本文主要是介绍JavaScript双向链表实现LRU缓存算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目标
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
什么是LRU
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
简介
最近最少使用算法(LRU)是大部分操作系统为最大化页面命中率而广泛采用的一种页面置换算法。该算法的思路是,发生缺页中断时,选择未使用时间最长的页面置换出去。 从程序运行的原理来看,最近最少使用算法是比较接近理想的一种页面置换算法,这种算法既充分利用了内存中页面调用的历史信息,又正确反映了程序的局部问题。利用 LRU 算法对上例进行页面置换的结果如图1所示。当进程第一次对页面 2 进行访问时,由于页面 7 是最近最久未被访问的,故将它置换出去。当进程第一次对页面 3进行访问时,第 1 页成为最近最久未使用的页,将它换出。由图1可以看出,前 5 个时间的图像与最佳置换算法时的相同,但这并非是必然的结果。因为,最佳置换算法是从“向后看”的观点出发的,即它是依据以后各页的使用情况;而 LRU 算法则是“向前看”的,即根据各页以前的使用情况来判断,而页面过去和未来的走向之间并无必然的联系。
硬件支持
LRU 置换算法虽然是一种比较好的算法,但要求系统有较多的支持硬件。为了了解一个进程在内存中的各个页面各有多少时间未被进程访问,以及如何快速地知道哪一页是最近最久未使用的页面,须有两类硬件之一的支持:寄存器或栈。
寄存器
为了记录某进程在内存中各页的使用情况,须为每个在内存中的页面配置一个移位寄存器,可表示为
R = Rn-1 Rn-2 Rn-3 … R2 R1 R0
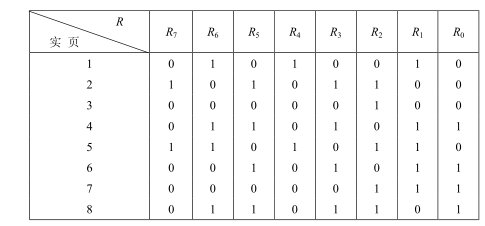 图 2 某进程具有 8 个页面时的 LRU 访问情况
图 2 某进程具有 8 个页面时的 LRU 访问情况
当进程访问某物理块时,要将相应寄存器的 R n -1 位置成 1。此时,定时信号将每隔一定时间(例如 100 ms)将寄存器右移一位。 如果我们把 n 位寄存器的数看做是一个整数, 那么,具有最小数值的寄存器所对应的页面,就是最近最久未使用的页面。图2示出了某进程在内存中具有 8 个页面,为每个内存页面配置一个 8 位寄存器时的 LRU 访问情况。这里,把 8 个内存页面的序号分别定为 1~8。由图可以看出,第 3 个内存页面的 R 值最小,当发生缺页时,首先将它置换出去。
栈
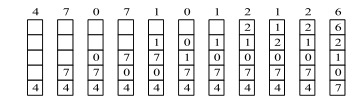 图 3 用栈保存当前使用页面时栈的变化情况
图 3 用栈保存当前使用页面时栈的变化情况
可利用一个特殊的栈来保存当前使用的各个页面的页面号。每当进程访问某页面时,便将该页面的页面号从栈中移出,将它压入栈顶。因此,栈顶始终是最新被访问页面的编号,而栈底则是最近最久未使用页面的页面号。假定现有一进程所访问的页面的页面号序列为:
4,7,0,7,1,0,1,2,1,2,6
随着进程的访问, 栈中页面号的变化情况如图 3 所示。 在访问页面 6 时发生了缺页,此时页面 4 是最近最久未被访问的页,应将它置换出去。
代码实现
思路
-
Map
使用一个Map来保存当前所有节点的信息,键为key,值为链表中的具体节点。 -
链表
使用一个双向链表来记录当前节点的顺序。
链表节点数据结构
保存插入节点信息,pre指向上一个节点,next指向下一个节点。
const linkLineNode = function (key = "", val = "") {this.val = val;this.key = key;this.pre = null;this.next = null;
};
链表数据结构
保存头结点head和尾结点tail。
const linkLine = function () {let head = new linkLineNode("head", "head");let tail = new linkLineNode("tail", "tail");head.next = tail;tail.pre = head;this.head = head;this.tail = tail;
};
链表头添加
将节点插入到头结点后面,修改头结点的next指向以及原本头结点的next节点的pre指向。
linkLine.prototype.append = function (node) {node.next = this.head.next;node.pre = this.head;this.head.next.pre = node;this.head.next = node;
};
链表删除指点节点
重新指向节点前后节点的next和pre指向。
linkLine.prototype.delete = function (node) {node.pre.next = node.next;node.next.pre = node.pre;
};
删除并返回链表的最后一个节点(非tail)
取到链表的最后一个节点(非tail节点),删除该节点并返回节点信息。
linkLine.prototype.pop = function () {let node = this.tail.pre;node.pre.next = this.tail;this.tail.pre = node.pre;return node;
};
打印链表信息
将链表的信息按顺序打印出来,入参为需要打印的属性。
linkLine.prototype.myConsole = function (key = 'val') {let h = this.head;let res = "";while (h) {if (res != "") res += "-->";res += h[key];h = h.next;}console.log(res);
};
LRUCache数据结构
capacity保存最大容量,kvMap保存节点信息,linkLine为节点的顺序链表。
/*** @param {number} capacity*/
var LRUCache = function (capacity) {this.capacity = capacity;this.kvMap = new Map();this.linkLine = new linkLine();
};
get
如果关键字 key 存在于缓存中,则返回关键字的值,并重置节点链表顺序,将该节点移到头结点之后,否则返回 -1 。
/*** @param {number} key* @return {number}*/
LRUCache.prototype.get = function (key) {if (this.kvMap.has(key)) {let node = this.kvMap.get(key);this.linkLine.delete(node);this.linkLine.append(node);return node.val;}return -1;
};
put
如果关键字 key 已经存在,则变更其数据值 value ,并重置节点链表顺序,将该节点移到头结点之后;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity , 则应该 逐出 最久未使用的关键字。
/*** @param {number} key* @param {number} value* @return {void}*/
LRUCache.prototype.put = function (key, value) {if (this.kvMap.has(key)) {let node = this.kvMap.get(key);node.val = value;this.linkLine.delete(node);this.linkLine.append(node);} else {let node = new linkLineNode(key, value);if (this.capacity == this.kvMap.size) {let nodeP = this.linkLine.pop();this.kvMap.delete(nodeP.key);}this.kvMap.set(key, node);this.linkLine.append(node);}
};
完整代码
const linkLineNode = function (key = "", val = "") {this.val = val;this.key = key;this.pre = null;this.next = null;
};const linkLine = function () {let head = new linkLineNode("head", "head");let tail = new linkLineNode("tail", "tail");head.next = tail;tail.pre = head;this.head = head;this.tail = tail;
};linkLine.prototype.append = function (node) {node.next = this.head.next;node.pre = this.head;this.head.next.pre = node;this.head.next = node;
};
linkLine.prototype.delete = function (node) {node.pre.next = node.next;node.next.pre = node.pre;
};
linkLine.prototype.pop = function () {let node = this.tail.pre;node.pre.next = this.tail;this.tail.pre = node.pre;return node;
};
linkLine.prototype.myConsole = function (key = 'val') {let h = this.head;let res = "";while (h) {if (res != "") res += "-->";res += h[key];h = h.next;}console.log(res);
};/*** @param {number} capacity*/
var LRUCache = function (capacity) {this.capacity = capacity;this.kvMap = new Map();this.linkLine = new linkLine();
};/*** @param {number} key* @return {number}*/
LRUCache.prototype.get = function (key) {if (this.kvMap.has(key)) {let node = this.kvMap.get(key);this.linkLine.delete(node);this.linkLine.append(node);return node.val;}return -1;
};/*** @param {number} key* @param {number} value* @return {void}*/
LRUCache.prototype.put = function (key, value) {if (this.kvMap.has(key)) {let node = this.kvMap.get(key);node.val = value;this.linkLine.delete(node);this.linkLine.append(node);} else {let node = new linkLineNode(key, value);if (this.capacity == this.kvMap.size) {let nodeP = this.linkLine.pop();this.kvMap.delete(nodeP.key);}this.kvMap.set(key, node);this.linkLine.append(node);}
};
测试
var obj = new LRUCache(2);
obj.put(1, 1);
obj.put(2, 2);
console.log(obj.get(1)); //---> 1
obj.put(3, 3);
console.log(obj.get(2));//---> -1
obj.put(4, 4);
console.log(obj.get(1));//---> -1
console.log(obj.get(3));//---> 3
console.log(obj.get(4));//---> 4
这篇关于JavaScript双向链表实现LRU缓存算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





