本文主要是介绍C++可变参数接口,批量写入和读取参数值的设计和实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
相关文章系列
手撕代码: C++实现数据的序列化和反序列化-CSDN博客
目录
1.需求
2.问题分析
3.解决方案
3.1.类型抽象
3.2.参数配置
3.3.参数读取
1.需求
最近在做项目的时候,我们小组做的模块和另外一个小组做的模块的交付通过动态库接口的方式,他们有一个接口是这样的定义的:
//配置参数
int writeParam(const char* name, const char* data, int len);//读取参数
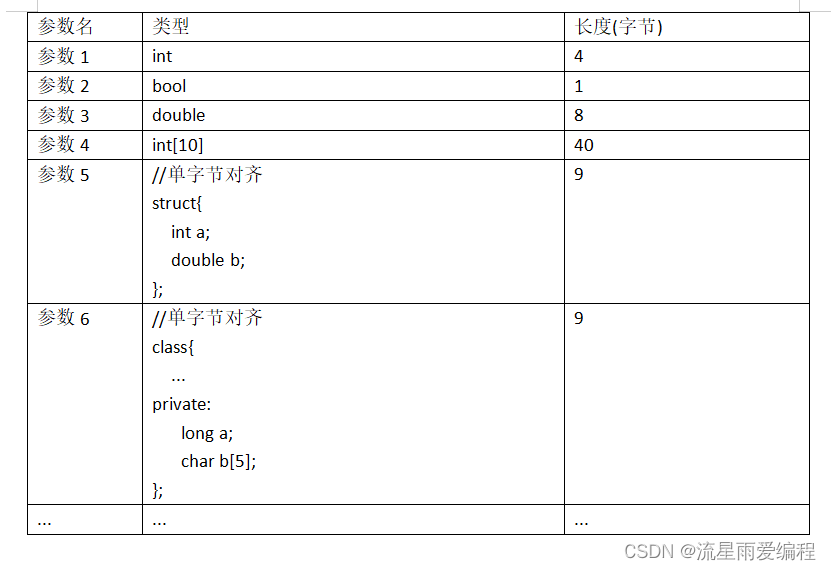
int readParam(const char* name, char* data, int len);name是参数名称,data为序列化的字节数据,小端对齐,数据类型包括一般数据类型int、long、double等;复杂数据类型包括原生数组、结构体、类等。例如:
手撕代码: C++实现数据的序列化和反序列化-CSDN博客
单个参数的配置和读取都很简单,利用之前章节介绍的序列化类,
参数配置可以这样写:
参数1(int)的配置代码如下:
#include "ByteArray.h"
#include "DataStream.h"//【1】配置参数
//[1.1] 序列化 int
int write(const char* name, int value)
{CByteArray byteArray;CDataStream dataStream(&byteArray);dataStream << value;return writeParam(name, byteArray.data(), byteArray.size());
}
参数2(bool)的配置代码如下:
#include "ByteArray.h"
#include "DataStream.h"//【1】配置参数
//[1.2] 序列化 bool
int write(const char* name, bool value)
{return writeParam(name, (char*)&value, sizeof(value));
}参数3(double)的配置代码如下:
#include "ByteArray.h"
#include "DataStream.h"//【1】配置参数
//[1.3] 序列化 double
int write(const char* name, double value)
{CByteArray byteArray;CDataStream dataStream(&byteArray);dataStream << value;return writeParam(name, byteArray.data(), byteArray.size());
}参数4(int[10])的配置代码如下:
#include "ByteArray.h"
#include "DataStream.h"//【1】配置参数
//[1.4] 序列化数组 int[]
int write(const char* name, int* value, int len)
{CByteArray byteArray;CDataStream dataStream(&byteArray);for (int i = 0; i < len; i++){dataStream << value[i];}return writeParam(name, byteArray.data(), byteArray.size());
}参数5(结构体)的配置代码如下:
#include "ByteArray.h"
#include "DataStream.h"typedef struct _stControl
{int a;double b;
public:_stControl(){memset(this, 0x00, sizeof(_stControl));}static quint16 getDataSize() {return sizeof(_stControl);}QString toString() const {return QString("端机控制:%1").arg((int)type);}friend QDataStream& operator<<(QDataStream& dataStream, const _stControl& data) //序列化{dataStream << data.a;dataStream << data.b;return dataStream;}friend QDataStream& operator>>(QDataStream& dataStream, _stControl& data) //反序列化{dataStream >> data.a;dataStream >> data.b;return dataStream;}
}stControl;//【1】配置参数
//[1.5] 序列化结构体
int write(const char* name, const stControl& value)
{CByteArray byteArray;CDataStream dataStream(&byteArray);dataStream << value;return writeParam(name, byteArray.data(), byteArray.size());
}参数6(类)的配置和参数5的配置差不多,就不在这里赘述了。
参数读取可以这样写:
参数1(int)的读取代码如下:
#include "ByteArray.h"
#include "DataStream.h"
#include <memory>//【2】读取参数
//[2.1] 反序列化 int
int read(const char* name, int& value)
{std::unique_ptr<char[]> pData(new char[256]);int result = readParam(name, pData.get(), 256);if (result > 0){//读取成功CByteArray byteArray(pData.get(), result);CDataStream dataStream(&byteArray);dataStream >> value;return 0;}return -1;
}
参数2(bool)的读取代码如下:
#include "ByteArray.h"
#include "DataStream.h"
#include <memory>//【2】读取参数
//[2.2] 反序列化 bool
int read(const char* name, bool& value)
{ if (readParam(name, (char*)&value, 1) > 0){ //读取成功return 0;}return -1;
}参数3(double)的读取代码如下:
#include "ByteArray.h"
#include "DataStream.h"
#include <memory>//【2】读取参数
//[2.3] 反序列化 double
int read(const char* name, double& value)
{std::unique_ptr<char[]> pData(new char[256]);int result = readParam(name, pData.get(), 256);if (result > 0){ //读取成功CByteArray byteArray(pData.get(), result);CDataStream dataStream(&byteArray);dataStream >> value;return 0;}return -1;
}参数4(int[10])的读取代码如下:
#include "ByteArray.h"
#include "DataStream.h"
#include <memory>//【2】读取参数
//[2.4] 反序列化 int [10]
int read(const char* name, int* pValue, int len)
{std::unique_ptr<char[]> pData(new char[256]);int result = readParam(name, pData.get(), 256);if (result > 0){//读取成功CByteArray byteArray(pData.get(), sizeof(value));CDataStream dataStream(&byteArray);for (int i = 0; i < len; i++){dataStream >> pValue[i];}return 0;}return -1;
}参数5(结构体)的读取代码如下:
#include "ByteArray.h"
#include "DataStream.h"typedef struct _stControl
{int a;double b;
public:_stControl(){memset(this, 0x00, sizeof(_stControl));}static quint16 getDataSize() {return sizeof(_stControl);}QString toString() const {return QString("端机控制:%1").arg((int)type);}friend QDataStream& operator<<(QDataStream& dataStream, const _stControl& data) //序列化{dataStream << data.a;dataStream << data.b;return dataStream;}friend QDataStream& operator>>(QDataStream& dataStream, _stControl& data) //反序列化{dataStream >> data.a;dataStream >> data.b;return dataStream;}
}stControl;//【2】读取参数
//[2.5] 反序列化结构体
int read(const char* name, stControl& value)
{std::unique_ptr<char[]> pData(new char[256]);int result = readParam(name, pData.get(), 256);if (result > 0){ //读取成功CByteArray byteArray(pData.get(), sizeof(value));CDataStream dataStream(&byteArray);dataStream >> value;return 0;}return -1;
}参数6(类)的读取和参数5的读取差不多,就不在这里赘述了。
2.问题分析
从上面的需求和简单实现来看,不难得出以下几个结论:
1)不同的数据类型需要写个不同的实现函数,如果包括结构体和类,那就需要写非常多的实现函数,代码会出现急剧膨胀。
2)随着需求的变更,可能增加新的数据类型,那就得重写新的实现的函数,对扩展功能不友好。
3)很难实现批量操作,而且还会出现非常多的if-else-if条件判断。
那么出现这些,怎么去解决呢?我们继续往下看。
3.解决方案
3.1.类型抽象
从第1章节我们可以归纳出3种数据类型:简单数据类型(bool、int、double、结构体和类);字符串std::string(字符数组char[]除外)、数组(包括字符数组和其他类型的数组)。于是我们可以抽象出基类来,代码如下:
//抽象参数类
class IParamField
{
public:virtual ~IParamField() {}virtual CByteArray toByteArray() const = 0; //序列化数据virtual bool parseData(const char* pData, PUInt64 len) = 0; //反序列化数据virtual IParamField* clone() const = 0; //克隆对象
};简单数据类型(bool、int、double、结构体和类)定义为:
template<typename T>
class CBasicParamField : public IParamField
{
public:explicit CBasicParamField(const T value) : m_value(value) {}CByteArray toByteArray() const override {CByteArray data;CDataStream dataStream(&data);dataStream << m_value;return data;}bool parseData(const char* pData, PUInt64 len) override {assert(len == sizeof(T));CByteArray data(pData, len);CDataStream dataStream(&data);dataStream >> m_value;return true;}IParamField* clone() const override {return new CBasicParamField<T>(m_value);}T value() const { return m_value; }
private:T m_value;
};字符串std::string(字符数组char[]除外)定义为:
template<>
class CBasicParamField<std::string>
{
public:explicit CBasicParamField(const std::string& value = "") : m_value(value) {}CByteArray toByteArray() const {CByteArray data;data.writeRawData(m_value.data(), m_value.size());return data;}bool parseData(const char* pData, PUInt64 len) {m_value.clear();m_value.append(pData, len);return true;}
private:std::string m_value;
};数组(包括字符数组和其他类型的数组)定义为:
template<typename T, size_t N>
class CArrayParamField : public IParamField
{
public:explicit CArrayParamField(const T(&value)[N]) {for (int i = 0; i < N; i++) {m_value[i] = value[i];}}CByteArray toByteArray() const override {CByteArray data;CDataStream dataStream(&data);for (auto& it : m_value) {dataStream << it;}return data;}bool parseData(const char* pData, PUInt64 len) override {assert(len == sizeof(m_value));CByteArray data(pData, len);CDataStream dataStream(&data);for (auto& it : m_value) {dataStream >> it;}return true;}IParamField* clone() const override {return new CArrayParamField<T, N>(m_value);}std::array<T, N> value() const { return m_value; }
private:T m_value[N];
};3.2.参数配置
有了上面的类定义,我们就可以写一个函数批量写入参数,代码如下:
//参数容器定义
using ParamContainer = std::map<std::string, std::shared_ptr<IParamField>>;//批量读取参数函数
int batchWrite(const ParamContainer& vecParams)
{int result = -1;CByteArray data;for (auto& it : vecParams){data = it.second->toByteArray();result &= writeParam(it.first.data(), data.data(), data.size());}return result;
}测试代码如下:
int main()
{ParamContainer vecParams;vecParams["param1"] = std::make_shared<CBasicParamField<int>>(199);vecParams["param2"] = std::make_shared<CBasicParamField<bool>>(false);vecParams["param3"] = std::make_shared<CBasicParamField<double>>(45.856);vecParams["param4"] = std::make_shared<CArrayParamField<int,10>>({4,1,4,6,7,33,54,66,77,888});vecParams["param5"] = std::make_shared<CBasicParamField<stControl>>({2, 86.85});return batchWrite(vecParams);
}3.3.参数读取
同样,我们仿照可以写出函数批量读取参数,代码如下:
//批量读取参数函数
int batchRead(ParamContainer& vecParams)
{int result = -1;std::unique_ptr<char[]> pData(new char[256]);for (auto& it : vecParams){result = readParam(it.first.data(), pData.get(), 256);if (result > 0){it.second->parseData(pData.get(), result); }}return result;
}测试代码和参数配置的差不多,这里就不多赘述了。
这篇关于C++可变参数接口,批量写入和读取参数值的设计和实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





