本文主要是介绍扩展大型视觉-语言模型的视觉词汇:Vary 方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在人工智能领域,大型视觉-语言模型(LVLMs)正变得越来越重要,它们能够处理多种视觉和语言任务,如视觉问答(VQA)、图像字幕生成和光学字符识别(OCR)。然而,现有的模型通常依赖于一个通用的视觉词汇表,如CLIP,这在处理一些特殊视觉任务时可能会遇到效率低下和词汇表外问题。为了解决这些问题,研究者们提出了Vary方法,这是一种用于扩展LVLMs视觉词汇的有效方法。
LVLMs在多种任务上展现出了卓越的性能,但它们在处理如文档级OCR或图表理解这类需要细粒度视觉感知的任务时,仍然面临挑战。CLIP风格的视觉词汇表在这些任务中可能会遇到编码效率低下的问题。Vary方法的提出,旨在通过生成和融合新的视觉词汇表来提升LVLMs的性能。

Vary方法是针对大型视觉-语言模型(LVLMs)提出的一种创新方法,旨在通过扩展模型的视觉词汇来提升其在特定视觉任务上的表现,尤其是那些需要密集和细粒度视觉感知的任务,如文档级光学字符识别(OCR)或图表理解。以下是Vary方法的详细介绍:
1. 动机与挑战
现有的LVLMs通常使用统一的视觉词汇表,如CLIP,来处理各种视觉任务。然而,CLIP在处理一些特殊场景,如高分辨率图像、非英语OCR、文档/图表理解等任务时,可能不够高效,甚至会遇到超出词汇表的问题。
2. Vary的核心思想
Vary方法的核心思想是模仿文本词汇表的扩展方式,为视觉词汇表添加新的元素。这包括两个主要步骤:生成新的视觉词汇表和将新旧词汇表融合。
3. 方法细节
3.1 生成新的视觉词汇表
生成新的视觉词汇表是Vary方法的第一阶段,这一阶段的目标是创建一个能够补充现有CLIP视觉词汇表的新型视觉词汇表,以提高LVLMs在特定视觉任务上的表现。以下是详细说明,包括在论文中的具体位置:
新词汇网络的构建
- 使用预训练的ViTDet图像编码器:Vary采用了SAM预训练的ViTDet(base scale)图像编码器作为新词汇网络的主要组成部分。由于SAM-base的输入分辨率是1024×1024,输出步长是16,因此最后一层的特征形状是(64×64×256),这与CLIP-L的输出(256×1024)不匹配。为了解决这个问题,研究者们在SAM初始化网络的最后一层后面添加了两个卷积层,以将特征形状转换为与CLIP兼容的形式。
数据引擎和训练过程
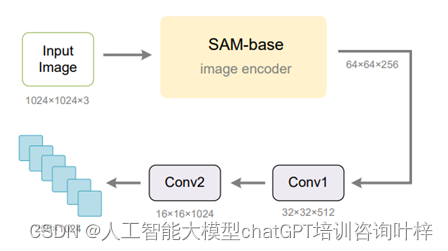
- 文档数据:选择高分辨率的文档图像-文本对作为主要的正面数据集,因为密集OCR可以有效验证模型的细粒度图像感知能力。研究者们创建了自己的数据集,包含了100万中文和100万英文文档图像-文本对。
- 图表数据:由于当前的LVLMs在图表理解方面表现不佳,特别是中文图表,研究者们选择将其作为需要写入新词汇的另一个主要知识点。他们使用matplotlib和pyecharts作为渲染工具,为matplotlib风格的图表构建了25万中英文数据对,对于pyecharts风格的图表则构建了50万。
- 负面自然图像:为了确保新引入的词汇在处理CLIP-VIT擅长的自然图像时不会产生噪声,研究者们构建了负面自然图像-文本对,以确保新词汇网络在看到自然图像时能正确编码。
输入格式
- Vary-tiny使用图像-文本对通过自回归进行训练。输入格式遵循流行的LVLMs,即使用两个特殊标记"<img>"和"</img>"来指示图像标记的位置,作为插值OPT-125M的输入。
3.2 扩展视觉词汇表
扩展视觉词汇表是Vary方法的核心贡献之一,旨在解决大型视觉-语言模型(LVLMs)在处理特定视觉任务时可能遇到的效率和性能问题。
Vary-tiny与Vary-base的架构
Vary-tiny 是Vary方法的第一阶段,专注于生成新的视觉词汇表。它由一个词汇网络和一个小型的OPT-125M模型组成。这个词汇网络使用自回归的方式,通过预测下一个词来生成新的视觉词汇。OPT-125M模型在这个过程中充当解码器,帮助生成与视觉任务相关的文本描述。
Vary-base 是Vary方法的第二阶段,它利用Vary-tiny生成的新视觉词汇表来增强LVLMs的性能。Vary-base的架构包括两个并行的视觉词汇网络:新的词汇网络和原有的词汇网络(如CLIP)。这两个网络在输入时是独立的,但它们的输出会在进入大型语言模型(LLM)之前进行整合,以此来提供更丰富的视觉特征表示。
训练策略
在训练Vary-base时,采取了一种特殊的策略,即冻结新旧视觉词汇网络的权重。这样做的目的是保留新旧词汇网络的知识,避免在训练过程中丢失。由于这些词汇网络已经在Vary-tiny阶段进行了训练,因此它们在Vary-base中的权重保持不变,这样可以确保新引入的视觉词汇不会影响已有的视觉特征提取能力。
除了冻结词汇网络的权重外,Vary-base中的其他模块,如输入嵌入层和LLM,其权重则不冻结。这些模块会在训练过程中进行优化,以适应新的视觉词汇并提高模型的整体性能。
训练过程

Vary-base的训练过程通常包括两个阶段:预训练和监督式微调(Supervised Fine-Tuning,简称SFT)。
- 预训练:在这个阶段,模型使用大量的图像-文本对进行训练,以学习通用的视觉和语言表示。预训练可以帮助模型建立一个强大的知识基础,为后续的微调打下基础。
- SFT:在SFT阶段,模型会在特定的下游任务上进行训练,以调整和优化模型参数,使其更适应特定的应用场景。这个阶段可能会使用特定的数据集,如DocVQA或ChartQA,来进行任务相关的优化。
通过这种训练策略,Vary-base能够结合新旧视觉词汇的优势,提高模型在复杂视觉任务上的表现,同时保持在通用任务上的性能。
4. 实验与结果
4.1 数据集和评估指标
- 自定义文档级OCR测试集:包含纯OCR任务和Markdown格式转换任务。纯OCR任务中,测试集随机抽取了100页中文和英文文档。Markdown转换任务中,测试集包含200页文档,其中100页包含表格,另100页包含数学公式。
- DocVQA和ChartQA:用于测试下游任务性能的提升。
- MMVet:用于监控模型在通用任务上的性能变化。
- 评估指标:对于文档解析任务,使用归一化编辑距离(Normalized Edit Distance)和F1分数来评估模型性能。对于DocVQA、ChartQA和MMVet,使用各自数据集的标准指标进行公平比较。
4.2 实施细节

- Vary-tiny训练:使用512的批量大小和3个epoch进行训练,采用AdamW优化器和余弦退火调度器,学习率为5e-5。
- Vary-base训练:在Vary-base的训练阶段,冻结新旧视觉词汇网络的权重,优化输入嵌入层和LLM的参数。预训练的初始学习率为5e-5,SFT(Supervised Fine-Tuning)阶段为1e-5。预训练和SFT阶段的批量大小为256,训练周期为1。
4.3 细粒度感知性能
- Vary-tiny:通过生成视觉词汇的过程,Vary-tiny获得了中文和英文的密集OCR能力。在中文和英文文档(纯文本)OCR上分别达到了0.266和0.197的编辑距离,证明了新视觉词汇在细粒度文本编码上的能力。
- Vary-base:与Nougat(一个专门的文档解析模型)相比,在英文纯文本文档上达到了相当的表现。通过不同的提示(例如,将图像转换为Markdown格式),Vary-base能够实现文档图像到Markdown格式的转换。
4.4 下游任务性能
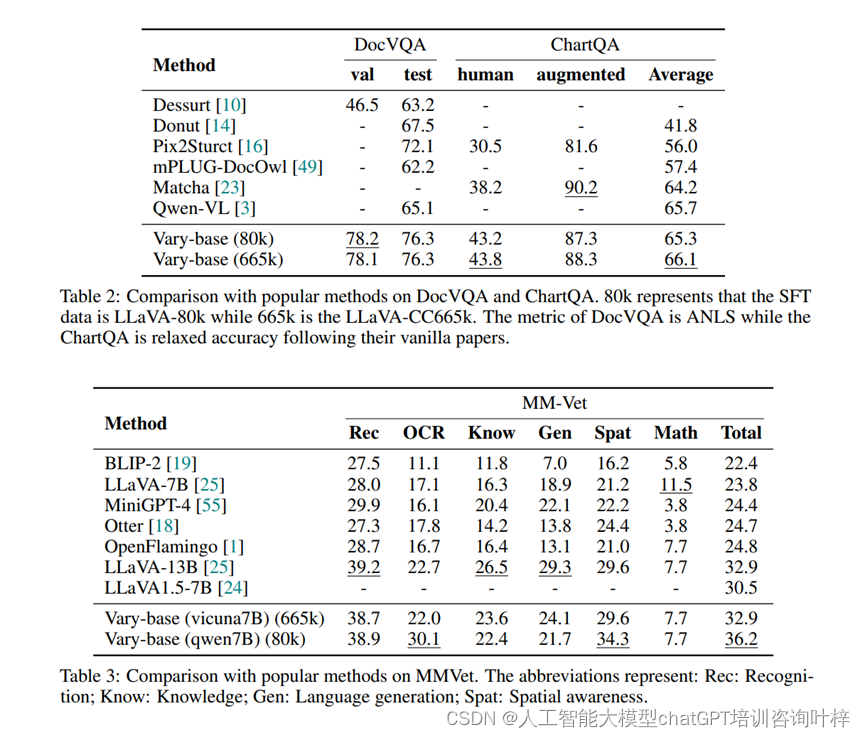
- DocVQA:Vary-base在LLaVA-80k SFT数据上达到了78.2%(测试)和76.3%(验证)的ANLS(Answer Normalized Levenshtein Score)。
- ChartQA:在使用LLaVA-665k数据进行SFT时,Vary-base在ChartQA上达到了66.1%的平均性能。
- 这些结果表明,Vary在这些具有挑战性的下游任务上的表现与Qwen-VL等流行方法相当或更好,证明了所提出的视觉词汇扩展方法对下游任务也是有益的。
4.5 通用性能
- MMVet基准:使用Vicuna-7B作为LLM,以及LLaVA-CC665k作为SFT数据,Vary在MMVet基准上的总指标比LLaVA-1.5高出2.4%,证明了Vary的数据和训练策略没有损害模型的通用能力。
实验结果表明,Vary方法通过扩展视觉词汇,在细粒度感知任务和下游任务性能上都取得了显著提升。同时,Vary在保持原有能力的同时,还增强了对特定视觉任务的处理能力,如文档级OCR和图表理解。这些结果证明了Vary方法的有效性,并展示了其在实际应用中的潜力。
5. 结论
Vary方法成功地证明了扩展LVLMs视觉词汇的重要性,并通过实验展示了其在多个任务上的卓越性能。尽管Vary已经取得了令人满意的结果,但在扩展视觉词汇方面仍有改进空间。研究者们希望Vary的设计能够吸引更多研究关注这一方向,并从视觉词汇构建的角度重新思考LVLMs的设计。
6. 代码与资源
Vary的代码已经开源,并可在GitHub上找到。此外,研究者们还提供了一些预训练模型和数据集,以促进进一步的研究和开发。
通过Vary方法,我们看到了LVLMs在处理特殊视觉任务方面的新可能性,这为未来的研究和应用开辟了新的道路。
项目主页:https://varybase.github.io/
论文地址:https://arxiv.org/pdf/2312.06109.pdf
Github地址:https://github.com/Ucas-HaoranWei/Vary
这篇关于扩展大型视觉-语言模型的视觉词汇:Vary 方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






