本文主要是介绍Spark核心名词解释与编程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Spark核心概念
名词解释
1)ClusterManager:在Standalone(上述安装的模式,也就是依托于spark集群本身)模式中即为Master(主节点),控制整个集群,监控Worker。在YARN模式中为资源管理器ResourceManager(国内spark主要基于yarn集群运行,欧美主要基于mesos来运行)。
2)Application:Spark的应用程序,包含一个Driver program和若干Executor。
3)SparkConf:负责存储配置信息。作用相当于hadoop中的Configuration。
4)SparkContext:Spark应用程序的入口,负责调度各个运算资源,协调各个Worker Node上的Executor。
5)Worker:从节点,负责控制计算节点,启动Executor。在YARN模式中为NodeManager,负责计算节点的控制,启动的进程叫Container。
6)Driver:运行Application的main()函数并创建SparkContext(是spark中最重要的一个概念,是spark编程的入口,作用相当于mr中的Job)。
7)Executor:执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executors。
8)RDD:Spark的基本计算单元,一组RDD可形成执行的有向无环图RDD Graph。
9)RDD是弹性式分布式数据集,理解从3个方面去说:弹性、数据集、分布式。是Spark的第一代的编程模型。
10)DAGScheduler:实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Taskset放到TaskScheduler中。DAGScheduler就是Spark的大脑,中枢神经。
11)TaskScheduler:将任务(Task)分发给Executor执行。
12)Stage:一个Spark作业一般包含一到多个Stage。
13)Task:一个Stage包含一到多个Task,通过多个Task实现并行运行的功能。task的个数由rdd的partition分区决定,spark是一个分布式计算程序,所以一个大的计算任务,就会被拆分成多个小的部分,同时进行计算。一个partition对应一个task任务。
14)Transformations:转换(Transformations) (如:map, filter, groupBy, join等),Transformations操作是Lazy的,也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,Spark在遇到Transformations操作时只会记录需要这样的操作,并不会去执行,需要等到有Actions操作的时候才会真正启动计算过程进行计算。
15)Actions:操作/行动(Actions)算子 (如:count, collect, foreach等),Actions操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。
Spark官网组件说明
官网组件说明如图-18所示:
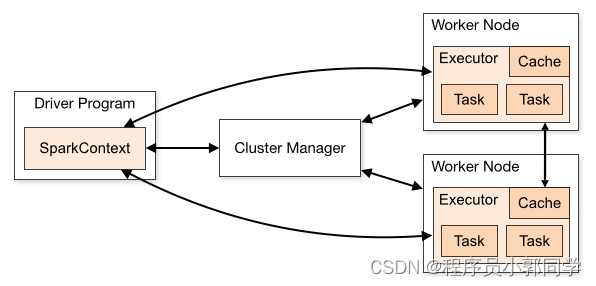
图-18 Spark组件通信架构图
Spark应用程序作为集群上的独立进程集运行,由主程序(称为驱动程序)中的SparkContext对象协调。
具体来说,要在集群上运行,SparkContext可以连接到几种类型的集群管理器(Spark自己的独立集群管理器、Mesos或YARN),这些管理器可以跨应用程序分配资源。一旦连接,Spark将获取集群中节点上的执行器,这些执行器是为应用程序运行计算和存储数据的进程。接下来,它将应用程序代码(由传递给SparkContext的JAR或Python文件定义)发送给执行器。最后,SparkContext将任务发送给执行器以运行。
Spark编程体验
项目依赖管理
<dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.12.10</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.2.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.2.1</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.23</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>3.2.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.2.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.2.1</version></dependency>
</dependencies><build><finalName>chapter1.WordCount</finalName><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.4.6</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins>
</build>项目编码
spark入门程序wordcount:
package com.fesco.bigdata.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/*** scala版本的wordcount*/
object ScalaWordCountApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${ScalaWordCountApp.getClass.getSimpleName}")
.setMaster("local[*]")
val sc = new SparkContext(conf)
//加载数据
val file: RDD[String] = sc.textFile("file:/E:/data/spark/hello.txt")//按照分隔符进行切分
val words:RDD[String] = lines.flatMap(line => line.split("\\s+"))//每个单词记为1次
val pairs:RDD[(String, Int)] = words.map(word => (word, 1))//聚合数据
val ret:RDD[(String, Int)] = pairs.reduceByKey(myReduceFunc)
//export data to external system
ret.foreach(println)}
sc.stop()
}
def myReduceFunc(v1: Int, v2: Int): Int = {
v1 + v2
}
}Master URL说明
首先在编程过程中,至少需要给spark程序传递一个参数master-url,通过sparkConf.setMaster来完成。改参数,代表的是spark作业的执行方式,或者指定的spark程序的cluster-manager的类型。
表-1 模式选择
| master | 含义 | |
| local | 程序在本地运行,同时为本地程序提供一个线程来处理 | |
| local[M] | 程序在本地运行,同时为本地程序分配M个工作线程 来处理 | |
| local[*] | 程序在本地运行,同时为本地程序分配机器可用的CPU core的个数工作线程来处理 | |
| local[M, N] | 程序在本地运行,同时为本地程序分配M个工作线程来处理,如果提交程序失败,会进行最多N次的重试 | |
| spark://ip:port |
| |
| spark://ip1:port1,ip2:port2 | 基于standalone的ha模式运行,提交撑到ip对应的master上运行 | |
| yarn/启动脚本中的deploy-mode配置为cluster | 基于yarn模式的cluster方式运行,SparkContext的创建在NodeManager上面,在yarn集群中 | |
| yarn/启动脚本中的deploy-mode配置为client | 基于yarn模式的client方式运行,SparkContext的创建在提交程序的那台机器上面,不在yarn集群中 |
spark程序的其他提交方式
加载hdfs中的文件:
object RemoteSparkWordCountOps {def main(args: Array[String]): Unit = {//创建程序入口val conf = new SparkConf().setAppName("wc").setMaster("local[*]")val sc = new SparkContext(conf)//设置日志级别sc.setLogLevel("WARN")//加载数据val file = sc.textFile("hdfs://hadoop101:8020//wordcount//words.txt")//切分val spliFile: RDD[String] = file.flatMap(_.split(" "))//每个单词记为1次val wordAndOne: RDD[(String, Int)] = spliFile.map((_, 1))//聚合val wordAndCount: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _)//打印输出wordAndCount.foreach(println)//释放资源sc.stop()
}}提交spark程序到集群中
首先需要将spark-core模块进行打包,其次上传到集群中,才可以进行提交作业到spark或者yarn集群中运行。
1)Client:
bin/spark-submit \--class chapter1.WordCount \--master spark://hadoop101:7077 \/root/word.jar \hdfs://hadoop101:8020/wordcount/words.txt2)Cluster:
bin/spark-submit \--class chapter1.WordCount \--master spark://hadoop101:7077 \/root/word.jar \hdfs://hadoop101:8020/wordcount/words.txt \hdfs://hadoop101:8020/wordcount/output1这篇关于Spark核心名词解释与编程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




