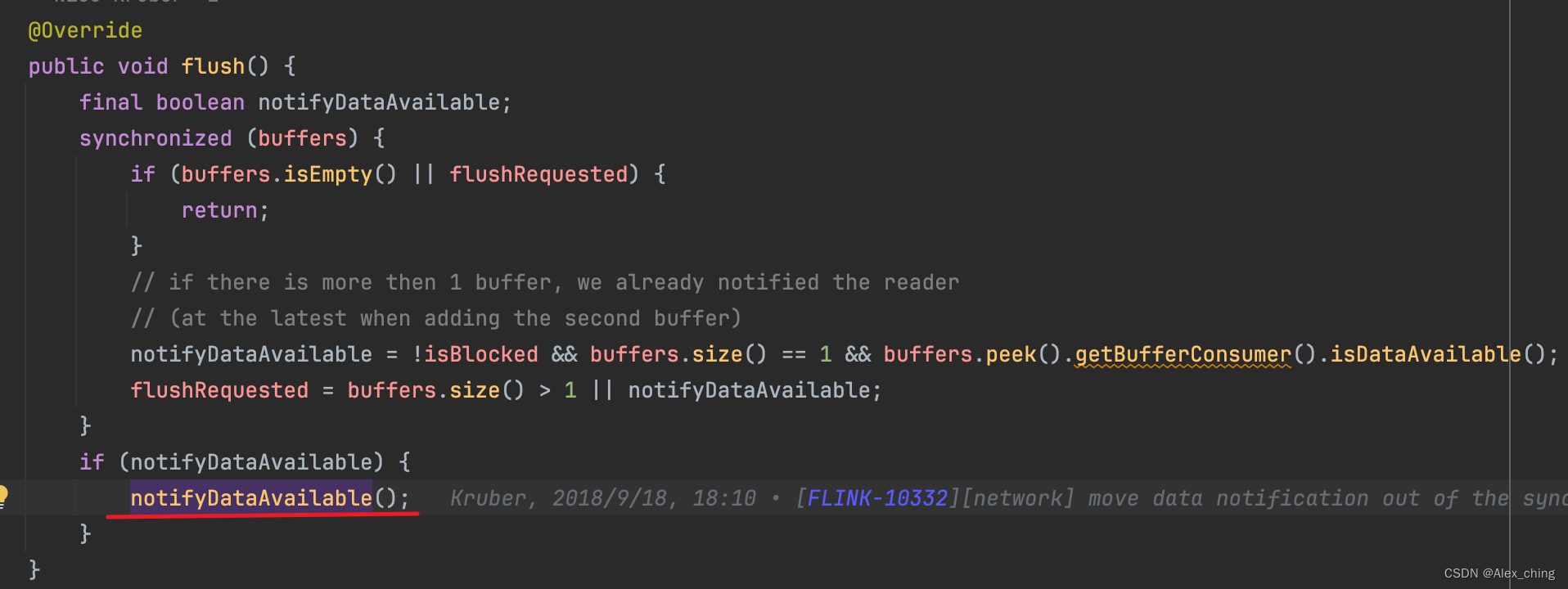
最后这个方法最后调用的是:org.apache.flink.runtime.io.network.netty.PartitionRequestQueue#notifyReaderNonEmpty方法,通过netty告知下游有数据了。

这些数据是从哪里读取到的呢?其实是在org.apache.flink.runtime.io.network.partition.consumer.RemoteInputChannel#getNextBuffer里面,flink对netty 进行了封装
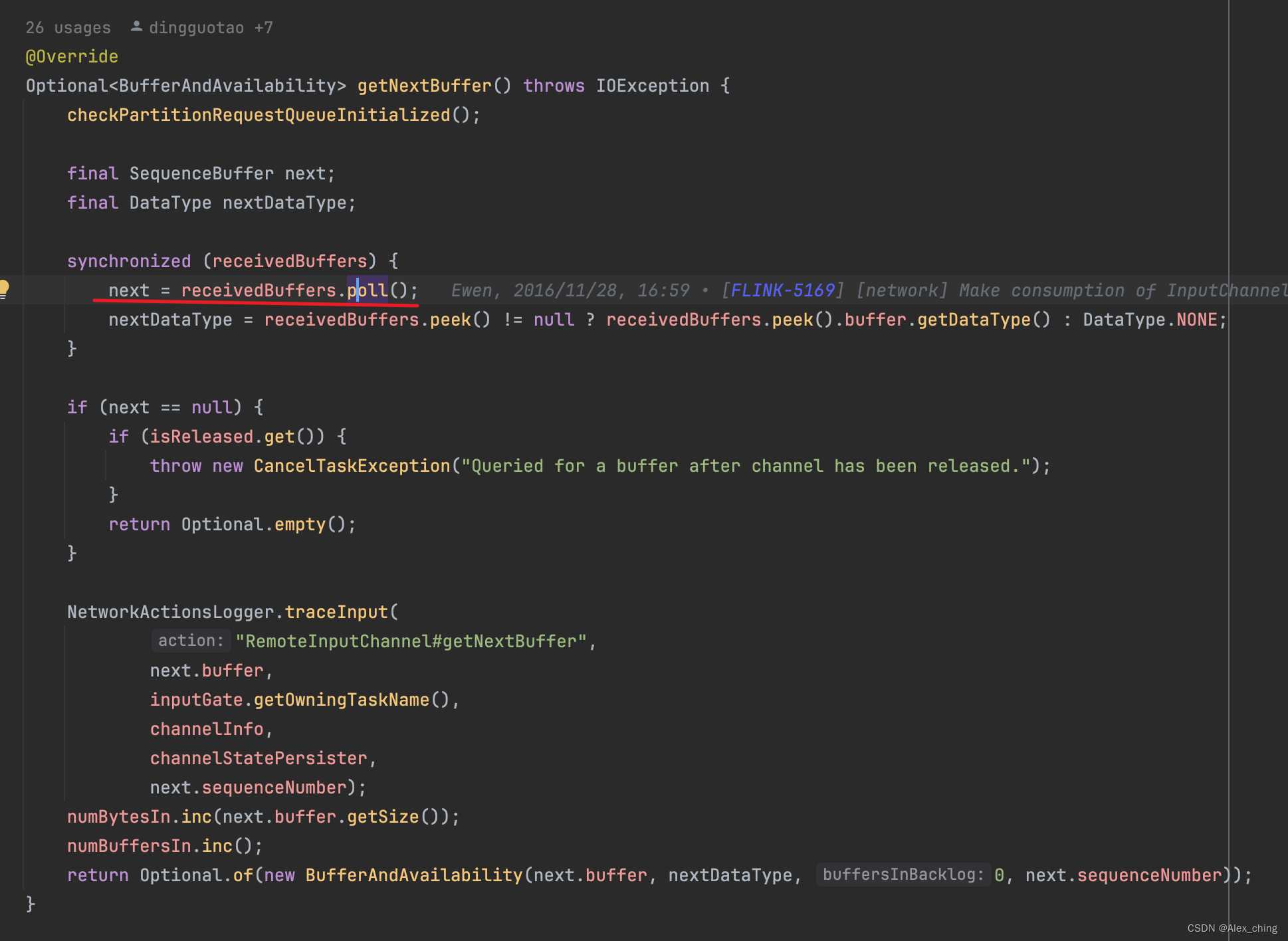
从这个方法再往上就可以看到是org.apache.flink.runtime.io.network.partition.consumer.SingleInputGate#getNextBufferOrEvent。
这里就是channel读取数据的地方。
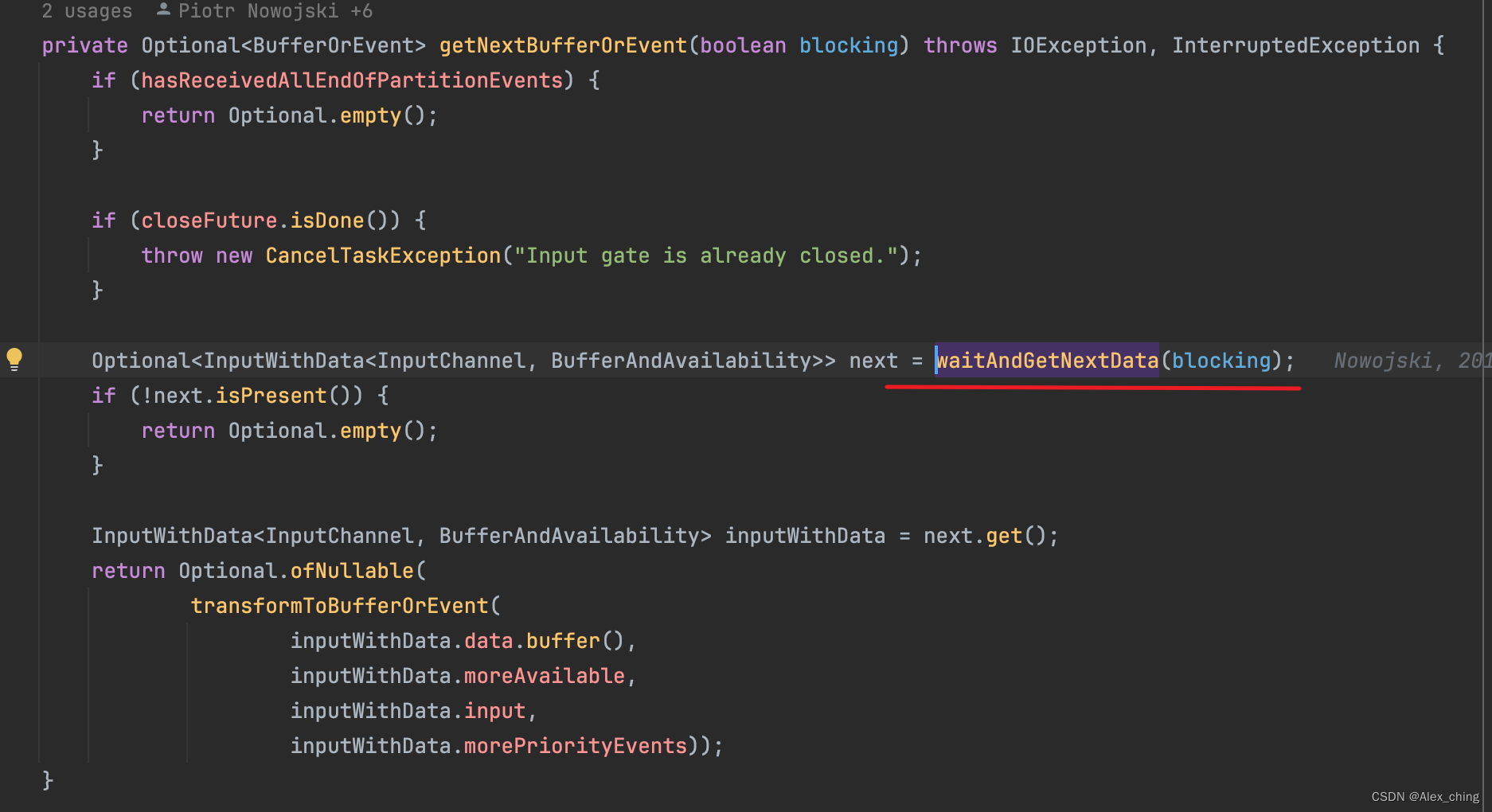
这里有一个方法:transformToBufferOrEvent。这里判断里面是数据还是事件。flink中定义的事件如下。
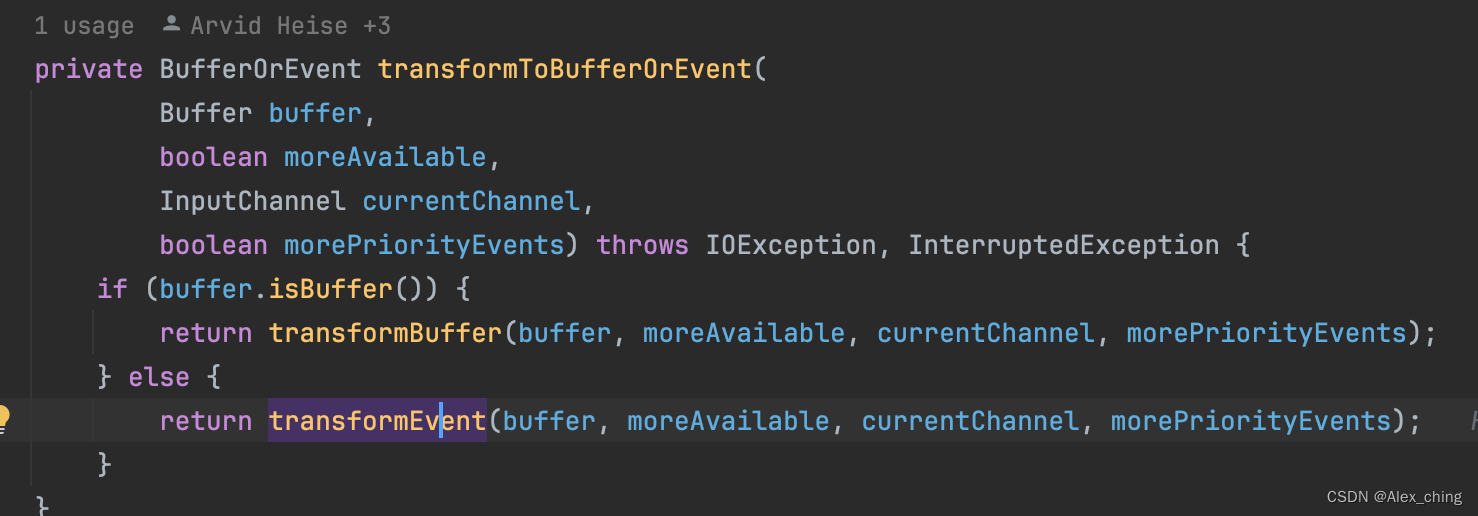
如果这里会走第一个分支,会将数据放到buffer里

这个时候上层org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput#emitNext
会接受数据, 如果是单流的话会在org.apache.flink.streaming.runtime.tasks.StreamTask#processInput 获取数据
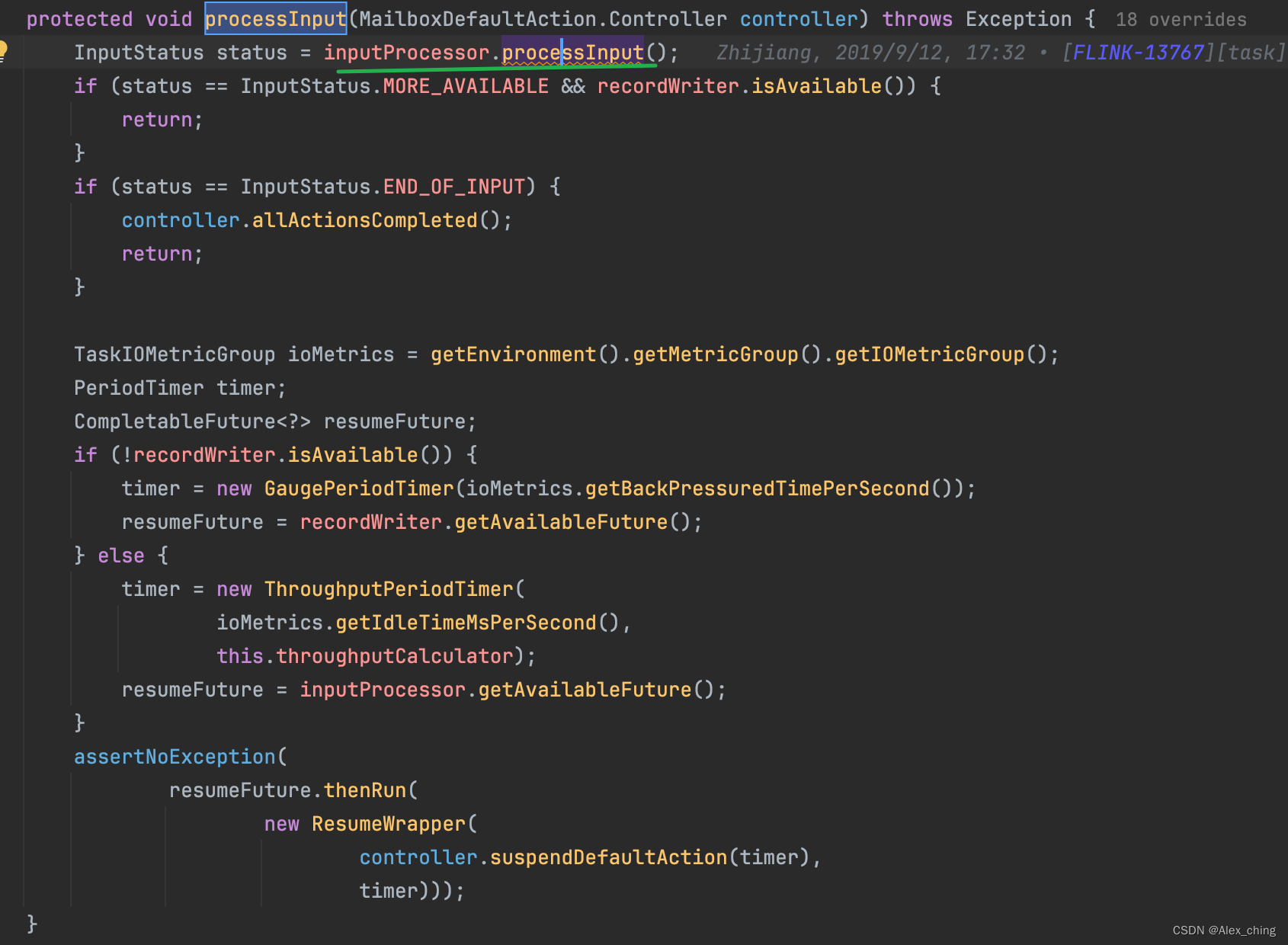
里面有一个org.apache.flink.streaming.runtime.io.StreamOneInputProcessor#processInput
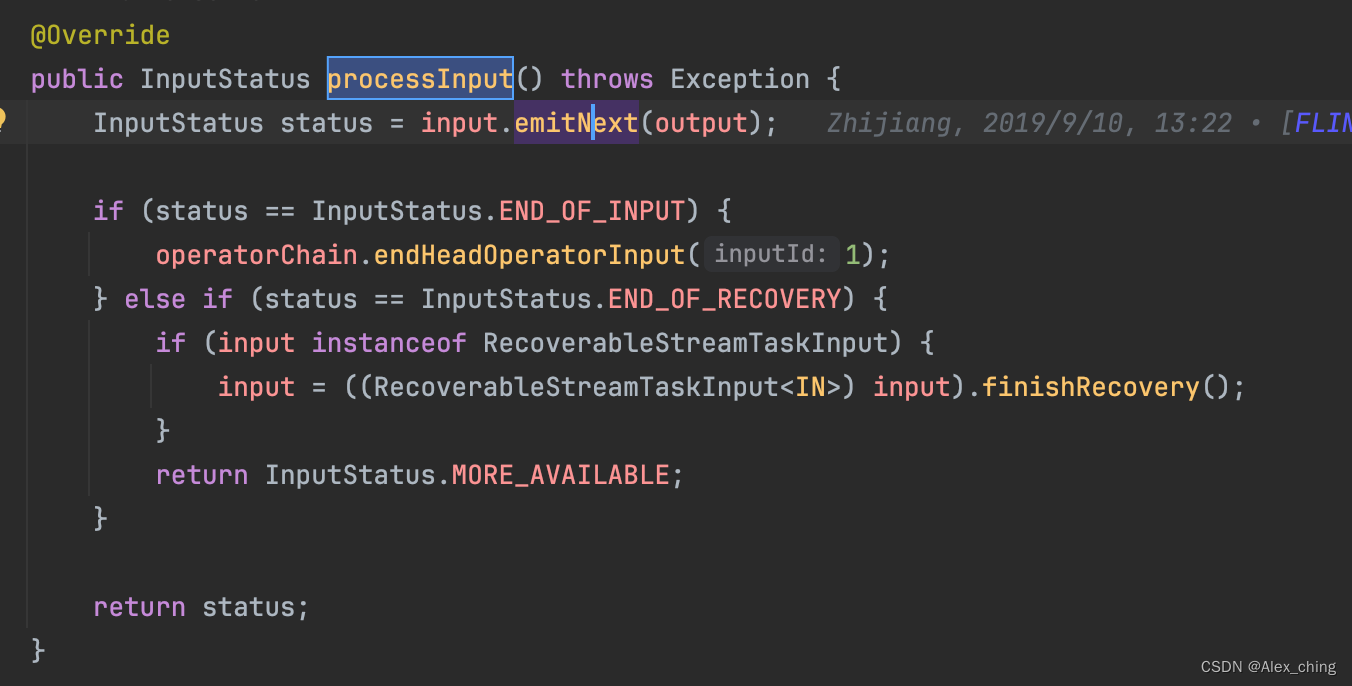
最后数据通过这个方法处理org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput#emitNext
里面就是对barrier时间的处理
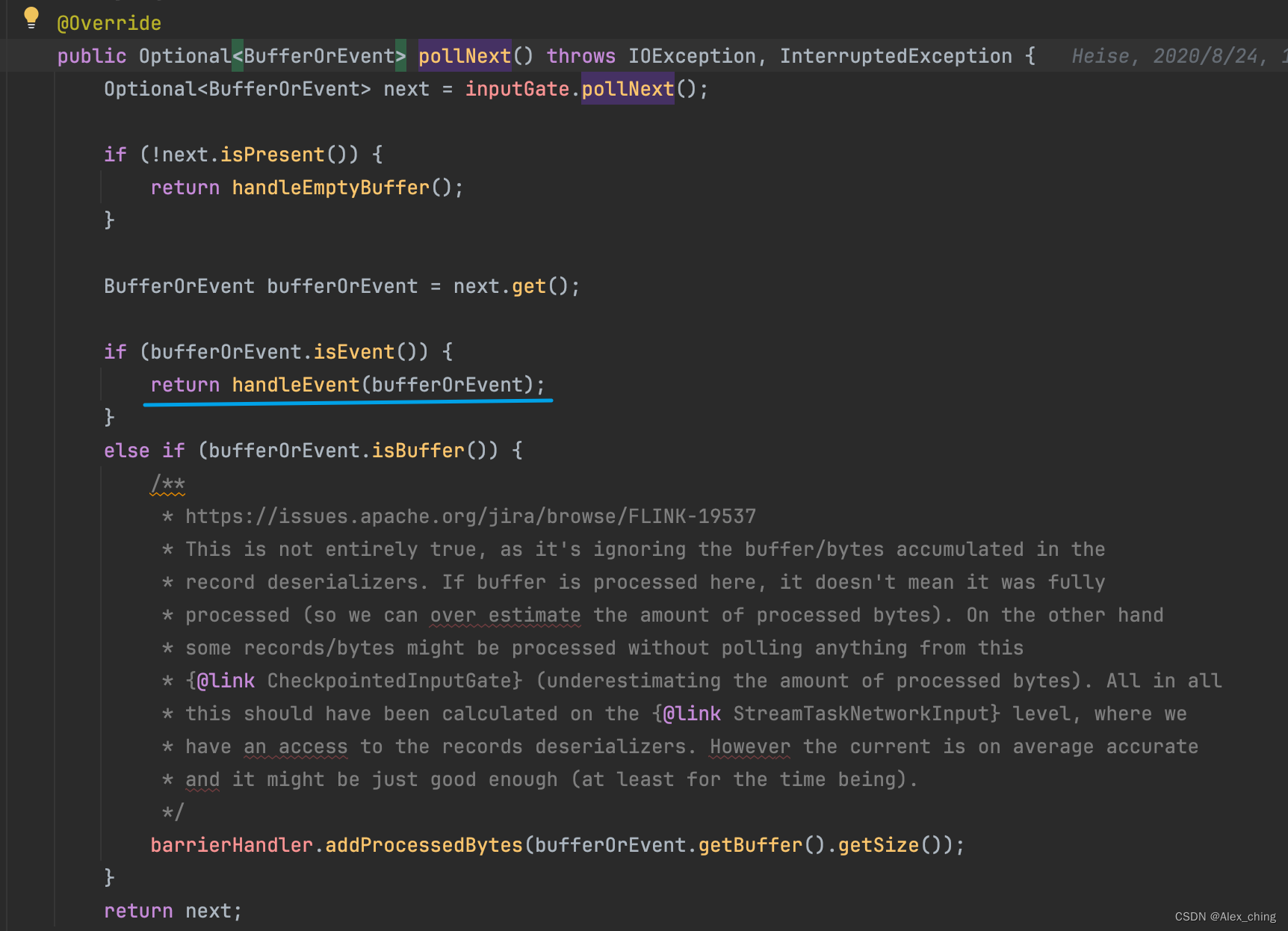
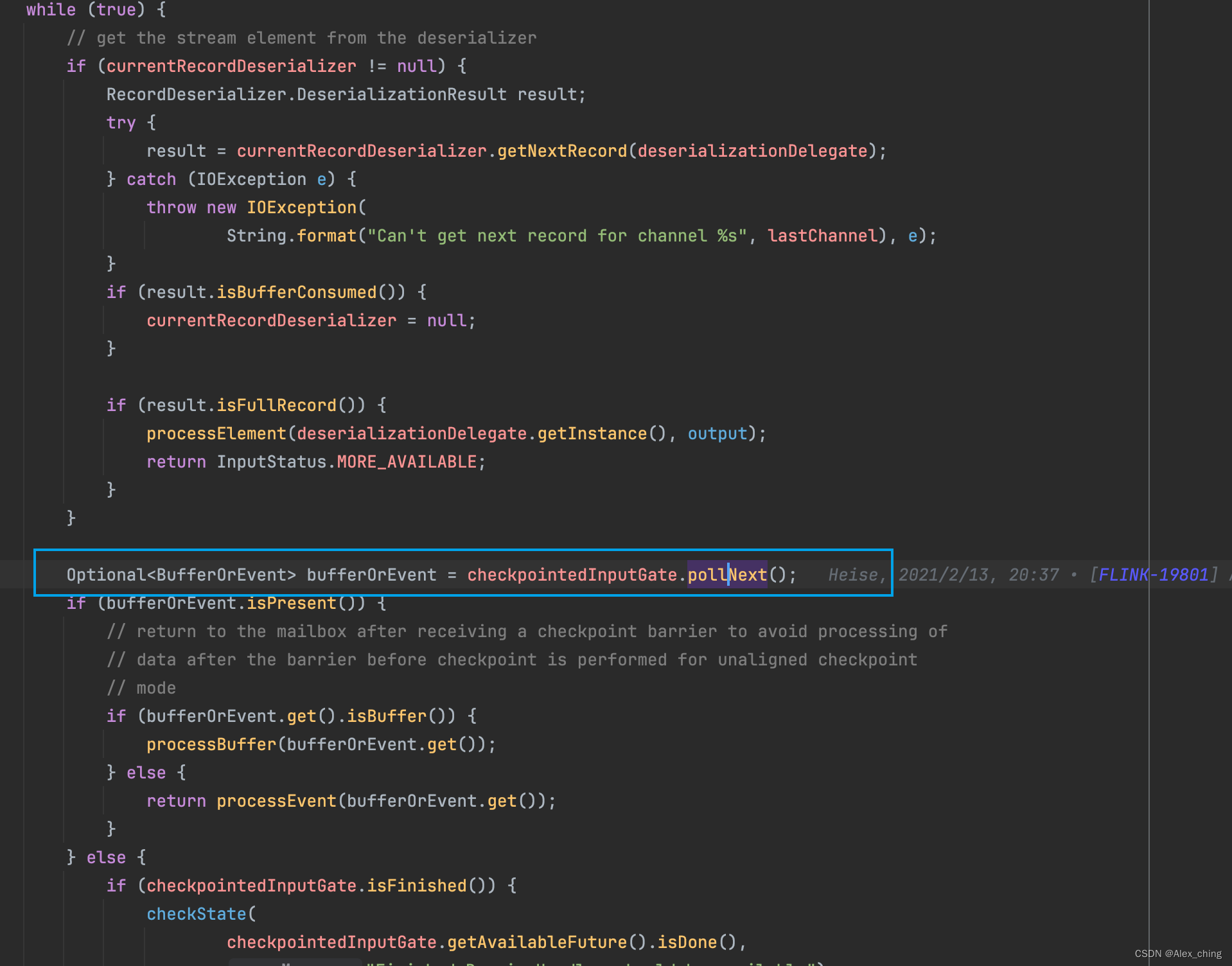
里面有不同的事件,针对不同的事件有不同的处理流程。其中包含了收到barrier如何处理的。从代码中可以看到有一个专门的方法处理barrier。
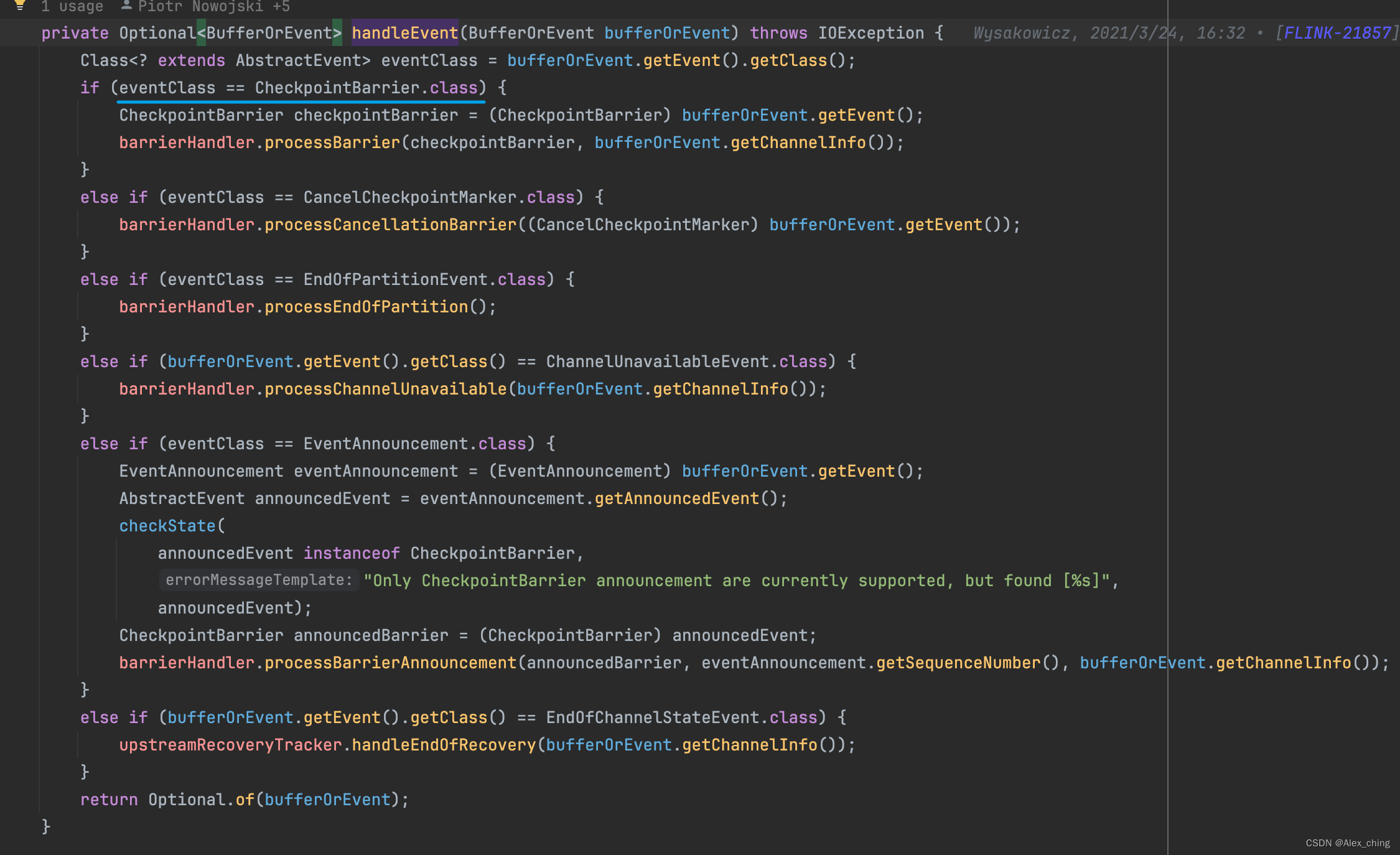
以上就是flink源码中barrier流动处理,后面我们再继续看看,算子接受到barrier是如何处理。
这篇关于Flink checkpoint 源码分析- Checkpoint barrier 传递源码分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






