本文主要是介绍Sarcasm detection论文解析 | 通过阅读进行讽刺推理-Reasoning with sarcasm by reading in-between,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址
论文地址:[1805.02856] Reasoning with Sarcasm by Reading In-between (arxiv.org)
论文首页

笔记大纲

通过阅读进行讽刺推理论文笔记
📅出版年份:2018
📖出版期刊:
📈影响因子:
🧑文章作者:Tay Yi,Luu Anh Tuan,Hui Siu Cheung,Su Jian
🔎摘要:
讽刺是一种复杂的语言行为,常见于 Twitter 和 Reddit 等社交社区。由于讽刺不仅具有极性翻转的倾向,而且还使用了形象化的语言,因此在社交网络上盛行的讽刺对意见挖掘系统具有很大的破坏性。讽刺通常表现为正面-负面情绪或字面-具象场景之间的对比主题。在本文中,我们重新审视了对比建模的概念,以便对讽刺进行推理。更具体地说,我们提出了一种基于注意力的神经模型,该模型关注的是 "中间 "而不是 "对面",从而能够明确地对对比和不协调进行建模。我们在 Twitter、Reddit 和互联网论证语料库(Internet Argument Corpus)的六个基准数据集上进行了广泛的实验。我们提出的模型不仅在所有数据集上都达到了最先进的性能,而且还提高了可解释性。
🌐研究目的:
对讽刺进行推理
📰研究背景:
由于讽刺不仅具有极性翻转的倾向,而且还使用了形象化的语言,因此在社交网络上盛行的讽刺对意见挖掘系统具有很大的破坏性。讽刺通常表现为正面-负面情绪或字面-具象场景之间的对比主题。
🔬研究方法:
将内部注意力应用于讽刺语言检测
🔩模型架构:
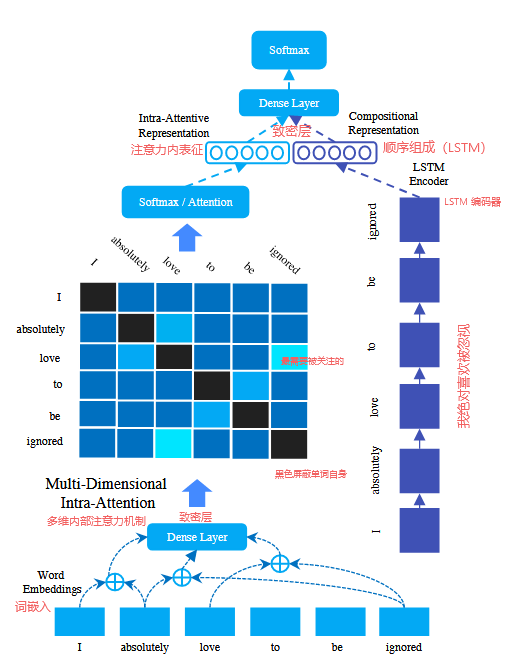
输入编码层
每个单击编码向量对应词汇表中的一个单词。在输入编码层,每个单击向量被转换成低维向量表示(词嵌入)
多维内部注意力机制
- 这一层背后的关键思想是对输入序列中每个单词之间的语义进行建模。我们首先对输入序列中每对词之间的关系进行建模。实现这一点的简单方法是使用线性(早期实验发现,在此处添加非线性可能会降低性能。)转换层,将每个词嵌入对的连接投射到一个标量分数中。
- 为了学习注意力向量 a,我们在矩阵 s 上应用了行向最大池化算子。
- 值得注意的是,我们还屏蔽了 i = j 时的 s 值,这样就不会让单词与自身的关系得分影响整体注意力权重
- 我们的网络可被视为神经注意的 "内部 "调整,可模拟原始单词表征之间的句内关系。
- 多维度的内部关注机制。这里的关键思路是,在计算亲和度得分之前,先将每个词对向下投影为一个低维向量,这样不仅可以捕捉一个视图(一个标量),还可以捕捉多个视图。对等式 (1) 的修改构成了我们的多维内部关注变体。
长短期记忆编码器(LSTM)
- 单独的组合编码器(即学习组合表征)
- 采用了标准的长短期记忆(LSTM)编码器,LSTM 编码器由通过非线性变换学习到的门控机制参数化。
预测层
- 其中多维内部注意力机制与LSTM编码器是并联关系
- 该层使用非线性投影层ReLU学习这两个视图的联合表示。
🧪实验:
📏评估指标:
采用了讽刺语言检测任务的标准评估指标,即宏观平均 F1 和准确率得分。此外,我们还报告了精确度和召回分数。
📇数据集:
Twitter、Red-dit 和 Debates 数据集

💻实验设备:
NVIDIA GTX1070 GPU
📋实验结果:
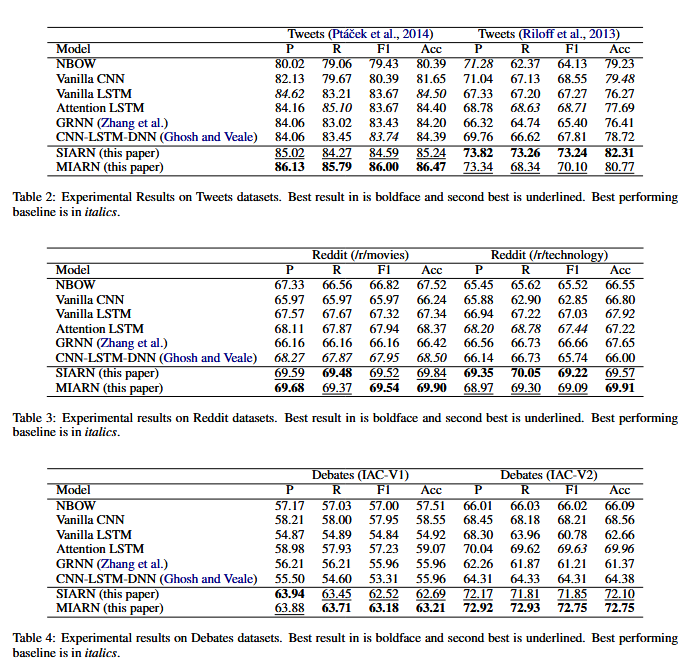
我们发现,我们提出的 SIARN 和 MIARN 模型在所有六个数据集上都取得了最佳结果。
- 2014 TWeets:与最佳基线相比,MIARN 的 F1 和准确率得分提高了约 ≈ 2% - 2.2%。
- 2013TWeets:比大多数基线平均提高 3% - 5%。
- Reddit 数据集:与最佳基线相比,平均差值提高了 ≈ 2%。
- Debates 长文本数据集:在 IAC-V1 和 IAC-V2 上,MIARN 的性能比 GRNN 和 CNN-LSTM-DNN 高出≈8%-10%。
总体而言,MIARN 的性能通常略高于 SIARN(但也有例外,例如来自 (Riloff et al., 2013) 的 Tweets 数据集)
我们提出的模型在长文本上的表现也要好得多,这可以归因于注意内表征明确地模拟了长距离的依赖关系。
🚩研究结论:
基于句子内部相似性(即在句子之间寻找)的直觉,我们提出了一种新的讽刺检测神经网络架构。我们的网络包含一个多维注意内分量,可学习句子的注意内表征,使其能够检测对比情感、情况和不协调性。
在六个公共基准上进行的广泛实验证实了我们提出的模型的实证有效性。我们提出的 MIARN 模型优于 GRNN 和 CNN-LSTM-DNN 等最先进的基线模型。
📝总结
💡创新点:
- 我们的网络可被视为神经注意力的 "内部 "调整,可模拟原始单词表征之间的句内关系。
- 多维度的内部注意力机制
- 提出的 MIARN 架构的高层概览。
- 多维内部注意力机制与LSTM编码器并联
⚠局限性:
- 在短文方面,我们还发现注意力(或 GRNN 的门控池机制)并没有真正帮助我们在普通 LSTM 模型的基础上取得任何显著的改进。
- 标准神经注意没有帮助的原因,是因为注意机制学习的是选择最后一个表征(即 vanilla LSTM)。如果没有 LSTM 编码器,注意力权重就会集中在 "爱 "上,而不是 "忽略"。这就无法捕捉到任何对比或不协调的概念。
总的来说,我们发现 MIARN 能够识别句子中的对比和不协调,从而使我们的模型能够更好地检测讽刺。句子内部关系建模有助于实现这一点。值得注意的是,标准香草注意力无法解释或解释。
🖍️知识补充:
- 在 NLP 的语境中,神经注意的关键理念是根据单词对当前任务的相对重要性来软性选择单词序列
- 对于相对较短的文档(如推文)来说,直观地看,注意力通常会集中在最后一个隐藏表征上。
- LSTM 编码器的输入是输入编码层之后的词嵌入,而不是注意内层的输出
💬讨论:
- 我们提出的模型不仅在所有数据集上都达到了最先进的性能,而且还提高了可解释性。
- 我们的工作不仅是第一项将内部注意力应用于讽刺语言检测的工作,也是第一项用于讽刺语言检测的注意力模型。
这篇关于Sarcasm detection论文解析 | 通过阅读进行讽刺推理-Reasoning with sarcasm by reading in-between的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






