本文主要是介绍Java高阶私房菜:JVM垃圾回收机制及算法原理探究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
垃圾回收机制
什么是垃圾回收机制
JVM的自动垃圾回收机制
垃圾回收机制的关键知识点
初步了解判断方法-引用计数法
GCRoot和可达性分析算法
什么是可达性分析算法
什么是GC Root
对象回收的关键知识点
标记对象可回收就一定会被回收吗?
可达性分析算法为什么可以解决循环引用造成的内存泄漏问题?
编辑
垃圾回收算法
标记-清除算法原理
标记-复制算法原理
标记-整理-压缩算法原理
几种算法对比
本文主要讲解了什么是垃圾回收机制,进而了解它的底层架构原理,到核心的几种垃圾回收算法,逐步延申到它的应用场景和启发。
垃圾回收机制
什么是垃圾回收机制
垃圾回收机制(Garbage Collection, 简称GC) 指自动管理动态分配的内存空间的机制,自动回收不再使用的内存,以避免内存泄漏和内存溢出的问题。
最早是在1960年代提出的,程序员需要手动管理内存的分配和释放,这往往会导致内存泄漏和内存溢出等问题,同时也增加了程序员的工作量,特别是C++/C语言开发的时候,Java语言是最早实现垃圾回收机制的语言之一,其他编程语言,如C#、Python和Ruby等,也都提供了垃圾回收机制。
JVM的自动垃圾回收机制
指Java虚拟机在运行Java程序时,自动回收不再使用的对象所占用的内存空间的过程。Java程序中的对象,一旦不再被引用会被标记为垃圾对象,JVM会在适当的时候自动回收这些垃圾对象所占用的内存空间。
其优点在于
-
减少了开发人员的工作量,不需要手动管理内存;
-
动态地管理内存,根据应用程序的需要进行分配和回收,提高了内存利用率;
-
避免内存泄漏和野指针等问题,增加程序的稳定性和可靠;
缺点在于
-
垃圾回收会占用一定的系统资源,可能会影响程序的性能;
-
垃圾回收过程中会停止程序的执行,可能会导致程序出现卡顿等问题;
-
不一定能够完全解决内存泄漏等问题,需要在编写代码时注意内存管理和编码规范;
垃圾回收机制的关键知识点
垃圾回收机制需要判断哪些对象需要回收?即如何判读判断对象存活。其方法包括了有引用计数法和可达性分析算法(JVM采用)。
如何针对性进行回收?其收集死亡对象方法主要有三种,有标记-清除算法、标记-复制算法和标记-整理算法。每个中算法所针对的场景都不一样,没有最优解,只有最合适。
了解垃圾回收算法和垃圾收集器的关系?两者没有可比性,是承先启后的关系,垃圾回收算法是垃圾回收的方法论,而垃圾收集器是算法的落地实现。
初步了解判断方法-引用计数法
简而言之就是跟踪每个对象被引用的次数,当引用次数为0时,就可以将该对象回收。在JVM中,每个对象都有一个引用计数器,当对象被引用时,引用计数器+1,当对象被取消引用时,引用计数器-1,当引用计数器为0时,该对象就可以被回收。
其优点在于实现简单,回收垃圾的效率高。但缺点也显而易见循环引用无法回收。如果两个对象互相引用,它们的引用计数器永远不会为0,因此无法真正被回收,而且引用计数器开销大,每个对象都需要一个引用计数器,如果对象很多,开销就会很大。
什么是循环引用
public class Main {public static void main(String[] args) {A a = new A();B b = new B();a.setB(b);b.setA(a);a = null;b = null;System.gc();}
}class A {private B b;public void setB(B b) {this.b = b;}
}class B {private A a;public void setA(A a) {this.a = a;}
}类A和类B相互引用,每个对象都持有对方的引用,形成了一个循环引用的环,当Main方法执行完毕后,a和b对象都置为null。由于它们相互引用,它们的引用计数器都不为0,无法被垃圾回收器回收,导致内存泄漏,但是上面代码却不会发生内存泄漏,因为多数jvm没有采用这个引用计数器方案,而是采用可达性分析算法。
GCRoot和可达性分析算法
什么是可达性分析算法
简而言之就是从一些“GC Roots”对象开始,通过搜索引用链的方式,找到所有可达对象。如果一个对象没有任何引用链与GC Roots相连,那么它就被判定为不可用的,是可以被回收的垃圾对象。
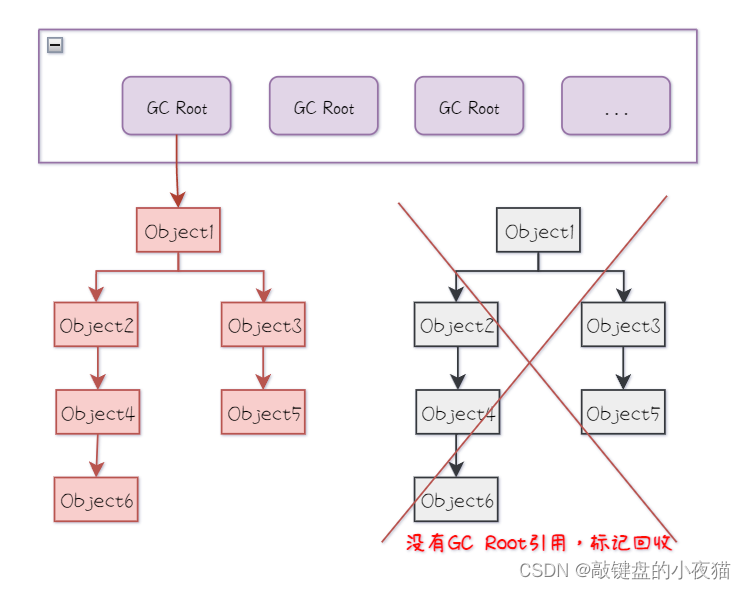
什么是GC Root
指一些被JVM认为是存活的对象,它们是垃圾回收算法的起点,可以理解为由堆外指向堆内的引用, 本身是没有存储位置,都是字节码加载运行过程中加入 JVM 中的一些普通引用。通俗的例子可以是一个树形结构,树的根节点就是GC Roots,是垃圾回收器的起点,如果一个节点没有任何子节点与根节点相连,那这个节点就被认为是不可达的,可以被回收器回收。
举个例子,将GC Roots比喻成一座城市,城市中有很多建筑物,这些建筑物就是内存中的对象,GC Roots就像城市的卫生局、消防局等,它们直接或间接地与城市中的建筑物相连,从这些机构出发,通过道路、桥梁等连接,最终能够到达所有的建筑物,如果一个建筑物没有与这些机构相连,那么它就被认为是废弃的,可以被清理掉。
JVM中的GC Roots对象包括以下几种:
1)虚拟机栈(栈帧中的本地变量表)中引用的对象。
2)方法区中类静态属性引用的对象。JDK 1.7 开始静态变量的存储从方法区移动到堆中,比如你定义了一个static 的集合对象,那里面添加的对象就是可以被GC Root可达的
3)方法区中常量引用的对象。字符串常量池从 JDK 1.7 开始由方法区移动到堆中,本地方法栈中JNI(即一般说的Native方法)引用的对象。
小技巧:由于GC Roots采用栈方式存放变量和指针,如果一个指针它保存了堆内存里面的对象,但是自己又不能存放在堆内存里面,那么它就是一个GC Roots。
代码举例
// product 是栈帧中的本地变量,指向了 title = CSDN 这个 Product 对象
// 此时 当product 充当了 GC Root 的作用
// 当product = null; ,那么product 与原来指向product 对象断开了连接
// 所以这个 new Product("CSDN") 对象会被回收public class GCTest {public static void main(String[] args) {Product product = new Product("CSDN");product = null;}
}对象回收的关键知识点
标记对象可回收就一定会被回收吗?
不一定会回收,对象的finalize方法给了对象一次最后一次存活的机会。当对象不可达(可回收)并发生 GC 时,会先判断对象是否执行了 finalize 方法,如果未执行则会先执行 finalize 方法。前对象与 GC Roots 关联,执行 finalize 方法之后,GC 会再次判断对象是否可达,如果不可达,则会被回收,如果可达,则不回收!需要注意的是 finalize 方法只会被执行一次,如果第一次执行 finalize 方法,对象变成了可达,则不会回收,但如果对象再次被 GC,则会忽略 finalize 方法,对象会被直接回收掉!
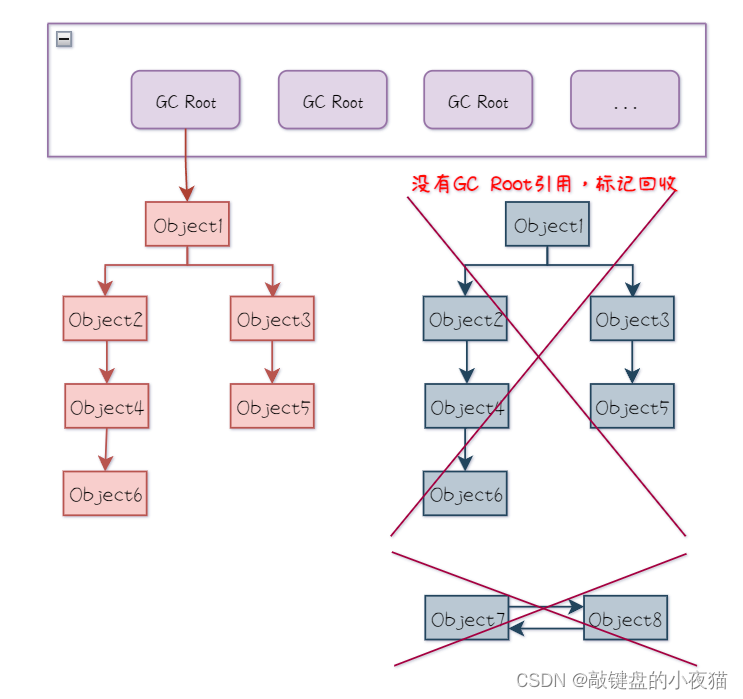
可达性分析算法为什么可以解决循环引用造成的内存泄漏问题?
当两个或多个对象相互引用时,它们的引用链会形成一个环,但是由于这个环中的对象与GC Roots没有任何引用链相连,所以JVM会将这些对象判定为不可用的,从而回收它们。如下图所示。
垃圾回收算法
标记-清除算法原理
是一种常见的垃圾回收算法,它的基本思路是分为两个阶段:标记阶段和清除阶段。
在标记阶段,垃圾回收器会从一些GC Roots对象开始,遍历整个对象图,标记所有被引用的对象。被标记的对象会被打上标记,表示这些对象是“活”的对象,需要保留下来,未被标记的对象就是垃圾对象,可以被回收。
在清除阶段,垃圾回收器会对所有未被标记的对象进行回收。
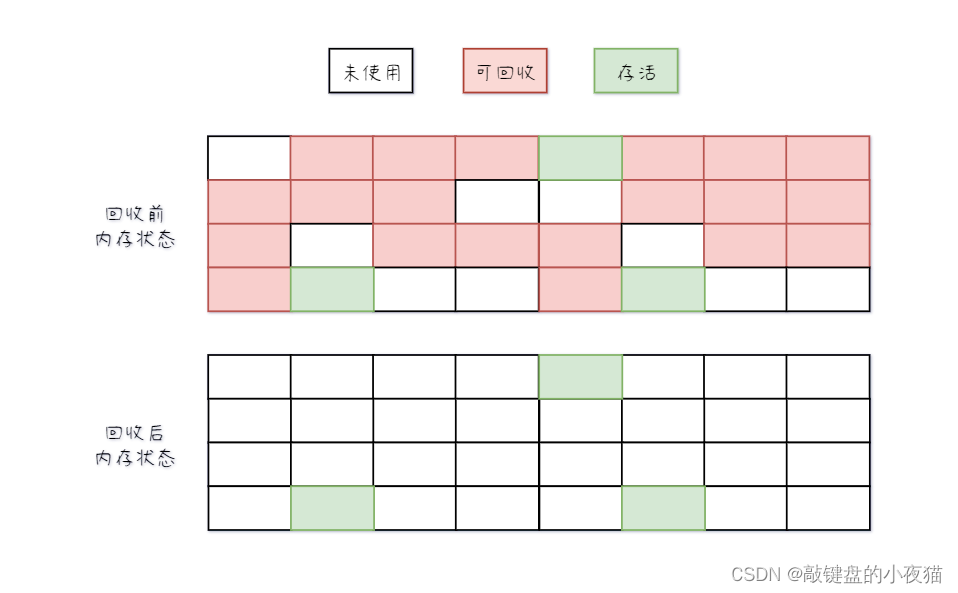
其优点在于可以回收不连续的内存空间。其缺点显而易见,标记和清除两个步骤,都需要垃圾回收器遍历整个对象图,耗费时间较长,并且会产生内存碎片,当频繁进行垃圾回收时,内存碎片会越来越多导致可用内存空间不足,一次次不连续的内存使用,会影响程序的性能和稳定性。
该算法应用场景应用在实际应用中,标记清除法一般用于不需要频繁进行垃圾回收的场景,比如在Java堆中大对象的分配和回收。其实后续的收集算法大多都是以标记-清除算法为基础,对其缺点进行改进。
标记-复制算法原理
是一种常见的垃圾回收算法,它的基本思路是将Java堆分为两个区域:一个活动区域和一个空闲区域。在垃圾回收过程中,首先标记所有被引用的对象,然后将所有被标记的对象复制到空闲区域中,最后交换两个区域的角色,完成垃圾回收。
从下图可以看出复制到空闲区域后的内存对象是连续的,以及未使用的内存空间也被重新分配。
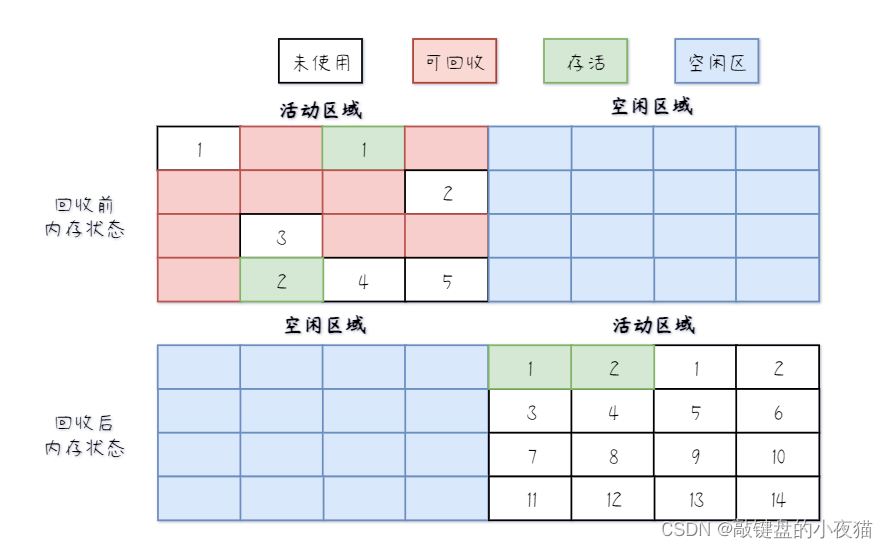
为更深入了解该算法,我们详细看看它的实现步骤:
1)在初始化环境下会将Java堆分为两个区域:一个活动区域和一个空闲区域。初始时,所有对象都分配在活动区域中;
2)从GC Roots对象开始,遍历整个对象图,标记所有被引用的对象;
3)对所有被标记存活的对象进行遍历,将它们复制到空闲区域中,并更新所有指向它们的引用,使它们指向新的地址;
4)对所有未被标记的对象进行回收,将它们所占用的内存空间释放;
5)交换活动区域和空闲区域的角色,空闲区域变为新的活动区域,原来的活动区域变为空闲区域;
6)当空闲区域的内存空间不足时,进行一次垃圾回收,重复以上步骤。
这样的方式其优点在于,如果内存中的垃圾对象较多,需要复制的对象就较少,则效率高,清理后,内存碎片少。其缺点也不少,虽然标记复制算法的效率较高,但是预留一半的内存区域用来存放存活的对象,占用额外的内存空间。如果出现存活对象数量比较多的时候,需要复制较多的对象效率低,假如是在老年代区域,99%的对象都是存活的,则性能低,所以老年代不适合这个算法。
该算法应用场景应用在新生代的垃圾回收,因此需要对新生代的对象进行分代管理,虚拟机多数采用这个算法,对新生代进行内存管理,因为多数这个新生代区域的存活对象数量少。国外有公司统计过多数业务,98%撑不过一次GC,所以不用1:1比例分配新生代的空间。

这么分配的原因在于,当发生GC时, 将Eden和Survivor中存活对象一次性复制到另外一块Survivor空间上, 然后清理掉Eden和已用过的那块Survivor空间,每次新生代中可用内存空间为整个新生代容量的90% (Eden的80% + Survivor的 10%) ,只有一个Survivor空间, 即10%的新生代是会被浪费而已。
标记-整理-压缩算法原理
从根节点开始对所有可达对象做一次标记,但之后并不简单地清理未标记的对象,而是将所有的存活对象压缩到内存的一端,然后清理边界外的垃圾,避免了碎片的产生,也不需要两块相同的内存空间,因此性价比比较高。
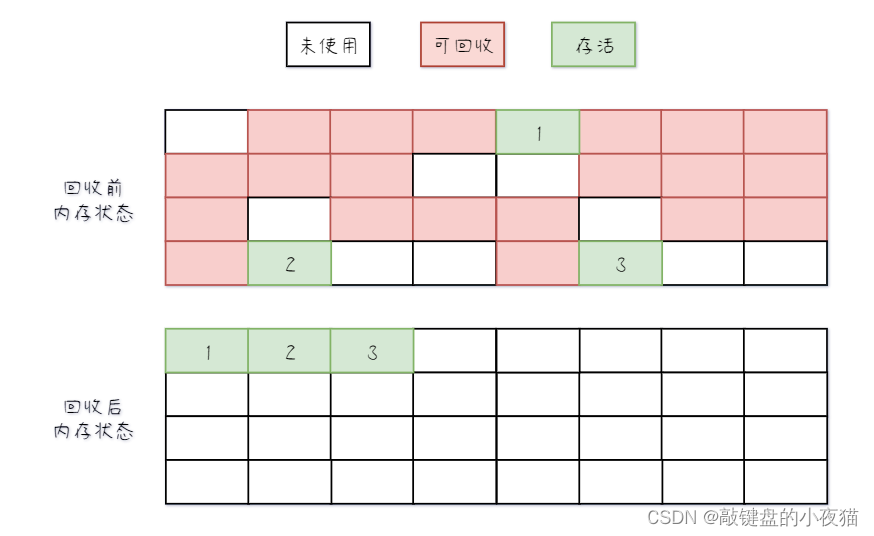
其优点在于,解决了标记清除算法的碎片化的问题。和对比标记-复制算法来看,该算法不用浪费额外的空间,因为前者算法需要预留一部分空闲区域用于复制。和对比标记-清除算法来看,前者是一种非移动式的回收算法,而该算法是移动式的回收,且解决了内存碎片化的问题。
其缺点就是效率相比于标记复制算法和标记清除算法低一些,在整理存活对象时,因对象位置的变动,需要调整该虚拟机栈中的引用地址。
该算法应用场景应用在老年代的内存回收,它在标记-清除算法的基础上做了部分优化。
几种算法对比
标记-复制算法适合在存活对象少、垃圾对象多的场景,即新生代空间,朝生夕灭的场景
标记-整理-压缩算法适合在存活对象多、垃圾对象少的场景,即老年代空间,都是历经多次GC,依旧存活的对象。
标记-清除算法作为基础算法,其实也适合于在老年代空间,但不同的是在处理后会有碎片化空间,使用标记-整理-压缩算法效果会更佳。
这篇关于Java高阶私房菜:JVM垃圾回收机制及算法原理探究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



