本文主要是介绍详解 ROS 近似时间戳同步 ApproximateTime,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ApproximateTime
功能介绍
message_filters::sync_policies::ApproximateTime 策略使用自适应算法根据时间戳来匹配多个Topic消息。
ApproximateTime根据时间戳来进行匹配,因此Topic的消息类型必须包含Header字段【C++】。
以下补充属性
- 以同步两个Topic为例,ApproximateTime至少会保证其中一个Topic中的消息不会被丢失。另一个Topic的消息可能会被丢失。
- 匹配完全按照Header字段中的stamp时间戳进行同步,和消息到来的时间顺序无关。
- 同步的一组Topic不能有重复
使用案例
示例代码
GitHup : https://github.com/SeekyChan/ApproximateTime_demo.git
创建两个ROS Node(time_01_node time_02_node),发布两个Topic分别为 : "timestamp_02_topic" 和 "timestamp_02_topic",两个Topic间隔 1 s 发送一次 sensor_msgs::PointCloud2 消息,时间戳为当前系统的时间戳。
创建ROS Node(sync_node) 订阅并同步两个topic的消息,同时打印信息。
三个节点的代码如下:
time_01_node
#include "ros/ros.h"
#include "std_msgs/Header.h"
#include <sensor_msgs/PointCloud2.h>
#include <ctime>int main(int argc, char **argv)
{// 初始化ROS节点ros::init(argc, argv, "timestamp_publisher");// 创建节点句柄ros::NodeHandle n;ros::Publisher pub = n.advertise<sensor_msgs::PointCloud2>("timestamp_01_topic", 10);// 设置发布频率,这里设定为每秒1次ros::Rate loop_rate(1);int count = 0;while (ros::ok()){// 获取当前系统时间戳sensor_msgs::PointCloud2 cloud_msg;// 设置消息的元数据cloud_msg.header.frame_id = "time_01_node"; cloud_msg.header.stamp = ros::Time::now(); // 设置时间戳cloud_msg.header.seq = count;// 发布消息pub.publish(cloud_msg);// 输出当前时间戳//ROS_INFO("time_01_node publishing timestamp: %f", cloud_msg.header.stamp.toSec());// 递增count值count++;// 延时以达到指定的发布频率loop_rate.sleep();}return 0;
}
time_02_node
#include "ros/ros.h"
#include "std_msgs/Header.h"
#include <sensor_msgs/PointCloud2.h>
#include <ctime>int main(int argc, char **argv)
{// 初始化ROS节点ros::init(argc, argv, "timestamp_publisher");// 创建节点句柄ros::NodeHandle n;ros::Publisher pub = n.advertise<sensor_msgs::PointCloud2>("timestamp_02_topic", 10);// 设置发布频率,这里设定为每秒1次ros::Rate loop_rate(1);int count = 0;while (ros::ok()){// 获取当前系统时间戳sensor_msgs::PointCloud2 cloud_msg;// 设置消息的元数据cloud_msg.header.frame_id = "time_02_node"; cloud_msg.header.stamp = ros::Time::now(); // 设置时间戳cloud_msg.header.seq = count;// 发布消息pub.publish(cloud_msg);// 输出当前时间戳//ROS_INFO("time_02_node publishing timestamp: %f", cloud_msg.header.stamp.toSec());// 递增count值count++;// 延时以达到指定的发布频率loop_rate.sleep();}return 0;
}
sync_node
#include "ros/ros.h"
#include "std_msgs/Header.h"
#include <sensor_msgs/PointCloud2.h>#include <message_filters/subscriber.h>
#include <message_filters/time_synchronizer.h>
#include <message_filters/sync_policies/approximate_time.h>void callback(const sensor_msgs::PointCloud2::ConstPtr& msg1, const sensor_msgs::PointCloud2::ConstPtr& msg2) {// 打印消息的时间戳ROS_INFO("Received timestamps: topic1: %f, topic2: %f", msg1->header.stamp.toSec(), msg2->header.stamp.toSec());// 计算时间戳的差值(绝对值)double timestamp_diff = fabs(msg1->header.stamp.toSec() - msg2->header.stamp.toSec());ROS_INFO("Timestamp difference: %f seconds ,node_1 seq : %d , node_1 seq : %d", timestamp_diff,msg1->header.seq,msg2->header.seq);
}int main(int argc, char **argv) {// 初始化 ROS 节点ros::init(argc, argv, "timestamp_sync_node");// 创建节点句柄ros::NodeHandle nh;//订阅两个话题message_filters::Subscriber<sensor_msgs::PointCloud2> sub1(nh, "timestamp_01_topic", 5);message_filters::Subscriber<sensor_msgs::PointCloud2> sub2(nh, "timestamp_02_topic", 5);typedef message_filters::sync_policies::ApproximateTime<sensor_msgs::PointCloud2,sensor_msgs::PointCloud2> syncPolicy; //近似同步策略message_filters::Synchronizer<syncPolicy> sync(syncPolicy(10), sub1, sub2);// 同步sync.registerCallback(boost::bind(&callback, _1, _2));// 循环等待回调ros::spin();return 0;
}
运行结果

从结果可以看到,两个Topic的消息都一一同步并都打印出来了。因为我们两个节点发布的消息都是每隔一秒发送一个当前时间戳的消息,因此两个Topic的消息的时间戳几乎是完全一致的,因此全部一一匹配也在意料之中。
设置匹配下限
假设我们此时更改 time_02_node 节点,将每隔 1 s 发送 的时间戳改为 当前时间戳 + 5s,其他节点代码保持不变。
cloud_msg.header.frame_id = "time_02_node";
cloud_msg.header.stamp = ros::Time::now() + ros::Duration(5); // 设置时间戳运行结果
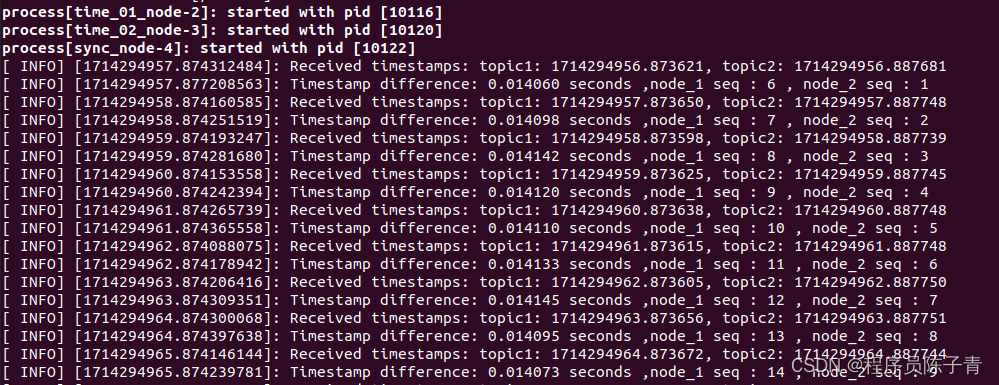
此时我们看到,time_01_node 的前5s的消息被丢弃了,从time_01_node的第 6 个消息开始与 time_02_node 的第一个消息进行匹配。
如果我们更改需求,设time_01_node 和 time_02_node 两个节点的消息时间相差时间不超过5s就算作匹配,那么time_01_node的第一个消息与time_02_node的第一个消息时间戳上就是匹配的,不应该被丢弃。此时我们可以使用 setInterMessageLowerBound 来设置匹配允许的误差。
更改sync_node的代码如下:
sync.setInterMessageLowerBound(ros::Duration(10,0));sync.registerCallback(boost::bind(&callback, _1, _2));此时观察运行结果
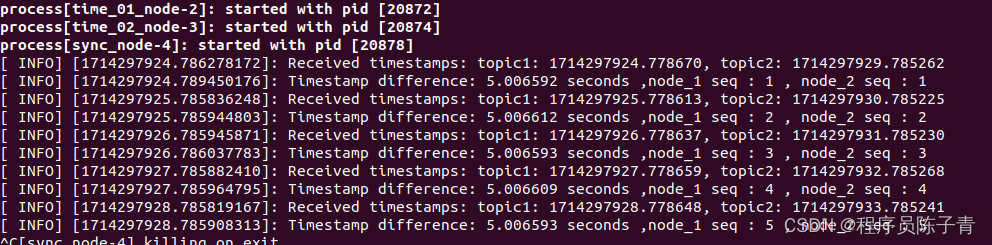
消息再次一一对应了。
消息同步的队列大小
例程中Synchronizer的queue_size 设为 10
message_filters::Synchronizer<syncPolicy> sync(syncPolicy(10), sub1, sub2);// 同步
具体的含义是什么呢?

上图中两条线分别代表两个Topic , queue_size 指的是 每一个Topic最多进来多少个点作为匹配的集合。如果在消息进入的点的数量达到设置定的队列大小数量还没有相应时间戳匹配成功,那么则丢弃当前的点进行下一轮匹配。以上文示例代码的程序为例,如果设为syncPolicy(5),而 time_02_node 节点每隔 1 s 发送 的时间戳为 当前时间戳 + 5s,在不设置匹配下限的情况下,意味着在Topic的消息队列的集合为 5 的范围内则时间戳永不匹配。
这篇关于详解 ROS 近似时间戳同步 ApproximateTime的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





