本文主要是介绍【深耕 Python】Data Science with Python 数据科学(16)Scikit-learn机器学习(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
关于数据科学环境的建立,可以参考我的博客:
【深耕 Python】Data Science with Python 数据科学(1)环境搭建
往期数据科学博文:
【深耕 Python】Data Science with Python 数据科学(2)jupyter-lab和numpy数组
【深耕 Python】Data Science with Python 数据科学(3)Numpy 常量、函数和线性空间
【深耕 Python】Data Science with Python 数据科学(4)(书337页)练习题及解答
【深耕 Python】Data Science with Python 数据科学(5)Matplotlib可视化(1)
【深耕 Python】Data Science with Python 数据科学(6)Matplotlib可视化(2)
【深耕 Python】Data Science with Python 数据科学(7)书352页练习题
【深耕 Python】Data Science with Python 数据科学(8)pandas数据结构:Series和DataFrame
【深耕 Python】Data Science with Python 数据科学(9)书361页练习题
【深耕 Python】Data Science with Python 数据科学(10)pandas 数据处理(一)
【深耕 Python】Data Science with Python 数据科学(11)pandas 数据处理(二)
【深耕 Python】Data Science with Python 数据科学(12)pandas 数据处理(三)
【深耕 Python】Data Science with Python 数据科学(13)pandas 数据处理(四):书377页练习题
【深耕 Python】Data Science with Python 数据科学(14)pandas 数据处理(五):泰坦尼克号亡魂 Perished Souls on “RMS Titanic”
【深耕 Python】Data Science with Python 数据科学(15)pandas 数据处理(六):书385页练习题
代码说明: 由于实机运行的原因,可能省略了某些导入(import)语句。
本期,使用Scikit-learn机器学习库对第14期泰坦尼克号乘客数据进行回归分析。
一、读取数据表格
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltURL = "https://learnenough.s3.amazonaws.com/titanic.csv"
titanic = pd.read_csv(URL)
二、绘制散点图
通过绘制散点图,分析乘客年龄和生还率的关系。
首先,从表格中提取“年龄”列和“生还”列:
passenger_age = titanic[["Age", "Survived"]].dropna() # 去除NaN值
print(passenger_age.head())
程序输出:
# 年龄 是否生还Age Survived
0 22.0 0 # 未生还
1 38.0 1 # 生还
2 26.0 1
3 35.0 1
4 35.0 0
提取乘客年龄,并对其进行升序排序:
passenger_ages = passenger_age["Age"].unique()
passenger_ages.sort()
print(passenger_ages)
程序输出:
# 最小年龄:0.42岁;最大年龄:80岁
[ 0.42 0.67 0.75 0.83 0.92 1. 2. 3. 4. 5. 6. 7.8. 9. 10. 11. 12. 13. 14. 14.5 15. 16. 17. 18.19. 20. 20.5 21. 22. 23. 23.5 24. 24.5 25. 26. 27.28. 28.5 29. 30. 30.5 31. 32. 32.5 33. 34. 34.5 35.36. 36.5 37. 38. 39. 40. 40.5 41. 42. 43. 44. 45.45.5 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 55.556. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 70.70.5 71. 74. 80. ]
计算不同年龄乘客的生还率,并对年龄区间30~40岁乘客的(平均)生还率进行输出:
survival_rate = passenger_age.groupby("Age")["Survived"].mean()
print(survival_rate.loc[30:40])
程序输出:
# 年龄 平均生还率
Age
30.0 0.400000
30.5 0.000000
31.0 0.470588
32.0 0.500000
32.5 0.500000
33.0 0.400000
34.0 0.400000
34.5 0.000000
35.0 0.611111
36.0 0.500000
36.5 0.000000
37.0 0.166667
38.0 0.454545
39.0 0.357143
40.0 0.461538
Name: Survived, dtype: float64
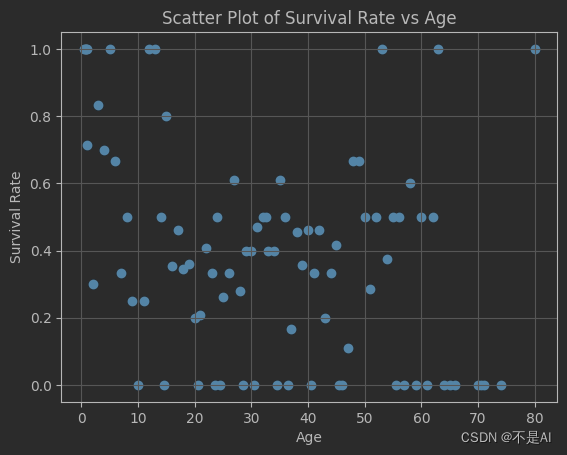
接下来,以年龄作为横坐标,平均生还率作为纵坐标,绘制散点图:
fig, ax = plt.subplots()
ax.scatter(passenger_ages, survival_rate)
plt.title("Scatter Plot of Survival Rate vs Age")
plt.xlabel("Age")
plt.ylabel("Survival Rate")
plt.grid()
plt.show()
程序输出:
三、使用Scikit-learn对数据进行线性回归分析
首先,准备自变量X和因变量Y:
from sklearn.linear_model import LinearRegressionX = np.array(passenger_ages).reshape((-1, 1))
print(X[:10])
Y = np.array(survival_rate)
程序输出:
# 前10个年龄值
[[0.42][0.67][0.75][0.83][0.92][1. ][2. ][3. ][4. ][5. ]]
建立线性回归模型并检视模型参数:
model = LinearRegression()
model.fit(X, Y)
print(model.score(X, Y))
m = model.coef_
b = model.intercept_
print(m)
print(b)
程序输出:
0.13539675574075116 # 模型的R^2值
[-0.00562704] # 直线的斜率
0.582616045704144 # 直线的y轴截距
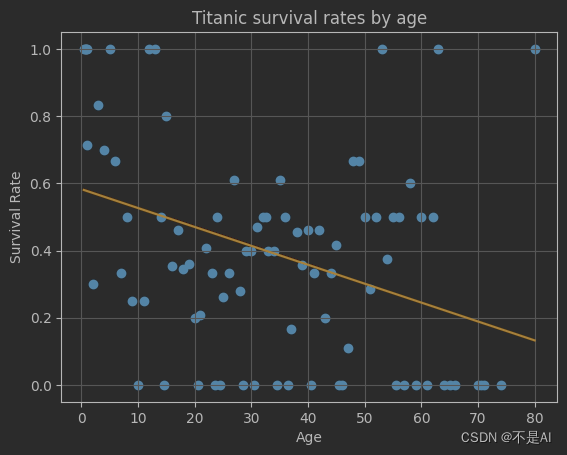
接下来,绘制此模型对数据拟合的直线:
fig, ax = plt.subplots()
ax.scatter(passenger_ages, survival_rate)
ax.plot(passenger_ages, m * passenger_ages + b, color="orange")
ax.set_xlabel("Age")
ax.set_ylabel("Survival Rate")
ax.set_title("Titanic survival rates by age")
plt.grid()
plt.show()
程序输出:
参考文献 Reference
《Learn Enough Python to be Dangerous——Software Development, Flask Web Apps, and Beginning Data Science with Python》, Michael Hartl, Boston, Pearson, 2023.
这篇关于【深耕 Python】Data Science with Python 数据科学(16)Scikit-learn机器学习(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





