本文主要是介绍Kafka Exactly Once 语义实现原理:幂等性与事务消息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01 前言
在现代分布式系统中,确保数据处理的准确性和一致性是至关重要的。Apache Kafka,作为一个广泛使用的流处理平台,提供了强大的消息队列和流处理功能。随着业务需求的增长,Kafka 的事务消息功能应运而生,它允许应用程序以一种原子的方式处理消息,即要么所有消息都被正确处理,要么都不处理。本文将深入剖析 Kafka 的 Exactly-Once 语义实现原理,包括幂等性与事务消息的关键概念,以及它们是如何在 Kafka 中实现的。我们将探讨 Kafka 事务的流程,事务提供的 ACID 保证,以及在实际应用中可能遇到的一些限制。无论您是 Kafka 的新手还是经验丰富的开发者,本文都将为您提供有价值的见解和指导。
02 消息队列的事务场景
Kafka 目前用于流处理的场景:相当于一个有向无环图(DAG,Directed acyclic graph)每个节点是一个 Kafka Topic,每条边是一个流处理操作。在这样的场景下,有两种操作:ꔷ 消费上游消息并提交位点ꔷ 处理消息并发送到下游 Topic
对于由这两种操作构成的一组处理流程需要具备事务语义,这样我们就可以不重复(Exactly Once)的处理上游消息并将结果可靠地存储在下游 Topic 中。

上图是一个典型的 Kafka 事务的流程,我们可以看到:MySQL 的 binlog 作为上游数据源将数据写入到 Kafka 中,Spark Streaming 从 Kafka 中读取数据并进行处理,最后将处理结果写入到另外两个 Topic 中(图中三个 Topic 位于同一集群中)。其中消费 Topic A 与写入 Topic B 和 Topic C 的操作具备事务语义。
03 Kafka 的 Exactly Once 语义
从上述的场景中我们可以发现,事务消息最主要的动机是在流处理中实现 Exactly Once 的语义,这可以分为:
ꔷ 仅发送一次: 单分区仅发送一次由生产者幂等保证,多分区仅发送一次由事务机制保证
ꔷ 仅消费一次: Kafka 通过消费位点的提交来控制消费进度,而消费位点的提交被抽象成向系统 topic 发送消息。这就使得发送和消费行为统一起来,只要解决了多分区发送消息的一致性就能实现 Exactly Once 语义
04 生产者幂等性
在创建 Kafka 生产者时设置了 enable.idempotence 参数,用于开启生产者幂等性。
val props = new Properties()
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true")val producer = new KafkaProducer(props)Kafka 的发送幂等是通过序列号来实现的,每个消息都会被分配一个序列号,序列号是递增的,这样就可以保证消息的顺序性。当生产者发送消息时,会将消息的序列号和消息内容一起写入到日志文件中,下次收到非预期序列号的消息就会返回 OutOfOrderSequenceException 异常。
设置 enable.idempotence 参数后,生产者会检查以下三个参数的值是否合法(ProducerConfig#postProcessAndValidateIdempotenceConfigs) ꔷ max.in.flight.requests.per.connection 必须小于 5
ꔷ retries 必须大于 0
ꔷ acks 必须设置为 all
Kafka 将消息的序列号信息保存在分区维度的 .snapshot 文件中,格式如下(ProducerStateManager#ProducerSnapshotEntrySchema):

我们可以发现,该文件中保存了 ProducerId、ProducerEpoch 和 LastSequence。所以幂等的约束为:相同分区、相同 Producer(id 和 epoch) 发送的消息序列号需递增。即 Kafka 的生产者幂等性只在单连接、单分区生效,Producer 重启或消息发送到其他分区就失去了幂等性的约束。
.snapshot 文件在 log segment 滚动时更新,发生重启后通过读取 .snapshot 文件和最新的日志文件即可恢复 Producer 的状态。Broker 的重启或分区迁移并不会影响幂等性。
05 事务消息流程
我们首先从 Demo 开始,来看一下如何使用 Kafka 客户端完成一个事务:
// 事务初始化
val props = new Properties()
...
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionalId)
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true")val producer = new KafkaProducer(props)
producer.initTransactions()
producer.beginTransaction()// 消息发送
producer.send(RecordUtils.create(topic1, partition1, "message1"))
producer.send(RecordUtils.create(topic2, partition2, "message2"))// 事务提交或回滚
producer.commitTransaction()5.1 事务初始化
Kafka Producer 启动后我们使用两个 API 来初始化事务:initTransactions 和 beginTransaction。
回顾一下我们的 Demo,在发送消息时是发送到两个不同分区中,这两个分区可能在不同的 Broker 上,所以我们需要一个全局的协调者 TransactionCoordinator 来记录事务的状态。
所以,在 initTransactions 中,Producer 首先发送 ApiKeys.FIND_COORDINATOR 请求获取 TransactionCoordinator。
之后即可向其发送 ApiKeys.INIT_PRODUCER_ID 请求获取 ProducerId 及 ProducerEpoch(也是上文中用于幂等的字段)。此步骤生成的 id 和 epoch 会写入内部 Topic __transaction_state 中,并且将事务的状态置为 Empty。
__transaction_state 是 compaction Topic,其中消息的 key 为客户端设置的transactional.id(详见 TransactionStateManager#appendTransactionToLog)。
区别于 ProducerId 是服务端生成的内部属性;TransactionId 由用户设置,用于标识业务视角认为的“同一个应用”,启动具有相同 TransactionId 的新 Producer 会使得未完成的事务被回滚并且来自旧 Producer(具有较小 epoch)的请求被拒绝掉。
后续 beginTransaction 用于开始一个事务,该方法会创建一个 Producer 内部事务状态,标识这一个事务的开始,并不会有 RPC 产生。
5.2 消息发送
上一节说到 beginTransaction 只是更改 Producer 内部状态,那么在第一条消息发送时才隐式开启了事务:
首先,Producer 会发送 ApiKeys.ADD_PARTITIONS_TO_TXN 请求到 TransactionCoordinator。TransactionCoordinator 会将这个分区加入到事务中,并更改事务的状态为 Ongoing,这些信息被持久化到 __transaction_state 中。
然后 Producer 使用 ApiKeys.PRODUCE 请求正常发送消息到对应的分区中。这条消息的可见性控制在下文消息消费一节中会详细讨论。
5.3 事务提交与回滚
当所有消息发送完成后,Producer 可以选择提交或回滚事务,此时:
ꔷ TransactionCoordinator:具有当前事务所有相关分区的信息
ꔷ 其他 Broker:已经将消息持久化到日志文件中
接下来 Producer 调用 commitTransaction 会发送 ApiKeys.END_TXN 请求将事务状态更改为 PrepareCommit(回滚事务对应状态 PrepareAbort)并持久化到 __transaction_state 中,此时从 Producer 的视角来看整个事务已经结束了。
TransactionCoordinator 会异步向各个 Broker 发送 ApiKeys.WRITE_TXN_MARKERS 请求,当所有参加事务的 Broker 都返回成功后,TransactionCoordinator 会将事务状态更改为 CompleteCommit(回滚事务对应状态 CompleteAbort)并持久化到 __transaction_state 中。
5.4 消息的消费
某个分区的消息可能是事务消息与非事务消息混杂的,如下图所示:
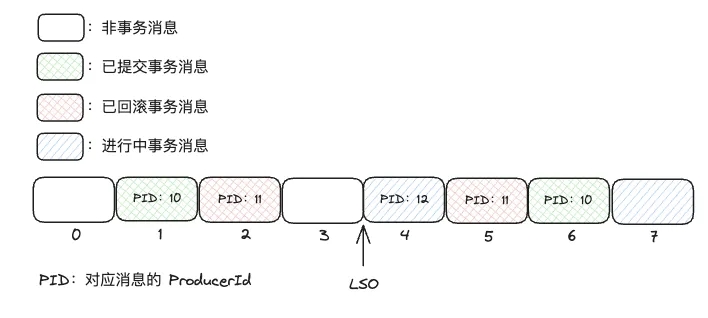
在 Broker 处理 ApiKeys.PRODUCE 请求时,完成消息持久化会更新 LSO 到第一条未提交的事务消息的 offset。这样在消费者消费消息时,可以通过 LSO 来判断消息是否可见:如果设置了 isolation.level 为 read_committed 则只会消费 LSO 之前的消息。
LSO(log stable offset): 它表示的是已经被成功复制到所有副本(replicas)并且可以被消费者安全消费的消息的最大偏移量。
但是我们可以发现 LSO 之前存在已回滚的消息(图中红色矩形)这些消息应该被过滤掉:在 Broker 处理 ApiKeys.WRITE_TXN_MARKERS 请求时,会将已回滚的消息索引写入到 .txnindex 文件中(LogSegmentKafka#updateTxnIndex)。
后续 Consumer 消费消息时还会收到对应区间的已取消事务消息列表,上图区间中的该列表为:

代表 offset 在 [2,5] 之间且由 id 为 11 的 Producer 发送的消息都已回滚。
上文我们讨论了 __transaction_state 的实现确保同一时间,同一 TransactionId 有且只有一个事务在进行中。所以可以使用 ProducerId 和 offset 区间定位回滚的消息不会发生冲突。
06 Kafka 事务提供的 ACID 保证
ꔷ 原子性(Atomicity)
Kafka 通过对 __transaction_state Topic 的写入实现了事务状态的转移,保证了事务要么同时提交,要么同时回滚。
ꔷ 一致性(Consistency)
在事务进入 PrepareCommit 或 PrepareAbort 阶段时, TransactionCoordinator 异步向所有参与事务的 Broker 提交或回滚事务。这使得 Kafka 的事务做不到强一致性,只能通过不断重试保证最终一致性。
ꔷ 隔离性(Isolation)
Kafka 通过 LSO 机制和 .txnindex 文件来避免脏读,实现读已提交(Read Committed)的隔离级别。
ꔷ 持久性(Durability)
Kafka 通过将事务状态写入到 __transaction_state Topic 和消息写入到日志文件中来保证持久性。
07 Kafka 事务的限制
从功能上看,Kafka 事务并不能支持业务方事务,强限制上游的消费和下游写入都需要是同一个 Kafka 集群,否则就不具备原子性保障。
从性能上看,Kafka 事务的性能开销主要体现在生产侧:
开启事务时需要额外的 RPC 请求定位 TransactionCoordinator 并初始化数据
消息发送需要在发送消息前向 TransactionCoordinator 同步请求添加分区,并将事务状态的变化写入到 __transaction_state Topic
事务提交或回滚时需要向所有参与事务的 Broker 发送请求
对于涉及分区较少且消息数量较多的事务,事务的开销可以被均摊;反之,较多的同步 RPC 带来的开销会极大影响性能。并且每个生产者只能有一个事务在进行中,这就意味着事务的吞吐量会受到限制。
消费侧也有一定的影响:消费者只能看到 LSO 以下的消息,并且需要额外的索引文件来过滤已回滚的消息,这无疑会增加端到端的延迟。
08 总结
通过本文的深入分析,我们了解到 Kafka 的事务消息功能是如何在流处理场景中提供 Exactly-Once 语义的。Kafka 通过其事务 API 和内部机制,实现了消息发送的原子性、最终一致性、隔离性和持久性,尽管在实际应用中可能存在一些性能和功能上的限制。开发者和架构师应当充分理解这些概念,并在设计系统时考虑如何有效地利用 Kafka 的事务功能,以构建更加健壮和可靠的数据处理流程。
AutoMQ 是构建于对象存储之上的云原生 Kafka fork,在解决了 Kafka 已有的成本和弹性问题基础上对 Kafka 100%兼容,因此在 AutoMQ 上也可以使用 Kafka 事务消息。AutoMQ 作为国内 Kafka 生态的忠实拥护者,我们将持续为 Kafka 技术爱好者带来优质的 Kafka 技术内容分享,欢迎关注我们。
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com
👀 B站:AutoMQ官方账号
🔍 视频号:AutoMQ
这篇关于Kafka Exactly Once 语义实现原理:幂等性与事务消息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





