本文主要是介绍Python网络数据抓取(3):Beautiful Soup,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Beautiful Soup
这个库通常被称为Beautiful Soup 4(BS4)。它主要用来从HTML或XML文件中抓取数据。此外,它也用于查询和修改HTML或XML文档中的数据。
现在,让我们来了解如何使用Beautiful Soup 4。我们将采用上一节中使用的HTML数据作为示例。不过在此之前,我们需要先将这些数据导入到我们的文件中。
from bs4 import BeautifulSoup
从我们的目标页面中,我们将提取一些重要数据,例如名称、价格和产品评级。为了提取数据,我们需要一个解析树。
soup=BeautifulSoup(resp.text, ’html.parser’)
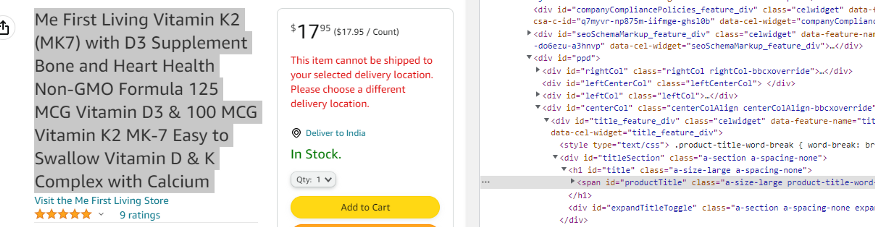
当您检查名称时,您会发现它存储在 a-size-large 类产品标题分词符中。
name = soup.find(“span”,{“class”:”a-size-large product-title-word-break”}).text
print(name)
当我们打印名字时,我们得到了这个。

正如你所看到的,我们得到了产品的名称。现在,我们将提取价格。
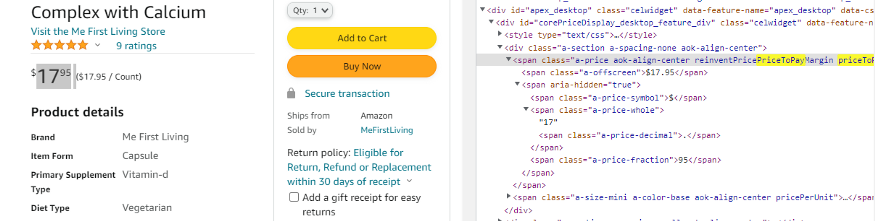
通过检查价格,我可以看到价格存储在屏幕外的类中,而该类存储在priceToPay 类中。
price = soup.find(“span”,{“class”:”priceToPay”}).find(“span”,{“class”:”a-offscreen”}).text
print(price)
当我们打印它时,我们得到了这个。

现在,最后一部分是提取产品的评级。

正如您所看到的,评级存储在***a-icon-star***中。
rating = soup.find(“i”,{“class”:”a-icon-star”}).text
所以,当我们打印这个时,我们得到了这个。
>>> 4.9 out of 5 stars
但如果你只需要 4.9 部分,并且想要删除所有多余的文本,那么我们将使用 python 的 split 函数。
rating = soup.find(“i”,{“class”:”a-icon-star”}).text.split(“ “)[0]
这将为我们提供评级部分。
>>> 4.9
我们利用requests库发送GET请求,成功地从第一部分获取的杂乱HTML中提取出了所有必需的数据。
那么,如果你需要将这些数据保存到CSV文件中,又该如何操作呢?这时,我们将调用Pandas库来执行这项工作(下期见)。
本文由 mdnice 多平台发布
这篇关于Python网络数据抓取(3):Beautiful Soup的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





