本文主要是介绍Strassen矩阵乘法——C++,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【题目描述】
根据课本“Strassen矩阵乘法”的基本原理,设计并实现一个矩阵快速乘法的工具。并演示至少10000维的矩阵快速乘法对比样例。
【功能要求】
- 实现普通矩阵乘法算法和“Strassen矩阵乘法”算法
- 对相同的矩阵,分别用普通矩阵乘法算法,“Strassen矩阵乘法”算法和Matlab进行运算,比较时间差异(多次计算求平均值);
【选做功能】
- 突破2n的维数限制,能够对其他维数的矩阵进行运算。
- 方法不限,实现尽可能快的矩阵计算。
- 其他可扩展的功能。
【实验过程】
- 首先我们先设计实现普通的矩阵乘法,对于两个矩阵,普通的矩阵相乘做法是:遍历三层矩阵计算:我们设A和B是2个n*n的矩阵,它们的乘积AB同样是一个n*n矩阵。 A和B的乘积矩阵C中元素C[i][j]定义为:
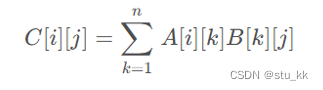
比如,我们以下列的例子作为参考: 对于它们的乘积,我们应该使用公式:
对于它们的乘积,我们应该使用公式:

所以,从上述的公式中,我们知道如果使用这正常的矩阵相乘,由此得出:

所以我们的计算的时间复杂度是O(n^3)。

计算的代码为:对于数据的输入,我们使用的是将数据存储在data.txt中,每次去读取这个文件中的矩阵规模n和矩阵 arr1[][] 和 arr2[][]
#include<iostream>
#include<time.h>
#include "fstream"
void Multiply(int pInt, long long **pInt1, long long **pInt2, long long **pInt3);void out(int pInt, long long **pInt1);using namespace std;int main() {system("chcp 65001 > nul");std::ios::sync_with_stdio(false);std::cin.tie(0);
// c++加速流int M;fstream f;f.open("data.txt",ios::in);f >> M;int length = M;if (M % 2 != 0) //若M为奇数,则补零{length++;}long long **A = new long long *[length];long long **B = new long long *[length];long long **C = new long long *[length];for (int i = 0; i < length; i++) {A[i] = new long long[length];B[i] = new long long[length];C[i] = new long long[length];}for (int i = 0; i < M; i++) {for (int j = 0; j < M; j++)f >> A[i][j];}for (int i = 0; i < M; i++) {for (int j = 0; j < M; j++) {C[i][j] = 0;f >> B[i][j];}}clock_t start;clock_t end;start = clock();Multiply(M, A, B, C);end = clock();cout <<"当数据量n为"<<M<<"时,耗费的时间:"<< (end - start) << "ms" << endl; //输出时间(单位:ms)
// out(M, C);}void out(int n, long long **arr) {for (int i = 0; i < n; i++) {for (int j = 0; j < n; j++) {cout << arr[i][j] << " ";}cout << endl;}
}void Multiply(int n, long long **A, long long **B, long long **C) {for (int i = 0; i < n; i++) {for (int j = 0; j < n; j++) {for (int k = 0; k < n; k++) {C[i][j] += A[i][k] * B[k][j];}}}
}
2. 观察这个算法之后,我们发现,在计算矩阵相乘的时候,时间复杂度达到了O(n^3)。 如果n过于大的话,需要计算很久才会出结果。对于10000 × 10000的数据量二维数组存储的话会爆栈。因此我们使用更加高效的算法:Strassen矩阵乘法。
3. 1969年,Volker Strassen提出了第一个算法时间复杂度低于O(n^3)的矩阵乘法算法,算法复杂度为![]() ,还是很接近3,因此StrassenStrassen 算法只有在对于维数比较大的矩阵,性能上才可能有优势,可以减少很多乘法计算。StrassenStrassen 算法证明了矩阵乘法存在时间复杂度低于O(n^3)的算法的存在,后续学者不断研究发现新的更快的算法,截止目前时间复杂度最低的矩阵乘法算法是 Coppersmith-Winograd 方法的一种扩展方法,其算法复杂度为
,还是很接近3,因此StrassenStrassen 算法只有在对于维数比较大的矩阵,性能上才可能有优势,可以减少很多乘法计算。StrassenStrassen 算法证明了矩阵乘法存在时间复杂度低于O(n^3)的算法的存在,后续学者不断研究发现新的更快的算法,截止目前时间复杂度最低的矩阵乘法算法是 Coppersmith-Winograd 方法的一种扩展方法,其算法复杂度为![]() ;
;
4. Strassen原理详解:
假设矩阵 A 和矩阵 B 都是 N×N (N = 2^n)的方矩阵,求 C = AB,如下所示:
![]()
其中,8T(2n) 表示 8 次矩阵乘法,而且相乘的矩阵规模降到了 2n。
O(![]() )表示 4 次矩阵加法的时间复杂度以及合并矩阵 C 的时间复杂度。
)表示 4 次矩阵加法的时间复杂度以及合并矩阵 C 的时间复杂度。
最终可计算得到 T(n)= O(![]() )。
)。
可以看出每次递归操作都需要 8 次矩阵相乘,而这正是瓶颈的来源。相比加法,矩阵乘法是非常慢的,于是减少矩阵相乘的次数就显得尤为重要。Strassen算法的主要目的其实也是从这个角度出发的,目的就是减少乘法次数,降低时间复杂度。
5. Strassen的实现步骤:
① 对于上述的A、B、C三个矩阵进行分解,分解花费的时间复杂度是O(1)
② 然后我们创建如下的10个![]() ×
× ![]() 的矩阵 S1 ,S2 ,S3 …… S10
的矩阵 S1 ,S2 ,S3 …… S10 ![]() ,花费的时间复杂大约是O(
,花费的时间复杂大约是O(![]() )
)

③ 接下来递归计算七个矩阵P1 ,P2 ,P3 …… P7 ![]() 每个P都是 n2
每个P都是 n2![]() × n2
× n2 ![]() 的矩阵。
的矩阵。

④ 接着通过Pi ![]() 来计算C11 、C12 、C21 、C22 ,花费的时间为O(
来计算C11 、C12 、C21 、C22 ,花费的时间为O(![]() )。
)。

这样就相对减少了一些时间复杂度。代码如下:
#include <iostream>
#include <time.h>
#include <fstream>
void out(int m, int **pInt);using namespace std;void subMatrix(int l, long long **m, long long **n, long long **ans) {for (int i = 0; i < l; i++) {for (int j = 0; j < l; j++) {ans[i][j] = m[i][j] - n[i][j];}}
}void addMatrix(int l, long long **m, long long **n, long long **ans) //两矩阵加法
{for (int i = 0; i < l; i++) {for (int j = 0; j < l; j++) {ans[i][j] = m[i][j] + n[i][j];}}
}void multiMatrix(int l, long long **m, long long **n, long long **ans) {for (int i = 0; i < l; i++) {for (int j = 0; j < l; j++) {ans[i][j] = 0;for (int k = 0; k < l; k++) {ans[i][j] += m[i][k] * n[k][j];}}}
}void Strassen(int M, long long **A, long long **B, long long **C) {int len = M / 2;long long **A11 = new long long *[len];long long **A12 = new long long *[len];long long **A21 = new long long *[len];long long **A22 = new long long *[len];long long **B11 = new long long *[len];long long **B12 = new long long *[len];long long **B21 = new long long *[len];long long **B22 = new long long *[len];long long **C11 = new long long *[len];long long **C12 = new long long *[len];long long **C21 = new long long *[len];long long **C22 = new long long *[len];long long **P1 = new long long *[len];long long **P2 = new long long *[len];long long **P3 = new long long *[len];long long **P4 = new long long *[len];long long **P5 = new long long *[len];long long **P6 = new long long *[len];long long **P7 = new long long *[len];long long **AR = new long long *[len];long long **BR = new long long *[len];for (int i = 0; i < len; i++) {A11[i] = new long long [len];A12[i] = new long long [len];A21[i] = new long long [len];A22[i] = new long long [len];B11[i] = new long long [len];B12[i] = new long long [len];B21[i] = new long long [len];B22[i] = new long long [len];C11[i] = new long long [len];C12[i] = new long long [len];C21[i] = new long long [len];C22[i] = new long long [len];P1[i] = new long long [len];P2[i] = new long long [len];P3[i] = new long long [len];P4[i] = new long long [len];P5[i] = new long long [len];P6[i] = new long long [len];P7[i] = new long long [len];AR[i] = new long long [len];BR[i] = new long long [len];}for (int i = 0; i < len; i++) {for (int j = 0; j < len; j++) {A11[i][j] = A[i][j];A12[i][j] = A[i][j + len];A21[i][j] = A[i + len][j];A22[i][j] = A[i + len][j + len];B11[i][j] = B[i][j];B12[i][j] = B[i][j + len];B21[i][j] = B[i + len][j];B22[i][j] = B[i + len][j + len];}}addMatrix(len, A11, A22, AR);addMatrix(len, B11, B22, BR);multiMatrix(len, AR, BR, P1);addMatrix(len, A21, A22, AR);multiMatrix(len, AR, B11, P2);subMatrix(len, B12, B22, BR);multiMatrix(len, A11, BR, P3);subMatrix(len, B21, B11, BR);multiMatrix(len, A22, BR, P4);addMatrix(len, A11, A12, AR);multiMatrix(len, AR, B22, P5);subMatrix(len, A21, A11, AR);addMatrix(len, B11, B12, BR);multiMatrix(len, AR, BR, P6);subMatrix(len, A12, A22, AR);addMatrix(len, B21, B22, BR);multiMatrix(len, AR, BR, P7);addMatrix(len, P1, P4, AR);subMatrix(len, P7, P5, BR);addMatrix(len, AR, BR, C11);addMatrix(len, P3, P5, C12);addMatrix(len, P2, P4, C21);addMatrix(len, P1, P3, AR);subMatrix(len, P6, P2, BR);addMatrix(len, AR, BR, C22);for (int i = 0; i < len; i++) {for (int j = 0; j < len; j++) {C[i][j] = C11[i][j];C[i][j + len] = C12[i][j];C[i + len][j] = C21[i][j];C[i + len][j + len] = C22[i][j];}}
}int main() {system("chcp 65001 > nul");std::ios::sync_with_stdio(false);std::cin.tie(0);
// c++加速流int M;fstream f;f.open("data.txt",ios::in);f >> M;int length = M;if (M % 2 != 0) //若M为奇数,则补零{length++;}long long **A = new long long *[length];long long **B = new long long *[length];long long **C = new long long *[length];for (int i = 0; i < length; i++) {A[i] = new long long [length];B[i] = new long long [length];C[i] = new long long [length];}for (int i = 0; i < M; i++) {for (int j = 0; j < M; j++)f >> A[i][j];}for (int i = 0; i < M; i++) {for (int j = 0; j < M; j++) {f >> B[i][j];}}if (length > M) {for (int i = 0; i < length; i++) {A[i][M] = 0;A[M][i] = 0;B[i][M] = 0;B[M][i] = 0;}}clock_t start;clock_t end;start = clock();Strassen(length, A, B, C);end = clock();cout <<"当数据量n为"<<M<<"时,耗费的时间:"<< (end - start) << "ms" << endl; //输出时间(单位:ms)
// 输出
// out(M,C);return 0;
}void out(int M, int **C) {for (int i = 0; i < M; i++){for (int j = 0; j < M; j++){cout << C[i][j] << " \n"[j == M - 1];}}
}
接着,我们通过改变数据量的大小,来比较这两个算法的耗时。
对于测试数据的生成,我们使用makeData.cpp来生成并保存到文件data.txt。代码如下:
//简单的随机制造数据
#include<iostream>
#include <ctime>
#include "stdlib.h"
#include "fstream"
using namespace std;
// 左闭右闭区间
int getRand(int min, int max) {return (rand() % (max - min + 1)) + min;
}int main() {int n;cin >> n;fstream f;f.open("data.txt", ios::out);f << n << endl;srand(time(0));for (int i = 0; i < 2 * n; i++) {for (int j = 0; j < n; j++) {f << getRand(0, 10) << " ";}f << endl;}f.close();return 0;
}
我们使用了上述的矩阵生成代码,随机创建了10000×10000大小的矩阵进行测试,如下图所示:
计算得到结果:

我们再使用Matlab来计算一下两个矩阵相乘的耗时:

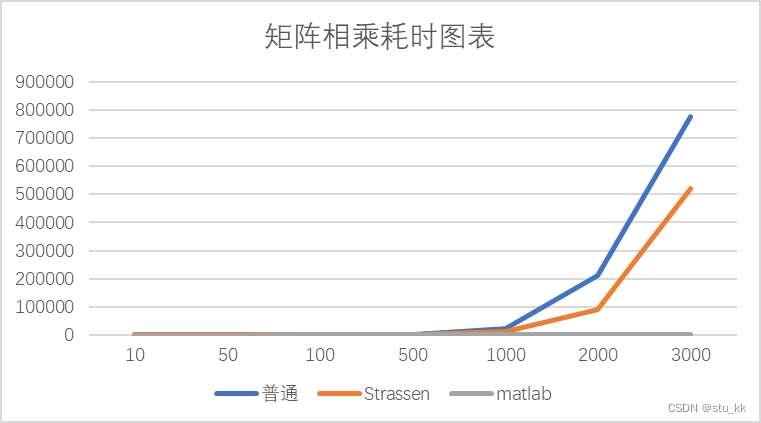
统计得到:(其中的数据都是由3次统计求平均值的方式得来的。)
| 数据量 | 10 | 50 | 100 | 500 | 1000 | 2000 | 3000 |
| 普通 | 0 | 0.7 | 17.5 | 1644.667 | 20423.67 | 209913.5 | 779112 |
| Strassen | 0 | 2.5 | 11.5 | 1426 | 11692.67 | 90211.33 | 521274 |
| matlab | 0 | 0.185 | 0.328 | 2.926 | 16.38 | 237.273 | 407.674 |
【实验结论】
最后,比较得出结论:
1. 在矩阵规模较小的情况下,(例如 n<64),普通的矩阵相乘算法表现更优,耗时更短。
2. 当矩阵规模较大时,Strassen算法表现更优,耗时更短。因为在矩阵规模较大时,Strassen算法所需的递归次数相对较少,而且该算法每一次递归所做的运算规模较小,这些都有利于提高运算效率。
3. 在Matlab中,可以使用自带的矩阵乘法函数*来进行矩阵相乘运算,该函数会根据矩阵规模和计算机硬件等情况自动选择最优算法进行计算。因此,在实际应用中,建议使用内置的矩阵乘法函数。
这篇关于Strassen矩阵乘法——C++的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






