本文主要是介绍YOLOv8优改系列二:YOLOv8融合ATSS标签分配策略,实现网络快速涨点,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

💥 💥💥 💥💥 💥💥 💥💥神经网络专栏改进完整目录:点击
💗 只需订阅一个专栏即可享用所有网络改进内容,每周定时更新
文章内容:针对YOLOv8的Neck部分融合ATSS标签分配策略,实现网络快速涨点!!!
推荐指数(满分五星):⭐️⭐️⭐️⭐️⭐️
涨点指数(满分五星):⭐️⭐️⭐️⭐️⭐️

✨目录
- 一、ATSS介绍
- 二、核心代码修改
- 2.1 修改loss文件
- 2.2 创建模块文件
- 2.3 修改训练代码
- 2.4 问题总结
一、ATSS介绍
🌳论文地址:点击
🌳源码地址:点击
🌳问题阐述:多年来,目标检测一直由基于锚点的检测器主导。最近,由于 FPN 和 Focal Loss 的提出,无锚检测器变得流行起来。在本文中,我们首先指出基于anchor的检测和无anchor的检测的本质区别实际上是如何定义正负训练样本,这导致了它们之间的性能差距。如果他们在训练时采用相同的正负样本定义,那么无论从一个盒子还是一个点回归,最终的性能都没有明显的差异。如何在不依赖复杂手工设计规则的情况下,利用有限的标注数据有效地进行目标分割训练。
🌳主要思想:ATSS方法首先在每个特征层找到与GT(Ground Truth) box最近的k个候选anchor boxes(非预测结果),然后计算这些候选box与GT间的IoU(Intersection over Union),并计算IoU的均值和标准差,以此确定IoU阈值,选择IoU大于该阈值的box作为最终的正样本。如果某个anchor box对应多个GT,则选择IoU最大的GT进行匹配3。
🌳思想优点:它能够根据目标的统计信息自动选择正负样本,避免了人工设定固定阈值的问题,提高了模型的性能和效率。同时,ATSS方法只需要一个超参数k,后续的使用表明ATSS的性能对k不敏感,因此可以说ATSS是一个几乎不需要超参数的方法。
🌳算法流程图:

二、核心代码修改
2.1 修改loss文件
loss文件地址:ultralytics\utils\loss.py
修改1:
_, target_bboxes, target_scores, fg_mask, _ = self.assigner(pred_scores.detach().sigmoid(),(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),anchor_points * stride_tensor,gt_labels,gt_bboxes,mask_gt,)
修改为
_, target_bboxes, target_scores, fg_mask = self.assigner_atss(anchors,n_anchors_list,gt_labels, gt_bboxes,mask_gt,(pred_bboxes.detach() * stride_tensor_s).type(gt_bboxes.dtype),)
修改2:
初始化ATSS标签分配策略:
self.assigner_atss = ATSSAssigner(9, num_classes=self.nc)
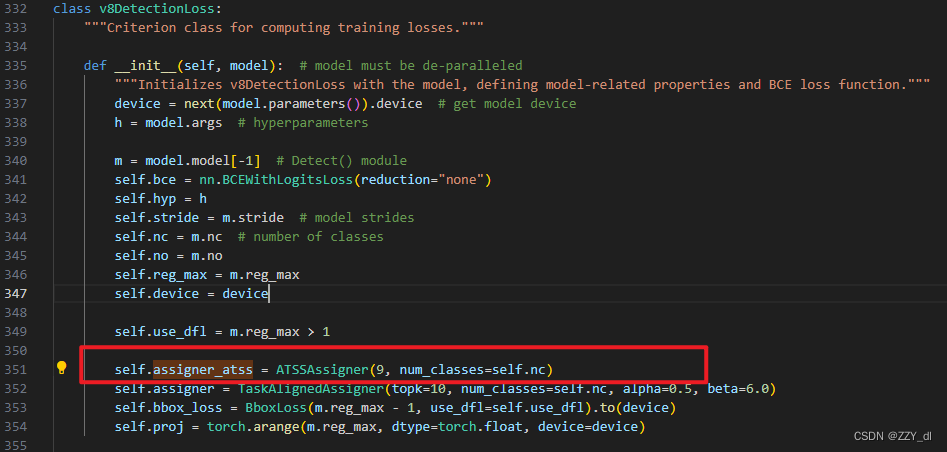
2.2 创建模块文件
上面修改完之后,我们可以发现找不到ATSSAssigner类,这是因为我们还未创建此类,我们在相同的utils文件夹下,创建ATSS标签分配策略代码,命名为atss_assigner.py,内容如下:
import torch
import torch.nn as nn
import torch.nn.functional as Fimport torch
import torch.nn.functional as F
from ultralytics.utils.atss_fun import iou_calculator, select_highest_overlaps, dist_calculator, select_candidates_in_gts
from ultralytics.utils.ops import fp16_clampdef cast_tensor_type(x, scale=1., dtype=None):if dtype == 'fp16':# scale is for preventing overflowsx = (x / scale).half()return xdef iou2d_calculator(bboxes1, bboxes2, mode='iou', is_aligned=False, scale=1., dtype=None):"""2D Overlaps (e.g. IoUs, GIoUs) Calculator.""""""Calculate IoU between 2D bboxes.Args:bboxes1 (Tensor): bboxes have shape (m, 4) in <x1, y1, x2, y2>format, or shape (m, 5) in <x1, y1, x2, y2, score> format.bboxes2 (Tensor): bboxes have shape (m, 4) in <x1, y1, x2, y2>format, shape (m, 5) in <x1, y1, x2, y2, score> format, or beempty. If ``is_aligned `` is ``True``, then m and n must beequal.mode (str): "iou" (intersection over union), "iof" (intersectionover foreground), or "giou" (generalized intersection overunion).is_aligned (bool, optional): If True, then m and n must be equal.Default False.@from MangoAI &3836712GKcH2717GhcK. please see https://github.com/iscyy/ultralyticsPro Returns:Tensor: shape (m, n) if ``is_aligned `` is False else shape (m,)"""assert bboxes1.size(-1) in [0, 4, 5]assert bboxes2.size(-1) in [0, 4, 5]if bboxes2.size(-1) == 5:bboxes2 = bboxes2[..., :4]if bboxes1.size(-1) == 5:bboxes1 = bboxes1[..., :4]if dtype == 'fp16':# change tensor type to save cpu and cuda memory and keep speedbboxes1 = cast_tensor_type(bboxes1, scale, dtype)bboxes2 = cast_tensor_type(bboxes2, scale, dtype)overlaps = bbox_overlaps(bboxes1, bboxes2, mode, is_aligned)if not overlaps.is_cuda and overlaps.dtype == torch.float16:# resume cpu float32overlaps = overlaps.float()return overlapsreturn bbox_overlaps(bboxes1, bboxes2, mode, is_aligned)def bbox_overlaps(bboxes1, bboxes2, mode='iou', is_aligned=False, eps=1e-6):assert mode in ['iou', 'iof', 'giou'], f'Unsupported mode {mode}'# Either the boxes are empty or the length of boxes' last dimension is 4assert (bboxes1.size(-1) == 4 or bboxes1.size(0) == 0)assert (bboxes2.size(-1) == 4 or bboxes2.size(0) == 0)# Batch dim must be the same# Batch dim: (B1, B2, ... Bn)assert bboxes1.shape[:-2] == bboxes2.shape[:-2]batch_shape = bboxes1.shape[:-2]rows = bboxes1.size(-2)cols = bboxes2.size(-2)if is_aligned:assert rows == colsif rows * cols == 0:if is_aligned:return bboxes1.new(batch_shape + (rows, ))else:return bboxes1.new(batch_shape + (rows, cols))area1 = (bboxes1[..., 2] - bboxes1[..., 0]) * (bboxes1[..., 3] - bboxes1[..., 1])area2 = (bboxes2[..., 2] - bboxes2[..., 0]) * (bboxes2[..., 3] - bboxes2[..., 1])if is_aligned:lt = torch.max(bboxes1[..., :2], bboxes2[..., :2]) # [B, rows, 2]rb = torch.min(bboxes1[..., 2:], bboxes2[..., 2:]) # [B, rows, 2]wh = fp16_clamp(rb - lt, min=0)overlap = wh[..., 0] * wh[..., 1]if mode in ['iou', 'giou']:union = area1 + area2 - overlapelse:union = area1if mode == 'giou':enclosed_lt = torch.min(bboxes1[..., :2], bboxes2[..., :2])enclosed_rb = torch.max(bboxes1[..., 2:], bboxes2[..., 2:])else:lt = torch.max(bboxes1[..., :, None, :2],bboxes2[..., None, :, :2]) # [B, rows, cols, 2]rb = torch.min(bboxes1[..., :, None, 2:],bboxes2[..., None, :, 2:]) # [B, rows, cols, 2]wh = fp16_clamp(rb - lt, min=0)overlap = wh[..., 0] * wh[..., 1]if mode in ['iou', 'giou']:union = area1[..., None] + area2[..., None, :] - overlapelse:union = area1[..., None]if mode == 'giou':enclosed_lt = torch.min(bboxes1[..., :, None, :2],bboxes2[..., None, :, :2])enclosed_rb = torch.max(bboxes1[..., :, None, 2:],bboxes2[..., None, :, 2:])eps = union.new_tensor([eps])union = torch.max(union, eps)ious = overlap / unionif mode in ['iou', 'iof']:return ious# calculate giousenclose_wh = fp16_clamp(enclosed_rb - enclosed_lt, min=0)enclose_area = enclose_wh[..., 0] * enclose_wh[..., 1]enclose_area = torch.max(enclose_area, eps)gious = ious - (enclose_area - union) / enclose_areareturn giousclass ATSSAssigner(nn.Module):'''Adaptive Training Sample Selection Assigner'''def __init__(self,topk=9,num_classes=80):super(ATSSAssigner, self).__init__()self.topk = topkself.num_classes = num_classesself.bg_idx = num_classes@torch.no_grad()def forward(self,anc_bboxes,n_level_bboxes,gt_labels,gt_bboxes,mask_gt,pd_bboxes):r"""This code is based onhttps://github.com/fcjian/TOOD/blob/master/mmdet/core/bbox/assigners/atss_assigner.pyArgs:anc_bboxes (Tensor): shape(num_total_anchors, 4)n_level_bboxes (List):len(3)gt_labels (Tensor): shape(bs, n_max_boxes, 1)gt_bboxes (Tensor): shape(bs, n_max_boxes, 4)mask_gt (Tensor): shape(bs, n_max_boxes, 1)pd_bboxes (Tensor): shape(bs, n_max_boxes, 4)Returns:target_labels (Tensor): shape(bs, num_total_anchors)target_bboxes (Tensor): shape(bs, num_total_anchors, 4)target_scores (Tensor): shape(bs, num_total_anchors, num_classes)fg_mask (Tensor): shape(bs, num_total_anchors)"""self.n_anchors = anc_bboxes.size(0)self.bs = gt_bboxes.size(0)self.n_max_boxes = gt_bboxes.size(1)if self.n_max_boxes == 0:device = gt_bboxes.devicereturn torch.full( [self.bs, self.n_anchors], self.bg_idx).to(device), \torch.zeros([self.bs, self.n_anchors, 4]).to(device), \torch.zeros([self.bs, self.n_anchors, self.num_classes]).to(device), \torch.zeros([self.bs, self.n_anchors]).to(device)overlaps = iou2d_calculator(gt_bboxes.reshape([-1, 4]), anc_bboxes)overlaps = overlaps.reshape([self.bs, -1, self.n_anchors])distances, ac_points = dist_calculator(gt_bboxes.reshape([-1, 4]), anc_bboxes)distances = distances.reshape([self.bs, -1, self.n_anchors])is_in_candidate, candidate_idxs = self.select_topk_candidates(distances, n_level_bboxes, mask_gt)overlaps_thr_per_gt, iou_candidates = self.thres_calculator(is_in_candidate, candidate_idxs, overlaps)# select candidates iou >= threshold as positiveis_pos = torch.where(iou_candidates > overlaps_thr_per_gt.repeat([1, 1, self.n_anchors]),is_in_candidate, torch.zeros_like(is_in_candidate))is_in_gts = select_candidates_in_gts(ac_points, gt_bboxes)mask_pos = is_pos * is_in_gts * mask_gttarget_gt_idx, fg_mask, mask_pos = select_highest_overlaps(mask_pos, overlaps, self.n_max_boxes)# assigned targettarget_labels, target_bboxes, target_scores = self.get_targets(gt_labels, gt_bboxes, target_gt_idx, fg_mask)# soft label with iouif pd_bboxes is not None:ious = iou_calculator(gt_bboxes, pd_bboxes) * mask_posious = ious.max(axis=-2)[0].unsqueeze(-1)target_scores *= iousreturn target_labels.long(), target_bboxes, target_scores, fg_mask.bool()def select_topk_candidates(self,distances, n_level_bboxes, mask_gt):mask_gt = mask_gt.repeat(1, 1, self.topk).bool()level_distances = torch.split(distances, n_level_bboxes, dim=-1)is_in_candidate_list = []candidate_idxs = []start_idx = 0for per_level_distances, per_level_boxes in zip(level_distances, n_level_bboxes):end_idx = start_idx + per_level_boxesselected_k = min(self.topk, per_level_boxes)_, per_level_topk_idxs = per_level_distances.topk(selected_k, dim=-1, largest=False)candidate_idxs.append(per_level_topk_idxs + start_idx)per_level_topk_idxs = torch.where(mask_gt, per_level_topk_idxs, torch.zeros_like(per_level_topk_idxs))is_in_candidate = F.one_hot(per_level_topk_idxs, per_level_boxes).sum(dim=-2)is_in_candidate = torch.where(is_in_candidate > 1, torch.zeros_like(is_in_candidate), is_in_candidate)is_in_candidate_list.append(is_in_candidate.to(distances.dtype))start_idx = end_idxis_in_candidate_list = torch.cat(is_in_candidate_list, dim=-1)candidate_idxs = torch.cat(candidate_idxs, dim=-1)return is_in_candidate_list, candidate_idxsdef thres_calculator(self,is_in_candidate, candidate_idxs, overlaps):n_bs_max_boxes = self.bs * self.n_max_boxes_candidate_overlaps = torch.where(is_in_candidate > 0, overlaps, torch.zeros_like(overlaps))candidate_idxs = candidate_idxs.reshape([n_bs_max_boxes, -1])assist_idxs = self.n_anchors * torch.arange(n_bs_max_boxes, device=candidate_idxs.device)assist_idxs = assist_idxs[:,None]faltten_idxs = candidate_idxs + assist_idxscandidate_overlaps = _candidate_overlaps.reshape(-1)[faltten_idxs]candidate_overlaps = candidate_overlaps.reshape([self.bs, self.n_max_boxes, -1])overlaps_mean_per_gt = candidate_overlaps.mean(axis=-1, keepdim=True)overlaps_std_per_gt = candidate_overlaps.std(axis=-1, keepdim=True)overlaps_thr_per_gt = overlaps_mean_per_gt + overlaps_std_per_gtreturn overlaps_thr_per_gt, _candidate_overlaps'''@from MangoAI &3836712GKcH2717GhcK. please see https://github.com/iscyy/ultralyticsPro'''def get_targets(self,gt_labels, gt_bboxes, target_gt_idx, fg_mask):# assigned target labelsbatch_idx = torch.arange(self.bs, dtype=gt_labels.dtype, device=gt_labels.device)batch_idx = batch_idx[...,None]target_gt_idx = (target_gt_idx + batch_idx * self.n_max_boxes).long()target_labels = gt_labels.flatten()[target_gt_idx.flatten()]target_labels = target_labels.reshape([self.bs, self.n_anchors])target_labels = torch.where(fg_mask > 0, target_labels, torch.full_like(target_labels, self.bg_idx))# assigned target boxestarget_bboxes = gt_bboxes.reshape([-1, 4])[target_gt_idx.flatten()]target_bboxes = target_bboxes.reshape([self.bs, self.n_anchors, 4])# assigned target scorestarget_scores = F.one_hot(target_labels.long(), self.num_classes + 1).float()target_scores = target_scores[:, :, :self.num_classes]return target_labels, target_bboxes, target_scores
2.3 修改训练代码
我们复制yolov8配置文件,命名为ultralytics\cfg\models\v8\YOLOv8-ATSS.yaml, 配置内容无需修改
import sys
import argparse
from ultralytics import YOLO
import os
sys.path.append(r'F:\python\company_code\Algorithm_architecture\ultralyticsPro0425-YOLOv8') # Pathdef main(opt):yaml = opt.cfgweights = opt.weightsmodel = YOLO(yaml).load(weights)model.info()results = model.train(data='ultralytics\cfg\datasets\coco128.yaml', epochs=10,imgsz=416, workers=0,batch=4,)def parse_opt(known=False):parser = argparse.ArgumentParser()parser.add_argument('--cfg', type=str, default= r'ultralytics\cfg\models\cfg2024\YOLOv8-标签分配策略\YOLOv8-ATSS.yaml', help='initial weights path')parser.add_argument('--weights', type=str, default='weights\yolov8n.pt', help='')opt = parser.parse_known_args()[0] if known else parser.parse_args()return optif __name__ == "__main__":opt = parse_opt()main(opt)
运行此代码即可将ATSS结合YOLOv8进行训练。python train_v8.py --cfg ultralytics\cfg\models\v8\YOLOv8-ATSS.yaml
2.4 问题总结
- 如果遇到v8在文件里修改了模型,但是训练时调用总是调用虚拟环境中的库。
- 是这种情况是没有成功载入你的模块,可以将所有的ultralytics复制到你的虚拟环境,或者卸载了ultralytics环境,只能载入你的文件。
- ModuleNotFoundError: No module named ‘timm’:
- pip install timm -i https://pypi.tuna.tsinghua.edu.cn/simple/(高环境问题可以安装pip install timm==0.6.13)
- ModuleNotFoundError: No module named ‘einops’
- pip install einops -i https://pypi.tuna.tsinghua.edu.cn/simple
- ModuleNotFoundError: No module named ‘hub_sdk’:
- pip install hub_sdk -i https://pypi.tuna.tsinghua.edu.cn/simple/

这篇关于YOLOv8优改系列二:YOLOv8融合ATSS标签分配策略,实现网络快速涨点的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




