本文主要是介绍Python urllib 爬虫入门(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文主要为Python urllib类库函数和属性介绍及一些简单示例。
目录
urllib爬取网页
简单示例
写入文件
其他读取方法
readline函数
readlines函数
response属性
当前环境信息
返回状态码
返回url地址
对url进行编码与解码
写入文件
总结
urllib爬取网页
通过python的urllib库请求爬取网页的一个简单示例。
简单示例
简单的使用urllib请求一个域名,并解析获取响应内容。
示例如下:
import urllib.request# 向指定url发起请求,并返回服务器响应数据(文件对象)
response = urllib.request.urlopen('http://www.baidu.com')
# 不解析的话为文件对象
# print(type(response.read()))
# 读取响应并解析为字符串格式
data = response.read().decode('utf-8')
print(data)写入文件
将响应的网页内容写入本地文件,在实际应用中主要用于前期分析网页信息。
示例如下:
import urllib.request# 向指定url发起请求,并返回服务器响应数据(文件对象)
response = urllib.request.urlopen('http://www.baidu.com')
data = response.read()import os
def writeLocalFile(content, name):with open(os.getcwd() + '/' + name + '.html', 'wb') as f:f.write(content)writeLocalFile(data, 'baidu')注意:这里不能把内容解析为字符串,否则写入时会报错。
其他读取方法
上文中例子使用是urllib.read()函数除外,还有其他的函数可以使用。
readline函数
读取文件一行,示例如下:
print(response.readline())执行结果:

readlines函数
读取文件的全部内容,会把读取到的数据赋值给一个列表变量。
示例如下:
con = response.readlines()
print(type(con))
print(con)执行结果:
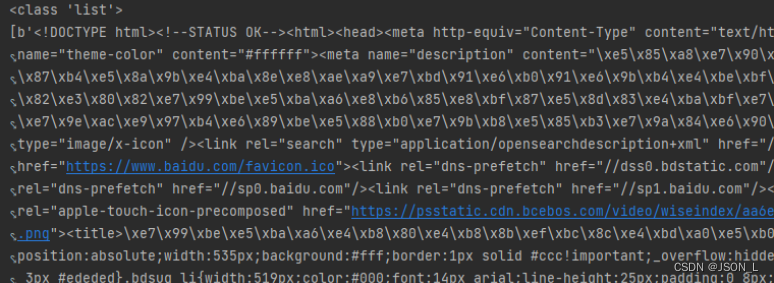
建议使用readlines方式获取,可以对文件内容进行分行处理:如去除空格。
response属性
当前环境信息
返回当前环境的有关信息
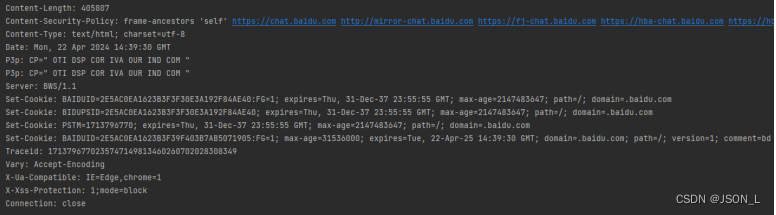
示例如下:
print(response.info())执行结果:
返回状态码
可通过返回状态码,来判断请求状态和是否继续执行。
print(response.getcode())执行结果:
200返回url地址
返回当前正在爬取的url地址,示例如下:
print(response.geturl())对url进行编码与解码
如果我们需要编码的URL中包含了特殊字符,如空格、斜杠、问号等,urllib quote()函数会将其替换为 % 加上换码后的ASCII码值,以此来保证URL的正确性。
示例如下:
import urllib.request
url = 'http://www.baidu.com'
# 编码
newUlr = urllib.request.quote(url)
print(newUlr) # http%3A//www.baidu.com# 解码
newUrl2 = urllib.request.unquote(newUlr)
print(newUrl2) # http://www.baidu.com写入文件
可使用urllib.request.urlretrieve() 函数把爬取到的网页直接写入文件中。
示例如下:
import urllib.requesturl = 'http://www.baidu.com'
fileName = './filename1.html'
info = urllib.request.urlretrieve(url, filename=fileName)
print(info)执行结果:
('./filename1.html', <http.client.HTTPMessage object at 0x000002379A37D5C8>)总结
本文主要为Python urllib类库函数和属性介绍及一些简单示例。
这篇关于Python urllib 爬虫入门(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





