本文主要是介绍十、多模态大语言模型(MLLM),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 多模态大语言模型(Multimodal Large Language Models)
- 模态的定义
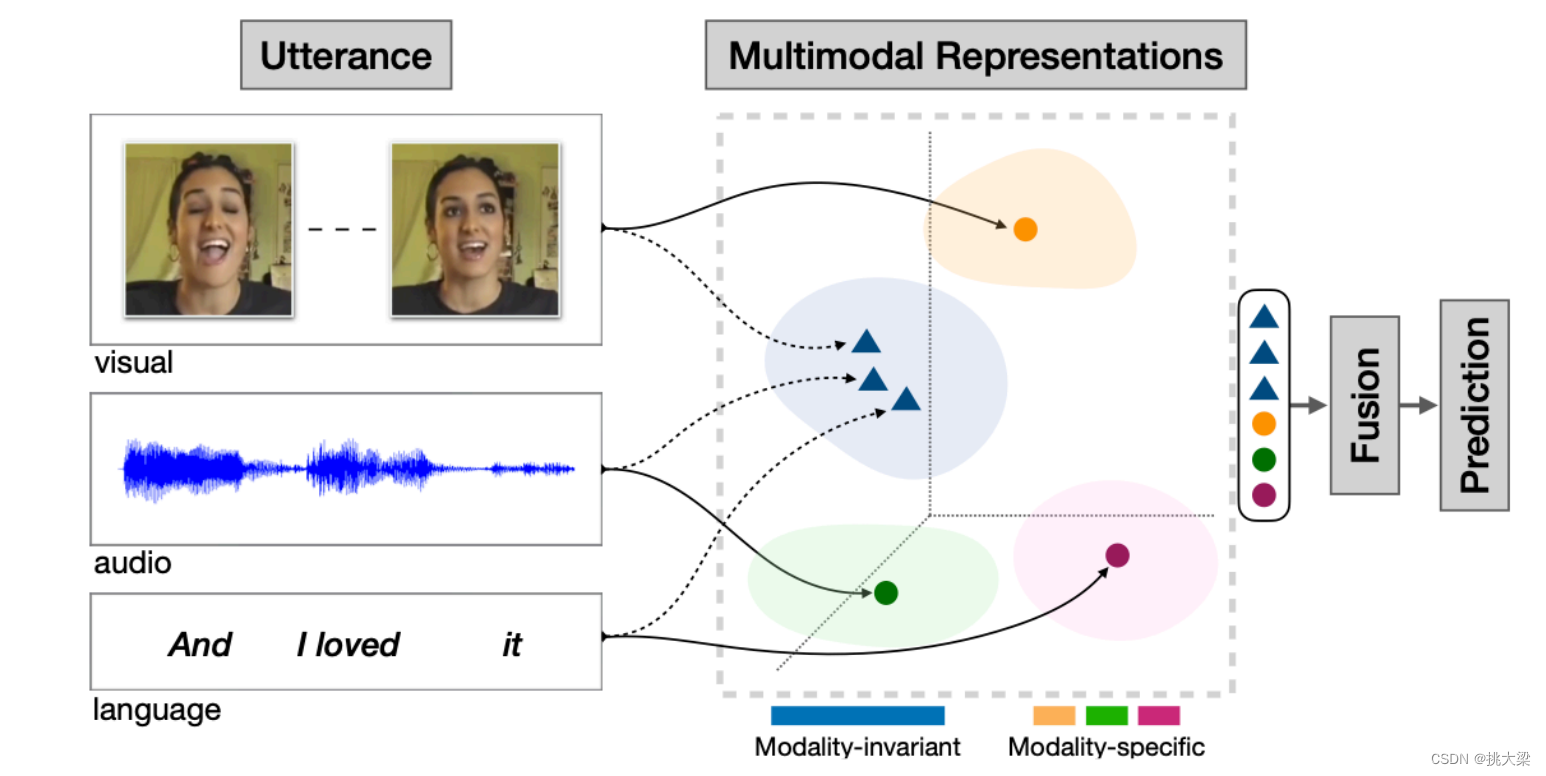
模态(modal)是事情经历和发生的方式,我们生活在一个由多种模态(Multimodal)信息构成的世界,包括视觉信息、听觉信息、文本信息、嗅觉信息等 - MLLMs的定义
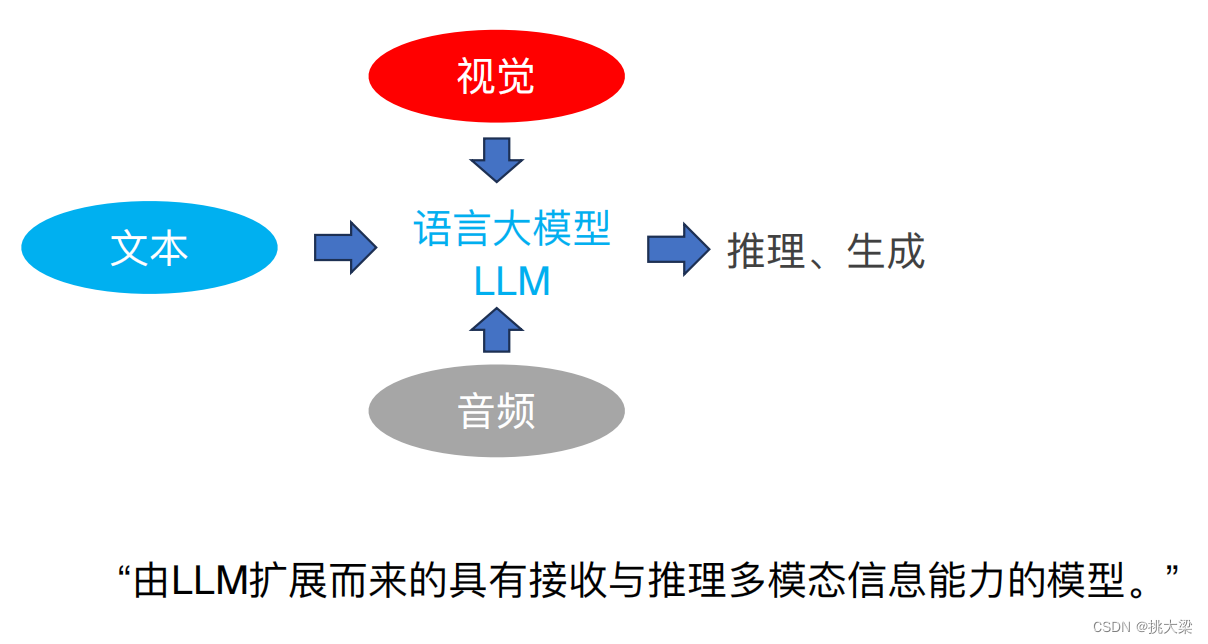
由LLM扩展而来具有接收和推理多模态信息能力的模型
2 模型概念区分
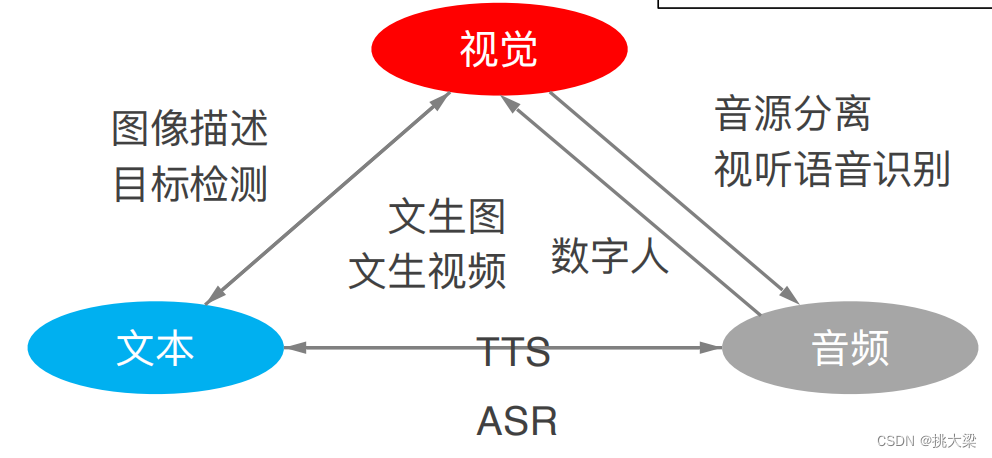
- 跨模态模型
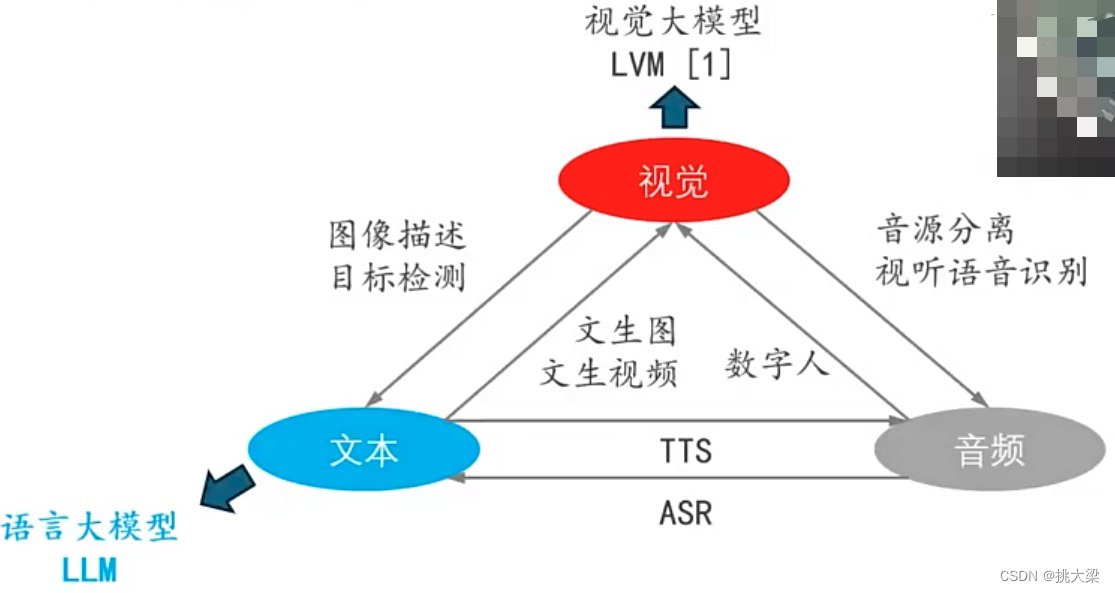
- 单模态大模型
- 多模态模型
- 多模态语言大模型
跨模态模型
单模态大模型
多模态大模型
多模态大语言模型
3 多模态的发展历程
四个关键里程碑
1 Vision Transformer(ViT)
图片格子的线性映射
ViT
Mask Image Modeling 无监督图像特征学习
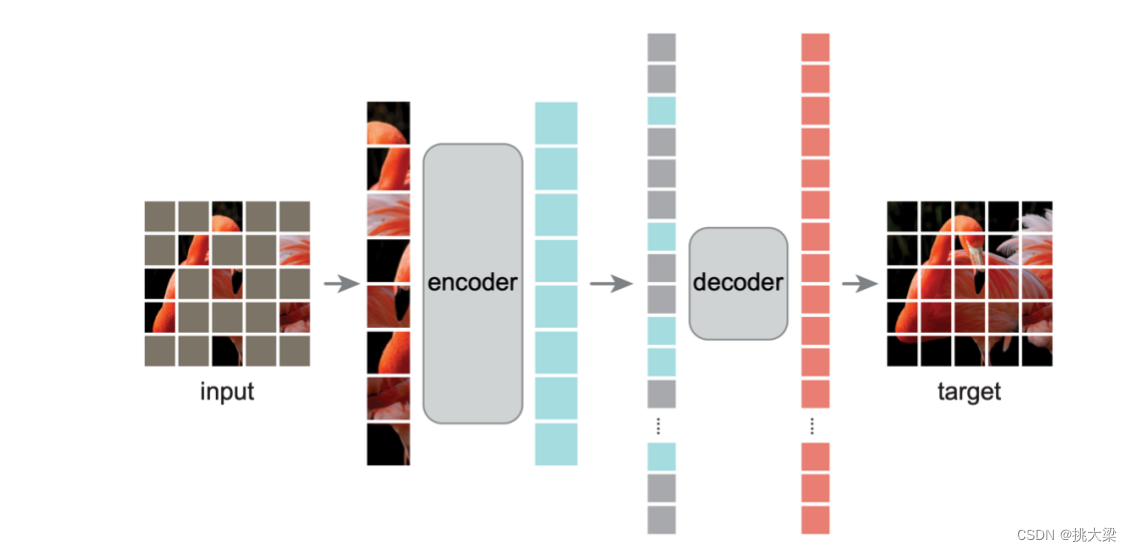
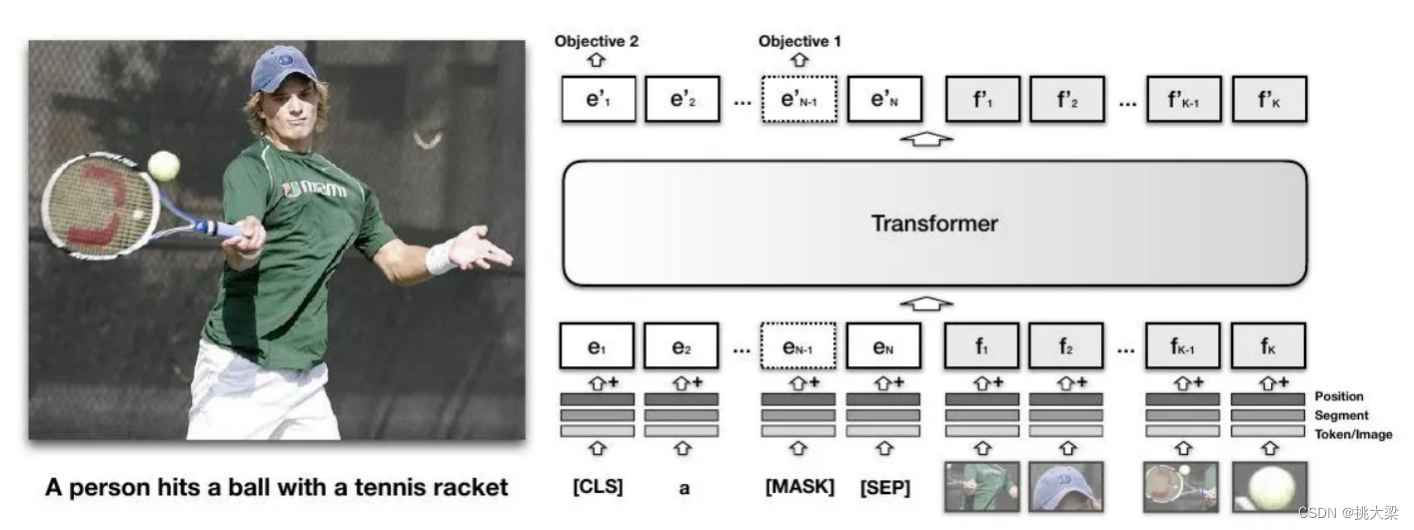
2 基于transformer架构的图像-文本联合建模
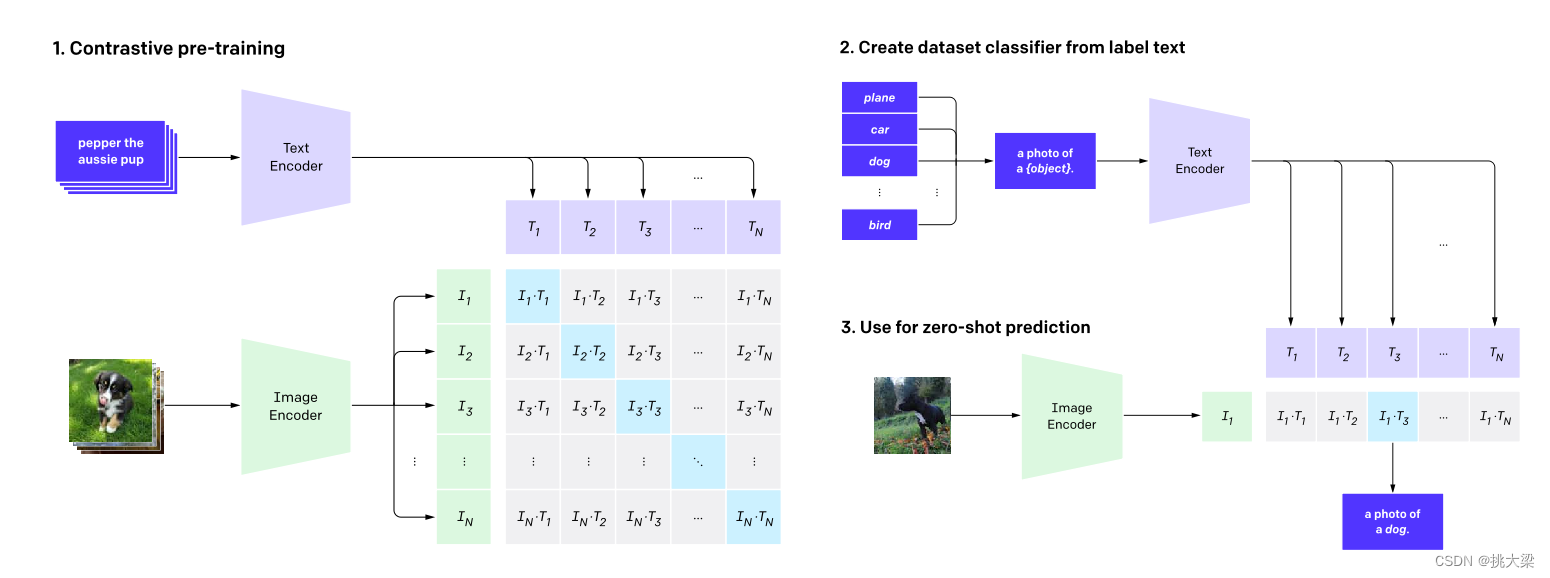
3 大规模 图-文 Token对齐模型CLIP
通过余弦距离将文和图转换至同一向量空间。将图像的分类闭集引入至开集
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
from IPython.display import Image, display
display(Image(filename="bus.jpg"))

from PIL import Image
image = Image.open("bus.jpg")
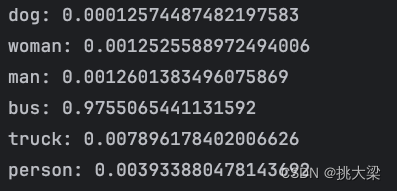
cls_list = ["dog", "woman", "man", "bus", "truck","person","a black truck", "a white truck", "cat"]
input = processor(text=cls_list, images=image,return_tensors="pt", padding=True)
outputs = model(**input)
print(outputs.keys())

logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)for i in range(len(cls_list)):print(f"{cls_list[i]}: {probs[0][i]}")
4 多模态大语言模型OpenAI GPTv4
支持图文交替输出,输入文本或图像,输出自然语言

特点如下:
- 遵循文字提示

- 理解视觉指向和参考
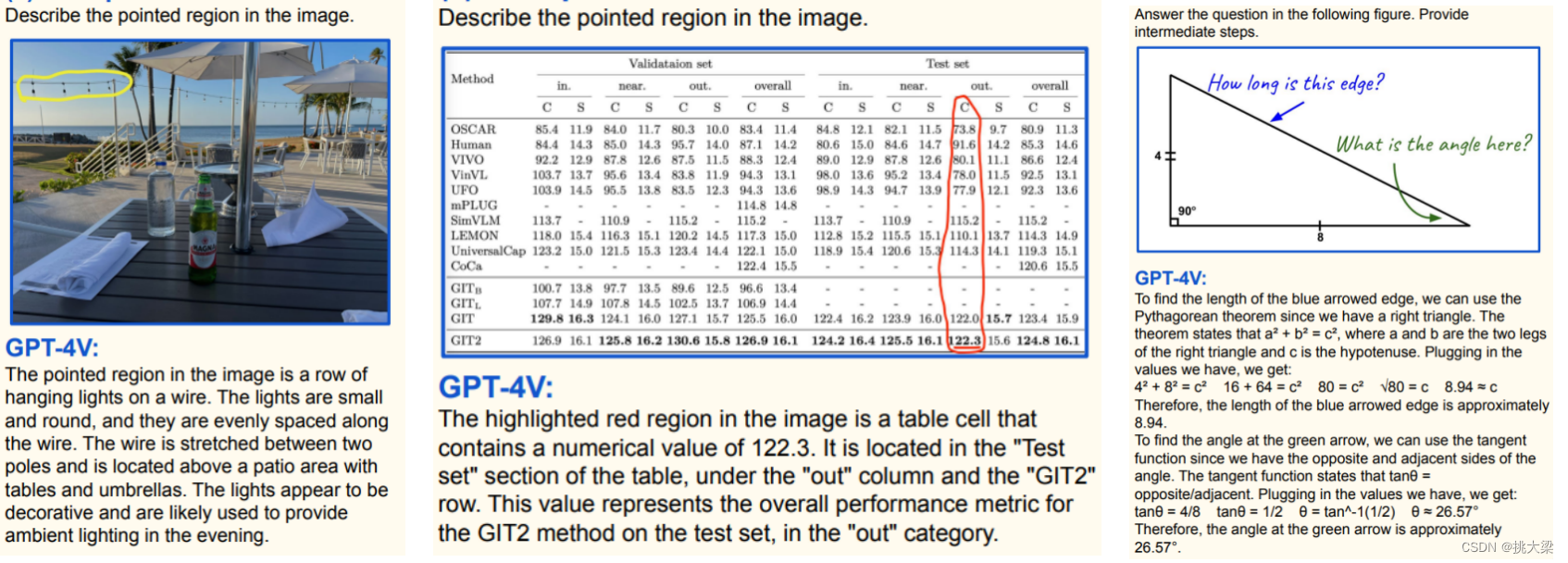
- 支持视觉和文本联合提示
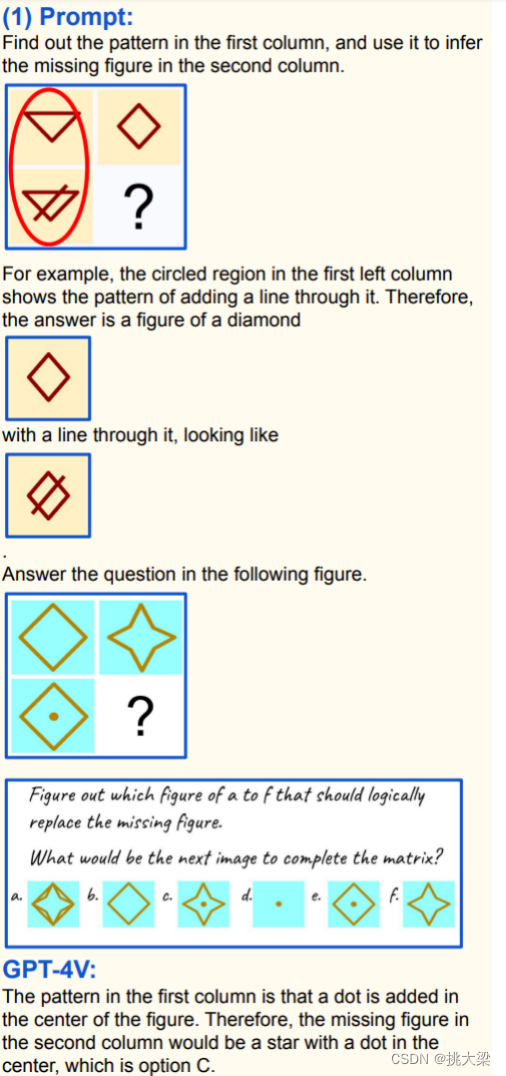
- 少样本上下文学习
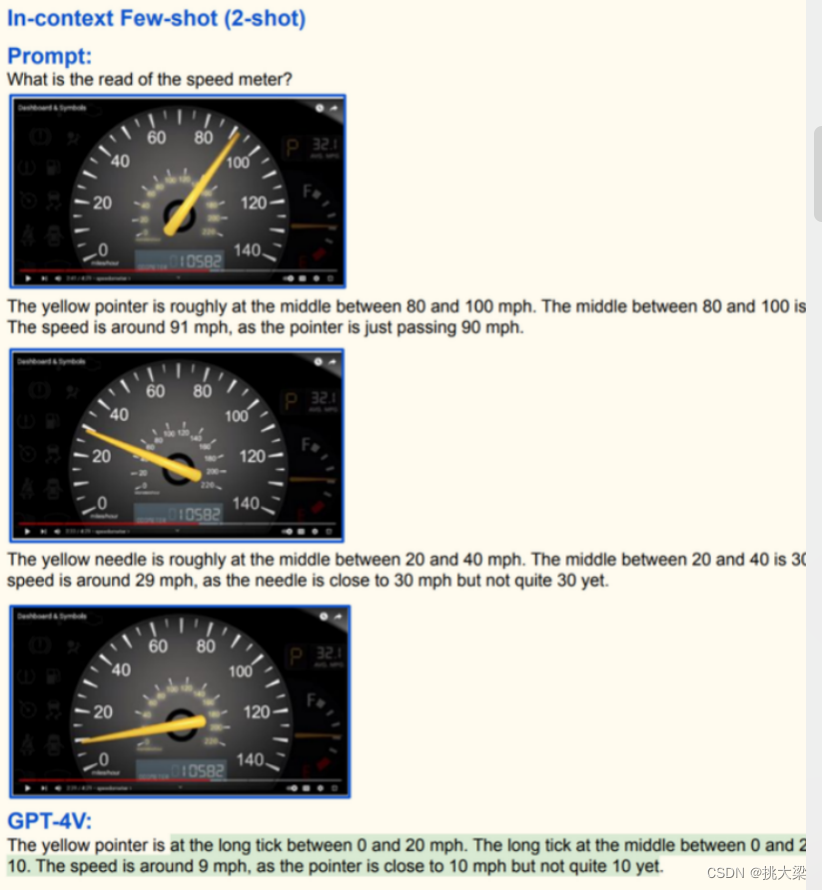
- 强大的视觉认知能力
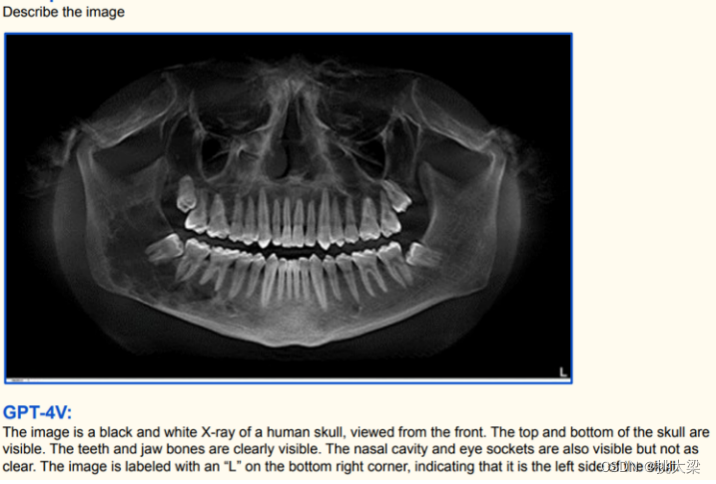



5 Google Gemini 原生多模态- 输入:文本、语音、图像和视频信息
- 输出:自然语言、图像
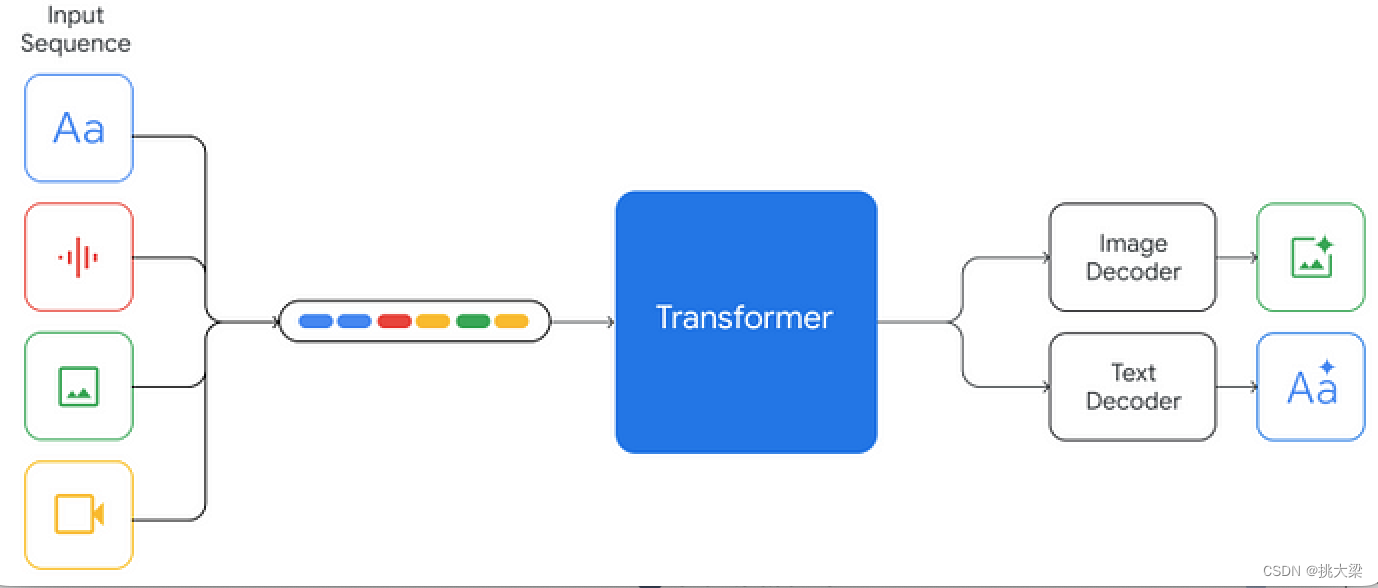
- 支持多模态内容输出
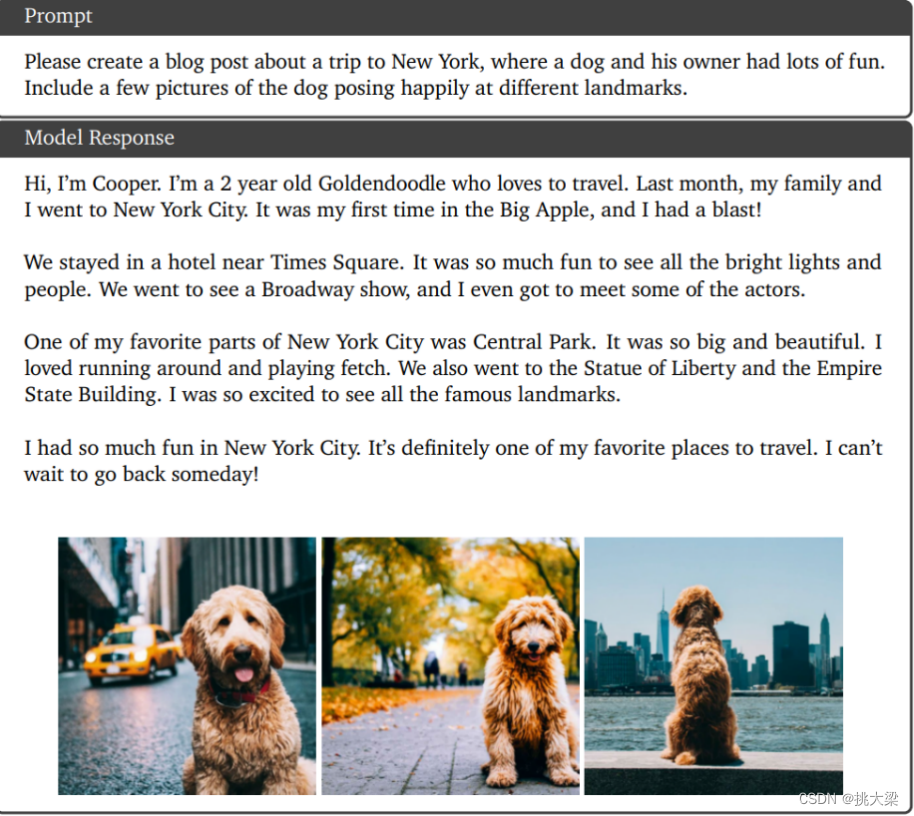
- 复杂图像理解与代码生成

!pip install google-generativeai -i https://pypi.tuna.tsinghua.edu.cn/simple
import gradio as gr
from openai import OpenAI
import base64
from PIL import Image
import io
import os
import google.generativeai as genai# Function to encode the image to base64def encode_image_to_base64(image):buffered = io.BytesIO()image.save(buffered, format="JPEG")return base64.b64encode(buffered.getvalue()).decode('utf-8')# Function to query GPT-4 Visiondef query_gpt4_vision(text, image1, image2, image3):client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))messages = [{"role": "user", "content": [{"type": "text", "text": text}]}]images = [image1, image2, image3]for image in images:if image is not None:base64_image = encode_image_to_base64(image)image_message = {"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}}messages[0]["content"].append(image_message)response = client.chat.completions.create(model="gpt-4-vision-preview",messages=messages,max_tokens=1024,)return response.choices[0].message.content# Function to query Gemini-Prodef query_gemini_vision(text, image1, image2, image3):# Or use `os.getenv('GOOGLE_API_KEY')` to fetch an environment variable.# GOOGLE_API_KEY=userdata.get('GOOGLE_API_KEY')GOOGLE_API_KEY = os.getenv('GOOGLE_API_KEY')genai.configure(api_key=GOOGLE_API_KEY)model = genai.GenerativeModel('gemini-pro-vision')images = [image1, image2, image3]query = [text]for image in images:if image is not None:query.append(image)response = model.generate_content(query, stream=False)response.resolve()return response.text# 由于Gradio 2.0及以上版本的界面构建方式有所不同,这里使用blocks API来创建更复杂的UIdef main():with gr.Blocks() as demo:gr.Markdown("### 输入文本")input_text = gr.Textbox(lines=2, label="输入文本")input_images = [gr.Image(type="pil", label="Upload Image", tool="editor") for i in range(3)]output_gpt4 = gr.Textbox(label="GPT-4 输出")output_other_api = gr.Textbox(label="Gemini-Pro 输出")btn_gpt4 = gr.Button("调用GPT-4")btn_other_api = gr.Button("调用Gemini-Pro")btn_gpt4.click(fn=query_gpt4_vision, inputs=[input_text] + input_images, outputs=output_gpt4)btn_other_api.click(fn=query_gemini_vision, inputs=[input_text] + input_images, outputs=output_other_api)demo.launch(share=True)if __name__ == "__main__":main()
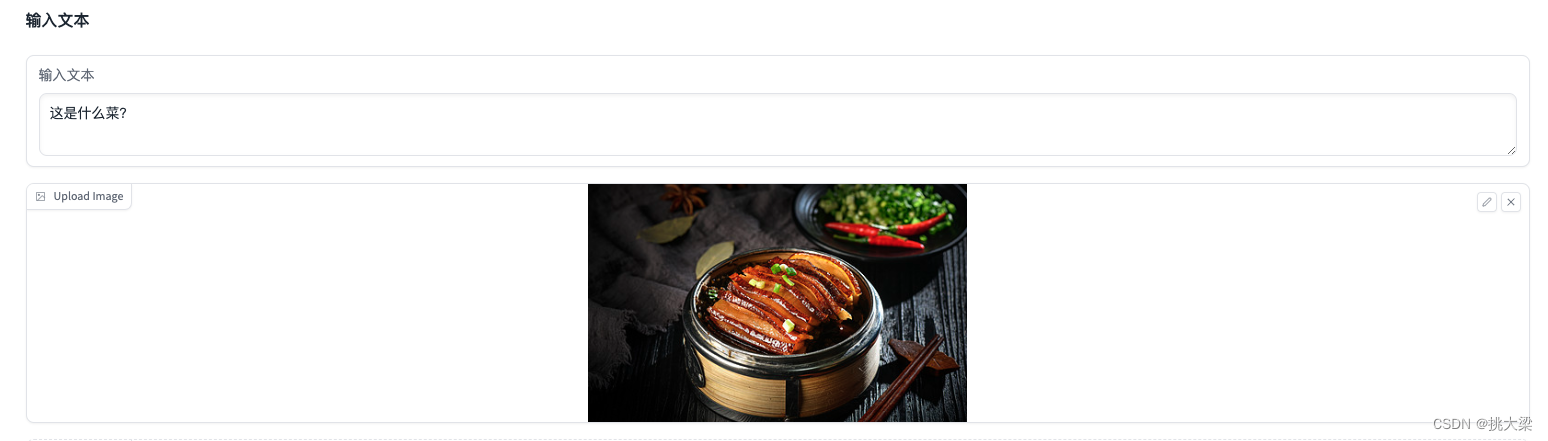
4 多模态大语言模型的应用
- 工业
- 医疗
- 视觉内容认知与编辑
- 具身智能
- 新一代人机交互


这篇关于十、多模态大语言模型(MLLM)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





